One of the biggest advantages of Transkribus is the possibility to train custom handwritten text recognition models. This unique feature allows you to tailor the automatic transcriptions to the specific handwriting or printed text in your documents, resulting in more accurate transcriptions.
However, training accurate models is a skill that takes a bit of time to master. If you are new to model training, you may quickly become frustrated at the high Character Error Rate, or CER, of your model. This is a number between 0% and 100% which shows how accurate the model is. A model with a CER of 100% will produce a very inaccurate transcription whereas a model with a CER of 0% will give a perfect, error-free transcription.
In general, you should aim for a CER of 10% or less. This will produce transcriptions that are accurate enough for search purposes and further analysis. But if your model’s CER is higher than that, don’t despair — there are plenty of easy ways to bring down the CER and create a model that is a good fit for your documents. Let’s take a look at the five easiest ways to improve the CER of your model.
The CER is shown for each model, along with the language and script. Image via Transkribus.
What is the CER?
Before we start, let’s take a quick look at what the CER is. The CER is the percentage of characters that were transcribed incorrectly by the text recognition model during testing. If a model has a CER of 5%, this means that, compared to manual transcription, 5 out of 100 characters were incorrectly transcribed by the model — a relatively low number.
But how is the CER calculated? When you create a model, you have to provide two sets of accurate, manually transcribed pages: the training set, which is used to train the model; and the validation set, which usually contains a selection of pages from the training set and is used to test the model. This training data is also known as Ground Truth.
