Training eines mehrsprachigen Modells in Transkribus: Jeff Rusten
März 29, 2023
Uncategorized
Die meisten Transkribus-Modelle sind auch darauf trainiert, nur eine Sprache zu lesen - schließlich sind die meisten historischen Dokumente in einer Sprache verfasst. Was aber, wenn Ihr Dokument drei (oder sogar mehr) Sprachen enthält? Kann man ein Modell darauf trainieren, alle drei gleichzeitig zu lesen?
Die Antwort ist ja, wie Jeff Rusten und sein Team an der Cornell University kürzlich bewiesen haben. Rustens Forschungsgruppe hat an einem Wörterbuch aller Wörter gearbeitet, die der antike griechische Komödiendichter Aristophanes verwendet hat. Das unveröffentlichte Lexikon wurde 1910 von Ernst Wüst, einem deutschen Klassizisten, zusammengestellt und ist vollständig in seiner Handschrift verfasst. Es ist in drei verschiedenen Sprachen verfasst: Altgriechisch, Latein und Wüsts Muttersprache Deutsch.
Da es derzeit kein öffentliches Modell für diese Sprachkombination gibt, musste das Team von Rusten sein eigenes mehrsprachiges Modell von Grund auf trainieren. Wir sprachen mit Rusten und seinem Kollegen Ethan Della Rocca darüber, wie sie ihr mehrsprachiges Modell trainierten und es zur Transkription des Wüst-Lexikons verwendeten.
Aristophanes' Komödien aus dem fünften Jahrhundert v. Chr. wurden nicht nur wegen ihrer satirischen Sicht auf das Leben im antiken Athen berühmt, sondern auch wegen ihres ungewöhnlichen Sprachstils. "Aristophanes' Sprache ist im klassischen Griechisch einzigartig, denn sie verbindet hohe Poesie und intellektuelle Terminologie mit Umgangssprache, Begriffen aus dem täglichen Leben und sogar Obszönitäten", erklärt Rusten. "Sein lexikalisches Korpus wurde schon in der Antike geschätzt und studiert."
Um die Sprache des Aristophanes vollständig studieren zu können, muss man jedoch Zugang zu einem umfassenden Lexikon haben, das die Bedeutungen, die semantischen Beziehungen und den Gebrauch mit Schlüsselbeispielen detailliert beschreibt. "Wir dachten, es gäbe kein adäquates Lexikon, aber in der Bibliothek von Cornell fanden wir eine Sammlung von Mikrofiche-Abbildungen des unveröffentlichten Manuskripts von Ernst Wüst aus dem Jahr 1984. Für Uneingeweihte: Ein Mikrofiche ist ein kleines Stück Fotofilm, das Abbildungen von Seiten mit schriftlichem Material enthält. Vor der Digitalisierung wurden sie verwendet, um Materialien wie Zeitungen aufzubewahren, ohne zu viel Platz in einem Archiv einzunehmen. In den 1980er Jahren gab es einen Vorstoß zur Verwendung von Mikrofiches, um sicherzustellen, dass Manuskripte auf verfallendem Papier für immer erhalten bleiben.
Eines dieser Manuskripte war Wüsts Lexikon zu Aristophanes aus der Zeit um 1910. "Der Verleger K. G. Saur beschloss, das Lexikon zu bewahren, da das Originalmanuskript bis heute nicht auffindbar ist und es sonst vielleicht für immer verloren gegangen wäre. Die Publikation wurde von keinem späteren Wissenschaftler je rezensiert oder auch nur erwähnt, wahrscheinlich weil der Zugang in den 1980er Jahren zu gewagt war, ganz zu schweigen vom Lesen."
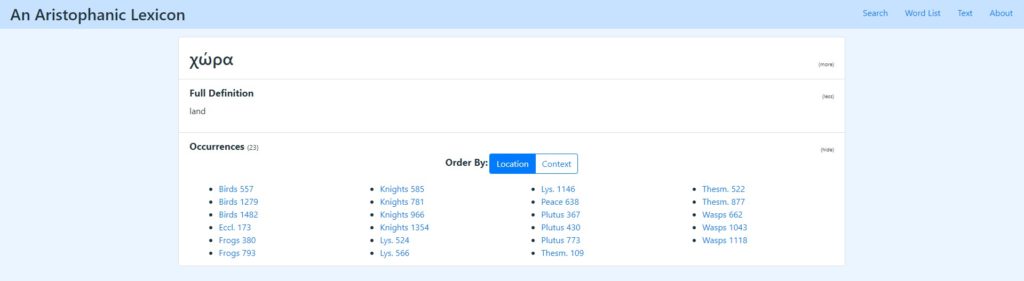
Der beste Weg, Wüsts Lexikon wirklich zu bewahren, ist natürlich die Erstellung einer digitalen Version, die es Wissenschaftlern ermöglicht, die 1500 Seiten des Manuskripts schnell zu durchsuchen und auch zusätzliche Informationen zu den einzelnen Einträgen bereitzustellen. "Eine digitale Version kann jedes Wort mit seiner Grundbedeutung, seiner Wortfamilie, seiner Semantik und seiner Verbreitung in den Werken des Autors verknüpfen, sowie eine vollständige Liste aller Vorkommen, sortiert nach Werk und mit einem Hyperlink zu der Passage, die ihren Kontext darstellt, bereitstellen."
