Training a multilingual model in Transkribus: Jeff Rusten
March 29, 2023
Uncategorized
The majority of Transkribus models are also trained to read just one language — after all, most historical documents are written in one language. But what if your document contains three (or even more) languages? Can you train a model to read all three at the same time?
The answer is yes, as Jeff Rusten and his team at Cornell University recently proved. Rusten’s research group have been working on a dictionary of all the words used by the ancient Greek comedic playwright, Aristophanes. The unpublished lexicon was put together in 1910 by Ernst Wüst, a German classicist, and is entirely in his handwriting. It is written in three different languages: ancient Greek, Latin, and Wüst’s native German.
As no public model currently exists for this language combination, Rusten’s team had to train their own multilingual model from scratch. We spoke to Rusten and his colleague, Ethan Della Rocca, about how they trained their multilingual model and used it to transcribe Wüst’s lexicon.
Aristophanes’ comedies from the fifth century BC became famous not just for their satirical perspective on life in ancient Athens, but also for their unusual linguistic style. “Aristophanes’ language is unique in classical Greek, combining high poetry and intellectual terminology with colloquialisms, terms from daily life, and even obscenities,” Rusten explained. “His lexical corpus was prized and studied already in antiquity.”
However, studying Aristophanes’ language in full requires having access to a comprehensive lexicon, detailing meanings, semantic relationships, and usage with key examples. “It was thought there was no adequate lexicon but in Cornell’s library we found a collection from 1984 of microfiche images of Ernst Wüst’s unpublished manuscript.” For the uninitiated, a microfiche is a small piece of photographic film containing images of pages of written material. Before digitisation, they were used to store materials, such as newspapers, without taking up too much physical space in an archive. In the 1980s, there was a push to use microfiches to ensure that manuscripts on decaying paper would be preserved forever.
One of those manuscripts was Wüst’s lexicon to Aristophanes from ca. 1910. “The publisher K G Saur decided to preserve the lexicon, without which it might have been lost forever, as the original manuscript has not been located to date. The publication had never been reviewed or even mentioned by any subsequent scholar, probably because accessing it was too daunting in the 1980s, not to mention reading it.”
Of course, the best way to truly preserve Wüst’s lexicon is to create a digital version of it, to allow scholars to quickly search through the manuscript’s 1500 pages and also provide additional information about the individual entries. “A digital version can link each word with its basic meaning, word family, semantics and distribution in the author’s works, as well as a complete list of all occurrences, sorted by work and hyperlinked to the passage that is their context.”
Rusten’s team had already created an online platform, Lexeis.org, making it possible to publish digital versions of lexicons in this way. “We have already done this for Thucydides and Plato, and now Aristophanes. Adding Wüst’s digitized lexicon will greatly improve the platform.”
This wasn’t the first time the team had used technology to try and speed up the transcription process. “We had already tried a modern Greek OCR package but ancient Greek has many more accents and other diacritics, which are difficult for OCR platforms to distinguish. We had also used Tesseract to transcribe Ast’s Plato lexicon (which is also in ancient Greek, Latin, and German) but we only had limited success.”
With Wüst’s lexicon, the team came across Transkribus quite by chance. “We discovered the platform while searching for information about the German “Kurrent” script. Then we attended a five-hour training workshop held at Yale by Sara Mansutti, which showed that Transkribus had many clear advantages over other methods.”
“Firstly, it deals with handwritten scripts as well as print. It also provides a computing platform for training transcription models for specific scripts and hands, based on neural networks. We liked that the methods are clearly explained and accessible to non-specialists, with videos of past workshops and instructional web pages. Finally, it makes past users’ models available for use in transcriptions and re-training by new users. This saves a lot of time when creating models.”
Once they had decided to use Transkribus, the next challenge for the team was to create digital scans of the 1500 microfiches of Wüst’s lexicon. “Today there are high-quality microfiche digital scanning readers available. With the help of Cornell Library equipment and staff, and after much trial and error, we were able to produce acceptable jpeg images (detailed enough to zoom in on, but still under Transkribus’ 10MB limit) of all 1500 pages in just over four weeks.”
Armed with their digital scans, the team then selected 50 of the pages to transcribe manually as Ground Truth. Della Rocca explained their strategy. “We aimed to include pages with different structures, including both short entries with much space between each entry and extended entries with little space between the lines. One of the main considerations was getting good coverage of the different letters when placed in the starting position of the line, as it makes identifying each article and its respective lemma much easier.”
“We also selected pages representative of the varying degrees of marginalia present in the text, although we excluded marginalia too faint to discern—maybe someday we will locate the original manuscript!”
The manual transcription of the 50 selected pages was carried out partly by student workers at the university, who had skills in ancient Greek and Latin but not always in German. Rusten recalled: “The initial problem for us as Americans was the unfamiliarity with the German Kurrent script. We used the German Handwriting M1 model to produce an initial transcription of the pages we were working on. It did a good job with the German, but misrecognized the Latin and Greek as German also.”
“This meant we had to manually transcribe the parts that had been misrecognized. Using the images we loaded in Transkribus’ collaborative online workspace, our student workers had to locate and transcribe the script or language they knew best for each page, starting with Greek from scratch, then Latin also from scratch, and finally correcting the automatically transcribed German. Once a student had transcribed everything they could, they turned the page over to the next transcriber.”
“Because we had different people focus on different scripts, rather than force everyone to try to do every script, the transcription took five of us just six weeks of full-time work.”