During training, the model analyses all the pages in the training set and tries to learn the handwriting. It then tests what it has learned by attempting an automatic transcription of the pages in the validation set. The model’s automatic transcription of the pages is compared against the accurate manual transcription, and the number of errors is calculated. This is then turned into a percentage and you have your CER.
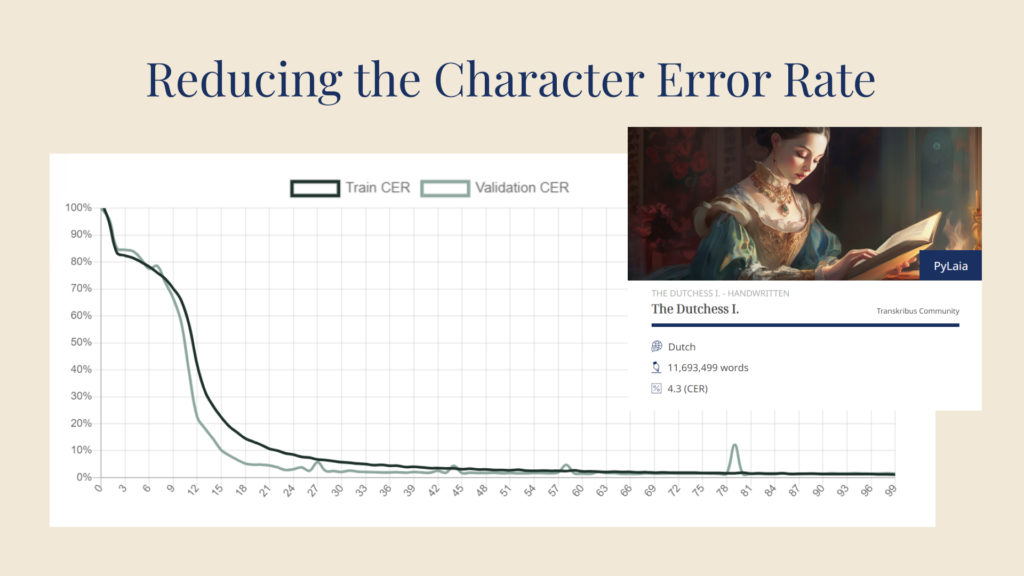
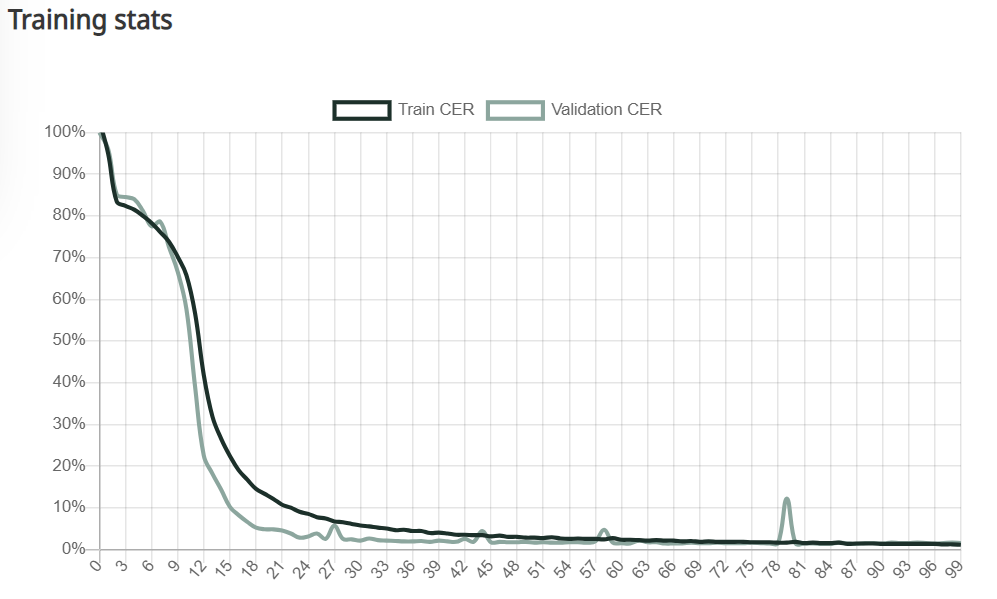
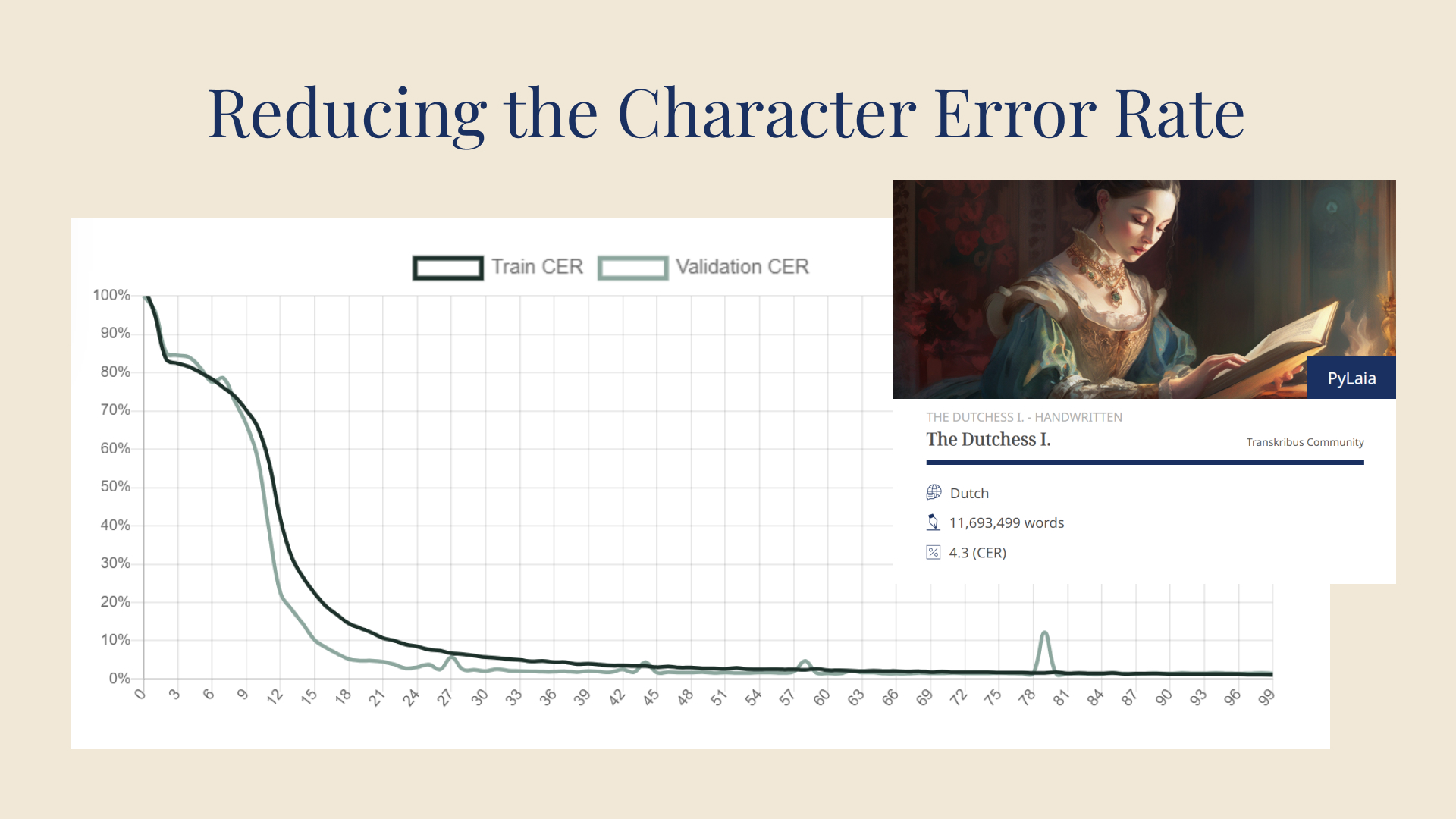
The more epochs (shown on the x axis) that are performed , the lower the CER (shown on the y axis) becomes. Image via Transkribus.
The first time your model goes through this process — known as an epoch — you can expect your CER to be quite high. However, the model will then perform many more epochs, learning more and more each time and making fewer and fewer errors when testing itself on the validation set. Over time, the model will have learned all it can and each epoch will result in the same CER. This figure is taken as the CER of your model.
One other thing…
Keep in mind, that the CER calculates every tiny discrepancy from the training data as errors, including spaces, punctuation, and lower case instead of upper case. It could be that your model has a high CER, but that most of the errors do not concern the actual letters and that the transcriptions are actually quite accurate. Therefore, it is always worth testing the model on a few pages after training, because even a model with a higher CER might still give you a searchable text suitable for your purposes.
Five ways to improve the CER of your model
If your model has completed many training epochs and you are still receiving quite a high CER and inaccurate transcriptions, here are five things you can do to improve the accuracy of your model.
1. Make sure your training data is accurate.
Your training data is the manually transcribed pages you provide for your training set and validation set. They should be 100% accurate and completely error-free.