Rustens Team hatte bereits eine Online-Plattform, Lexeis.org, geschaffen, die es ermöglicht, digitale Versionen von Lexika auf diese Weise zu veröffentlichen. "Wir haben dies bereits für Thukydides und Platon getan, und nun auch für Aristophanes. Das Hinzufügen des digitalisierten Lexikons von Wüst wird die Plattform erheblich verbessern."
Dies war nicht das erste Mal, dass das Team Technologien einsetzte, um den Transkriptionsprozess zu beschleunigen. "Wir hatten bereits ein OCR-Paket für Neugriechisch ausprobiert, aber Altgriechisch hat viel mehr Akzente und andere diakritische Zeichen, die für OCR-Plattformen schwer zu erkennen sind. Wir hatten auch Tesseract verwendet, um das Platon-Lexikon von Ast zu transkribieren (das auch in Altgriechisch, Latein und Deutsch vorliegt), aber wir hatten nur begrenzten Erfolg."
Mit dem Wüst-Lexikon stieß das Team eher zufällig auf Transkribus. "Wir haben die Plattform entdeckt, als wir nach Informationen über die deutsche Kurrentschrift suchten. Dann nahmen wir an einem fünfstündigen Trainingsworkshop von Sara Mansutti in Yale teil, der uns zeigte, dass Transkribus viele klare Vorteile gegenüber anderen Methoden hat."
"Erstens kann es sowohl handschriftliche als auch gedruckte Schriften verarbeiten. Außerdem bietet es eine Computerplattform für das Training von Transkriptionsmodellen für bestimmte Schriften und Hände, basierend auf neuronalen Netzen. Uns gefiel, dass die Methoden klar erklärt und auch für Nichtfachleute zugänglich sind, mit Videos von vergangenen Workshops und instruktiven Webseiten. Schließlich werden die Modelle früherer Nutzer für die Transkription und das erneute Training durch neue Nutzer zur Verfügung gestellt. Das spart eine Menge Zeit bei der Erstellung von Modellen".
Nachdem man sich für Transkribus entschieden hatte, bestand die nächste Herausforderung für das Team darin, digitale Scans der 1500 Mikrofiches des Wüst-Lexikons zu erstellen. "Heutzutage gibt es hochwertige digitale Lesegeräte für Mikrofiches. Mit Hilfe der Ausrüstung und des Personals der Cornell Library und nach vielen Versuchen und Fehlern waren wir in der Lage, in etwas mehr als vier Wochen akzeptable jpeg-Bilder (detailliert genug, um hineinzuzoomen, aber immer noch unter der 10-MB-Grenze von Transkribus) von allen 1500 Seiten zu erstellen."
Ausgestattet mit den digitalen Scans wählte das Team dann 50 Seiten aus, die es manuell als "Ground Truth" transkribierte. Della Rocca erläuterte ihre Strategie. "Wir wollten Seiten mit unterschiedlichen Strukturen aufnehmen, darunter sowohl kurze Einträge mit viel Platz zwischen den einzelnen Einträgen als auch längere Einträge mit wenig Platz zwischen den Zeilen. Eine der wichtigsten Überlegungen war es, eine gute Abdeckung der verschiedenen Buchstaben zu erhalten, wenn sie in der Anfangsposition der Zeile platziert sind, da dies die Identifizierung jedes Artikels und seines jeweiligen Lemmas wesentlich erleichtert."
"Wir haben auch Seiten ausgewählt, die repräsentativ für den unterschiedlichen Grad der Marginalien im Text sind, obwohl wir Marginalien ausgeschlossen haben, die zu schwach sind, um sie zu erkennen - vielleicht werden wir eines Tages das Originalmanuskript finden!"