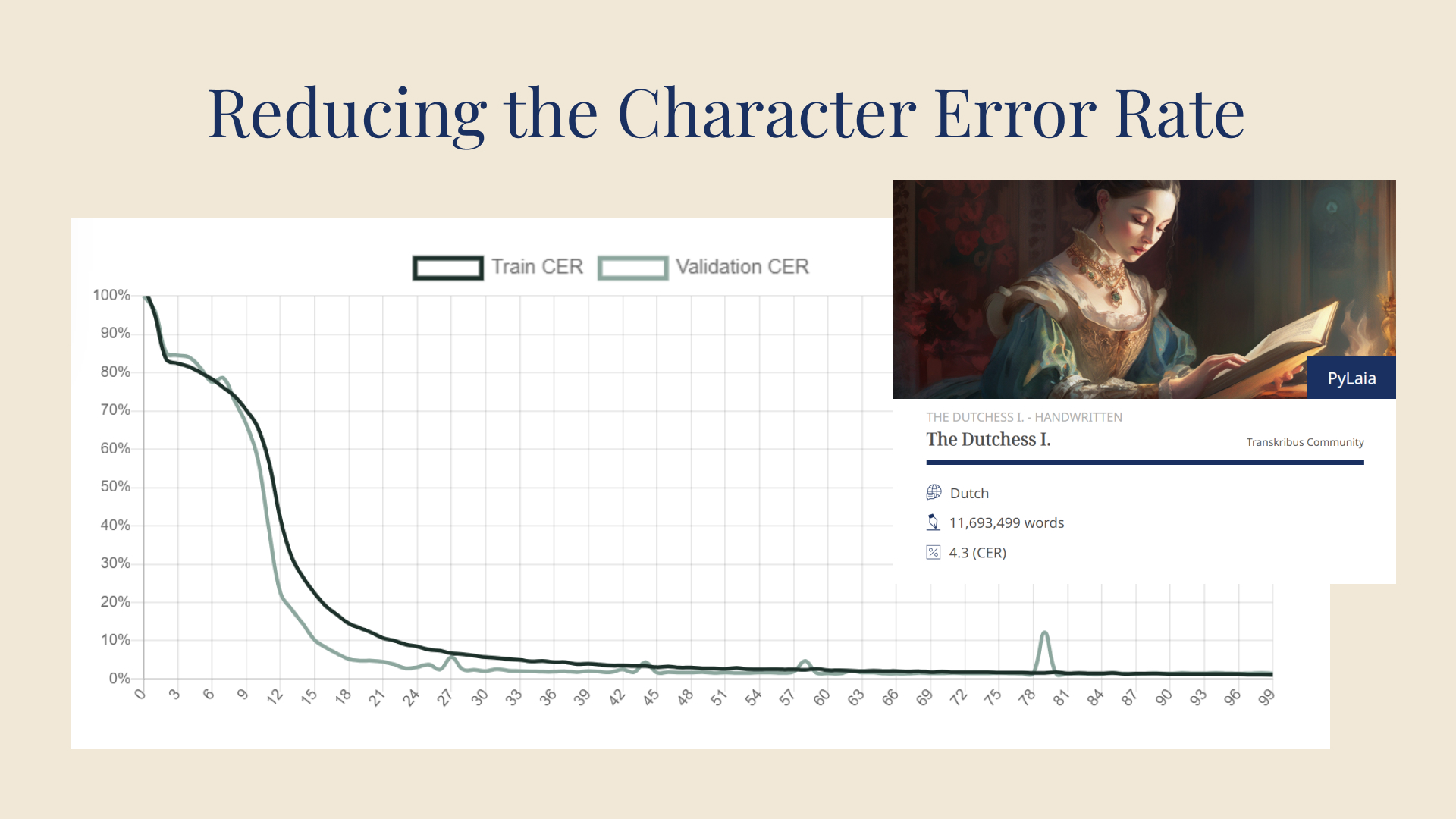
Della Rocca supervised the final stage. “After several tries at optimizing the model, our lowest character error rate (CER) is 7.21%. This is approximately a 36% reduction from our initial model’s CER of 11.20%, and we are trying to improve it further by running more training and experimenting with different configurations. This has greatly reduced our post-transcription correction time per page.”
At the moment, the team is preparing the lexicon for publication on Lexeis.org. “The transcription still needs to be tagged in XML format for correction and analysis and linked to our XML text of Aristophanes. Then we can upload it to the platform. So the work is only just now becoming known but the support from granting agencies has been gratifying, and we look forward to publicizing it among scholars as soon as it is corrected and documented.”
The team are very happy with the way the project has turned out. “We only wish we had found Transkribus earlier! Henceforth we will use it for all of our OCR work, including print. We are currently re-transcribing a text which we had previously processed, to use the Transkribus model’s much more accurate Greek to correct our existing version.”
Della Rocca has some advice for other research groups wanting to train a multilingual model. “Stay calm if the initial training attempt fails — simply try other configurations. When first training your model, experiment with using different base models, as you’ll find that some may be more helpful than others. Then, once you have a working model, keep refining it with more transcribed and corrected pages to make it as accurate as possible.” We couldn’t agree more!
Thank you to Jeff and Ethan for talking to us about the project, and we wish you all the best with Lexeis.org.
Spring has sprung and so has the April 2024 release of Transkribus. Here is a quick overview of all the ...
🍪 Some cookies for you 🍪
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.