This is important because the model is only as accurate as the training data it has been given. If there are mistakes in that training data, then those mistakes will be replicated in anything the model tries to transcribe. If you are receiving very high CERs, then it’s worth going through your training data and checking that it is as accurate as possible.
The more accurate your training data is, the more accurate your model will be. Image from NAF Court Records, via Transkribus
2. Make sure your training data is consistent.
Likewise, your training data should be consistent. This is particularly relevant if your documents contain abbreviations, unusual punctuation, or other “non-standard” language elements. If these sorts of elements are inconsistently transcribed in the training data, then you risk confusing the model, resulting in a higher CER.
Visit our Help Center for more information about consistency with your training data.
Being consistent with transcription conventions teaches your model to transcribe in the same way. Image from Marjory Fleming’s Diary, via Transkribus
3. Don’t forget about baselines.
While it’s easy to focus on just the text part of the transcription, don’t forget about the layout. Before each text recognition, Transkribus performs a layout analysis. This enables the platform to pinpoint the location of the text on the page, so that it knows what to transcribe during the text recognition stage.
It’s therefore important that the baselines (the coloured lines under each line of text) are accurately shown in your training data. That way, the model will only try to find characters in places where they actually exist, creating more accurate transcriptions. You can find out how to adjust baselines in our Help Center.
Accurate baselines ensure that the model correctly learns where the text is on the page. Image from “Bulliot, Bibracte et moi” project, via Transkribus
4. Keep adding more data.
If you’ve gone through your training data and you are sure the text and baselines are entirely accurate and consistent, then the next step would be to add more training data.