Die manuelle Transkription der 50 ausgewählten Seiten wurde zum Teil von studentischen Mitarbeitern der Universität durchgeführt, die zwar Altgriechisch und Latein, aber nicht immer Deutsch beherrschten. Rusten erinnerte sich: "Das anfängliche Problem für uns Amerikaner war die Unvertrautheit mit der deutschen Kurrentschrift. Wir benutzten die Deutsche Handschrift M1 Modell, um eine erste Transkription der Seiten zu erstellen, an denen wir arbeiteten. Es hat die deutsche Sprache gut erkannt, aber das Lateinische und Griechische wurde ebenfalls als deutsch erkannt."
"Das bedeutete, dass wir die Teile, die falsch erkannt wurden, manuell transkribieren mussten. Anhand der Bilder, die wir in den kollaborativen Online-Arbeitsbereich von Transkribus geladen hatten, mussten unsere studentischen Mitarbeiter für jede Seite die Schrift oder Sprache finden und transkribieren, die sie am besten kannten, angefangen mit Griechisch von Grund auf, dann Latein, ebenfalls von Grund auf, und schließlich das automatisch transkribierte Deutsch korrigieren. Sobald ein Student alles transkribiert hatte, was er konnte, übergab er die Seite an den nächsten Transkribenten."
"Da wir verschiedene Leute auf verschiedene Drehbücher angesetzt haben, anstatt jeden zu zwingen, jedes Skript zu übernehmen, haben fünf von uns nur sechs Wochen Vollzeitarbeit für die Transkription gebraucht."
Della Rocca überwachte die letzte Phase. "Nach mehreren Versuchen, das Modell zu optimieren, liegt unsere niedrigste Zeichenfehlerrate (CER) bei 7,21%. Das ist eine Verringerung um etwa 36% gegenüber der CER unseres ursprünglichen Modells von 11,20%, und wir versuchen, sie weiter zu verbessern, indem wir mehr Training durchführen und mit verschiedenen Konfigurationen experimentieren. Dies hat unsere Korrekturzeit pro Seite nach der Transkription erheblich reduziert.
Zurzeit bereitet das Team das Lexikon für die Veröffentlichung auf Lexeis.org vor. "Die Transkription muss noch im XML-Format für Korrekturen und Analysen getaggt und mit unserem XML-Text von Aristophanes verknüpft werden. Dann können wir sie auf die Plattform hochladen. Die Arbeit wird also erst jetzt bekannt, aber die Unterstützung durch die Förderstellen ist erfreulich, und wir freuen uns darauf, sie unter den Wissenschaftlern zu veröffentlichen, sobald sie korrigiert und dokumentiert ist."
Das Team ist sehr zufrieden mit dem Verlauf des Projekts. "Wir wünschten nur, wir hätten Transkribus früher gefunden! Von nun an werden wir es für alle unsere OCR-Arbeiten verwenden, auch für den Druck. Wir sind gerade dabei, einen Text, den wir zuvor bearbeitet hatten, neu zu transkribieren, um das viel genauere Griechisch des Transkribus-Modells zur Korrektur unserer bestehenden Version zu nutzen."
Della Rocca hat einige Ratschläge für andere Forschungsgruppen, die ein mehrsprachiges Modell trainieren wollen. "Bleiben Sie ruhig, wenn der erste Trainingsversuch fehlschlägt - versuchen Sie einfach andere Konfigurationen. Wenn Sie Ihr Modell zum ersten Mal trainieren, experimentieren Sie mit verschiedenen Basismodellen, denn Sie werden feststellen, dass einige hilfreicher sind als andere. Wenn Sie dann ein funktionierendes Modell haben, verfeinern Sie es mit weiteren transkribierten und korrigierten Seiten, um es so genau wie möglich zu machen." Dem können wir nur zustimmen!
Wir bedanken uns bei Jeff und Ethan für das Gespräch über das Projekt und wünschen ihnen viel Erfolg mit Lexeis.org.
Einige Transkribus-Projekte enden mit einer vollständig digitalisierten Sammlung in Transkribus. Andere nehmen diese digitalisierte Quelle und verwenden sie ...
Wenn man an karolingische (oder karolingische) Minuskeln denkt, kommen einem wahrscheinlich Karl der Große und sein riesiges karolingisches Reich in den Sinn. Während die ...
Das Verstehen historischer Dokumente ist der Schlüssel zum Verständnis der Geschichte. Das Verstehen historischer Dokumente auf Polnisch kann jedoch eine Herausforderung sein. Nicht nur ...
