Legal history is a research field that focuses on the evolution of legal systems, and the reasons behind the implementation of different laws. Luckily for legal historians, law is also a field that is known for its thorough documentation. That means there is a wealth of legal documentation available for researchers, stretching back several hundred years.
However, accessing this (mostly paper) documentation isn’t always easy. Firstly, documentation is often housed across several archives in different locations, and a researcher must travel personally to the archive in order to view the documents. Even the documents that have already been digitised are spread out across the internet and often hidden behind paywalls.
At the University of Zurich , a group of researchers decided it was time to rectify this problem. Prof. Dr. Walter Boente — chair for private law at the university — and his team decided to produce a digital corpus of legal texts and publish it online using the read&search platform. By doing so, they have created one of the largest digital collections of historical legal documents available on the internet.
Transcribing the documents
Of course, digitising every document out there in one go would be a rather large project, particularly as the team had not embarked on a project of this type before. Instead, they decided to begin with a few smaller sample collections, such as papers written by lawyers of historical importance or documents concerning a particular law.
The starting point was to bring documents stored digitally in other archives and libraries over to the new platform. In addition, many documents needed to be digitised for the first time, and the team was lucky to have the support of many institutions, who prepared their documents ready for use with Transkribus.
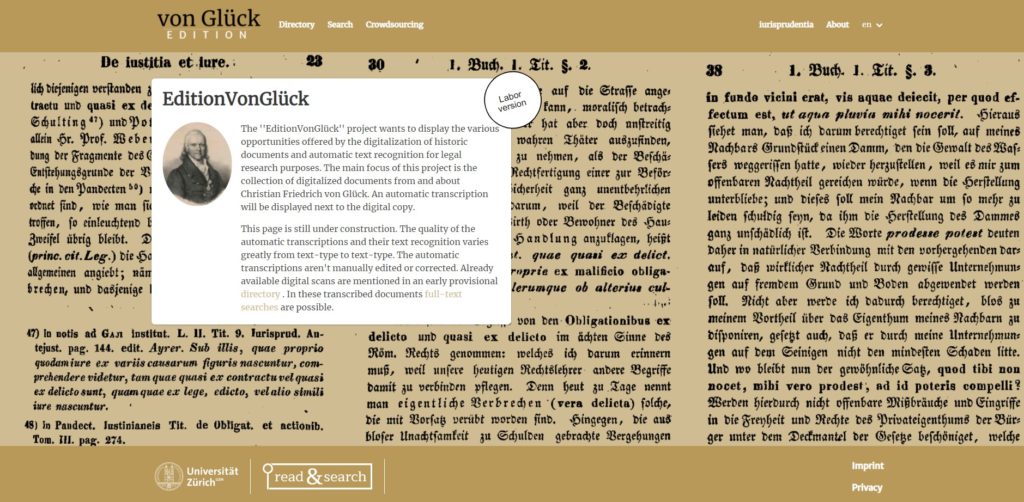
Once the documents were accessible on Iurisprudentia, they were then transcribed using the Transkribus platform. The team started by using the public models offered by Transkribus to automatically transcribe the historical documents. But with the help of the crowd, more and more documents were transcribed or corrected manually. Using the resulting Ground Truth, the team retrained the general models and thereby adopted them to the needs of the project.
Example of an Edition that is made accessible thanks to the iurisprudentia project
Making the collections accessible
Another key goal for the Iurisprudentia team was accessibility. After all, it was the lack of access to legal historical documents that prompted the team to start the project in the first place. The aim was to have all the transcribed documents available in one place, without a pay wall, and for users to be able to quickly search entire collections for specific information.
After looking at several options, the team decided to use the read&search platform to publish the corpus. Their main reason was the ease of use that read&search offered. Documents can be uploaded straight from Transkribus, as well as any tags and metadata that have been implemented. The team therefore could rely on the infrastructure set up centrally by READ-COOP. For the Iursprudentia team, this remains one of the biggest benefits.
“The read&search platform is an all-round carefree package,” Professor Boente explained. “Every few weeks I see new tools popping up that seem to offer better solutions than read&search. That is sometimes very tempting. Nevertheless, it would take a lot of investment and further development to be able to use these tools productively.”
A journey through time with the iurisprudentia web application
An ever-expanding corpus
The Iurisprudentia platform currently stores 22 different collections of documents, spanning hundreds of years of legal history. Although the platform was originally intended just for documents concerning Swiss, German and Austrian law, several international collections have now been launched. The first of these, a Polish-language collection on civil law, has already been added and there are other collaborations in the pipeline.
It has been several years since the project began, but Professor Boente is still very happy with their decision to use read&search for the project. “To date, I have not found a better offer than read&search. My advice is therefore to concentrate on the content of your project. If, contrary to expectations, you find something better in the future, you can continue to use all of your data stored with read&search—without converting it. It doesn’t get any more sustainable than that!”
Overview
Project Title / Name: Universität Zürich
Institution: Lehrstuhls für Privatrecht mit Schwerpunkt ZGB, Universität Zürich
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.