In general, we recommend having at least 25 pages of training data for a model. But of course, the more training data you have, the more information your model has to learn from and the more accurate it will be.
This is particularly true if your documents are very heterogeneous, for example, if they have many different types of handwriting. In these cases, more training data may be required to bring down the CER of the model.
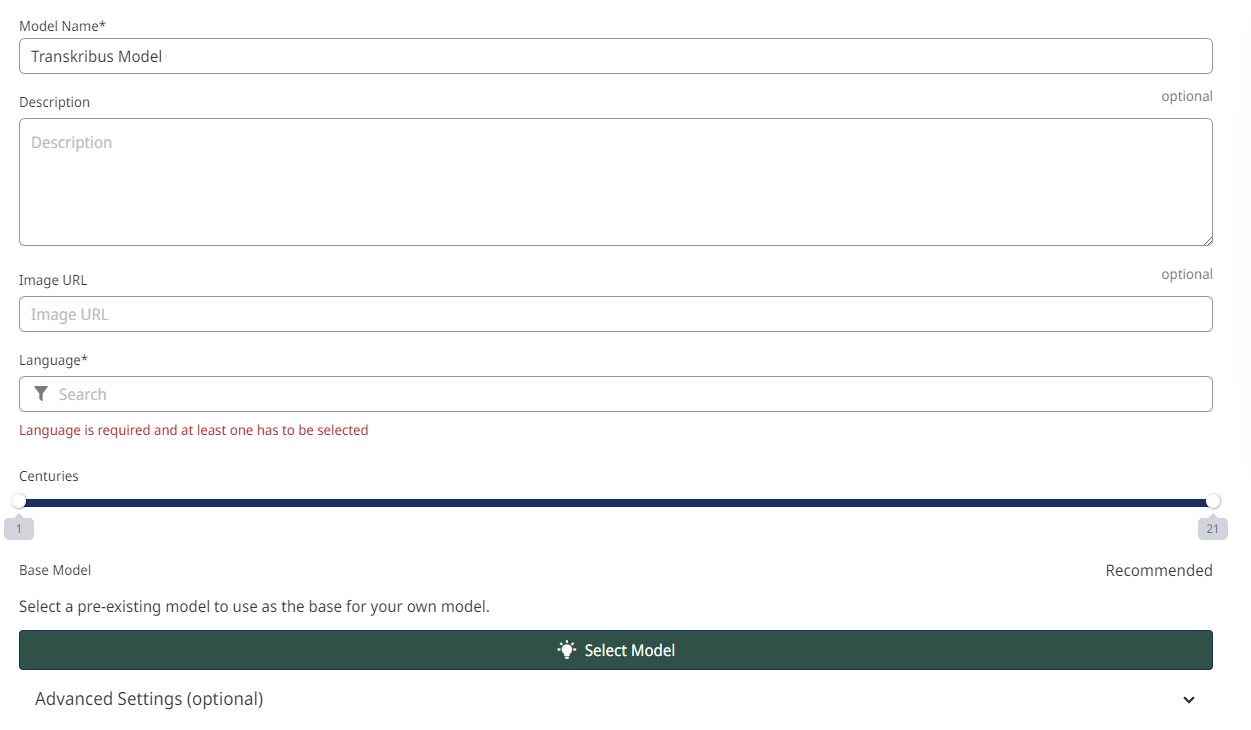
Selecting a base model means your new model doesn’t have to be trained from scratch. Image via Transkribus.
5. Use a base model.
This last tip can not only improve the CER of your model, but save time too. When setting up your new model, you have the option to select a “base model”. This is a pre-existing model which will be used as a base for your new custom model. Your base model should be trained on a similar language, handwriting and time period as your documents.
Using a base model means that your new model does not need to be trained entirely from scratch. Instead, it can use the information stored in the base model and expand on it with your training data. This usually results in a more accurate model with less training data required, saving you both time and effort.
Need more information about training text recognition models with Transkribus? Check out the Training Models section in our Help Center.
Spring has sprung and so has the April 2024 release of Transkribus. Here is a quick overview of all the ...
🍪 Some cookies for you 🍪
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.