🍪 Einige Cookies für Sie 🍪
Wir verwenden Cookies, um Inhalte und Dienste zu personalisieren und zu verbessern, relevante Werbung zu liefern und die Sicherheit unserer Nutzer zu erhöhen. Sie können Ihre Cookie-Einstellungen jederzeit überprüfen. Weitere Informationen über die Verwendung von Cookies und Cookie-Einstellungen finden Sie in unserem Privacy policy Cookie settingsRejectAccept
Datenschutz & Cookies-Richtlinie
Datenschutz Übersicht
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die als notwendig eingestuften Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der grundlegenden Funktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Ablehnen einiger dieser Cookies kann jedoch Auswirkungen auf Ihr Surferlebnis haben.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Kategorie umfasst nur Cookies, die grundlegende Funktionalitäten und Sicherheitsmerkmale der Website gewährleisten. Diese Cookies speichern keine persönlichen Informationen.
Cookie
Beschreibung
Dauer
viewed_cookie_policy
Das Cookie wird vom GDPR Cookie Consent Plugin gesetzt und dient dazu, zu speichern, ob der Benutzer der Verwendung von Cookies zugestimmt hat oder nicht. Es speichert keine persönlichen Daten.
1 Stunde
PHPSESSID
Dieses Cookie ist in PHP-Anwendungen enthalten. Der Cookie wird verwendet, um die eindeutige Sitzungs-ID eines Benutzers zu speichern und zu identifizieren, um die Benutzersitzung auf der Website zu verwalten. Das Cookie ist ein Sitzungscookie und wird gelöscht, wenn alle Browserfenster geschlossen werden.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Beschreibung
Dauer
BESUCHER_INFO1_LIVE
Dieses Cookie wird von Youtube gesetzt. Wird verwendet, um die Informationen der eingebetteten Youtube-Videos auf einer Website zu verfolgen.
5 Monate
IDE
Wird von Google DoubleClick verwendet und speichert Informationen darüber, wie der Nutzer die Website und andere Werbung vor dem Besuch der Website nutzt. Dies wird verwendet, um Nutzern Anzeigen zu präsentieren, die für sie entsprechend dem Nutzerprofil relevant sind.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Beschreibung
Dauer
GPS
Dieses Cookie wird von Youtube gesetzt und registriert eine eindeutige ID für die Nachverfolgung von Benutzern basierend auf ihrem geografischen Standort
30 Minuten
tk_oder
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
5 Jahre
tk_r3d
Das Cookie wird von JetPack installiert. Wird für die internen Metriken für Benutzeraktivitäten verwendet, um die Benutzererfahrung zu verbessern
3 Tage
tk_lr
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
1 Jahr
_ga
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Besucher-, Sitzungs- und Camapign-Daten zu berechnen und die Nutzung der Website für den Analysebericht der Website zu verfolgen. Die Cookies speichern Informationen anonym und weisen eine zufällig generierte Nummer zu, um eindeutige Besucher zu identifizieren.
2 Jahre
_gid
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Informationen darüber zu speichern, wie Besucher eine Website nutzen, und hilft bei der Erstellung eines Analyseberichts darüber, wie sich die Website verhält. Die gesammelten Daten umfassen die Anzahl der Besucher, die Quelle, von der sie kommen, und die besuchten Seiten in anonymer Form.
1 Tag
matomo
Für die statistische Analyse verwenden wir auf dieser Website "Matomo". Dies ist ein Open-Source-Tool für die Webanalyse. Matomo überträgt keine Daten an Server außerhalb der Kontrolle von READ-COOP. Matomo ist deaktiviert, wenn Sie unsere Website besuchen. Nur wenn Sie aktiv zustimmen, wird Ihr Nutzungsverhalten anonymisiert erfasst.
1 Jahr
Hubspot
Hubspot, Inc. 25 First Street, Cambridge, MA 02141 USA
HubSpot ist ein Dienst zur Verwaltung von Benutzerdatenbanken, der von HubSpot, Inc. bereitgestellt wird. Wir verwenden HubSpot auf dieser Website für unsere Online-Kundensupport-Aktivitäten.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Beschreibung
Dauer
YSC
Dieses Cookie wird von Youtube gesetzt und dient dazu, die Aufrufe von eingebetteten Videos zu verfolgen.
1 Jahr
_gat
Dieses Cookie wird von Google Universal Analytics installiert, um die Abfragerate zu drosseln und so die Datensammlung auf stark frequentierten Seiten zu begrenzen.