Introducing Field Models – Trainable Layout AI in Transkribus
July 26, 2023
News, Transkribus
If you have ever processed historical documents with complex layouts in Transkribus, you will know that these types of documents can be a real challenge when it comes to layout recognition. This is why we are introducing the trainable Field Models in Transkribus, a new and improved way of working with different layouts in historical documents.
In this article we will explain why we are introducing this new way of recognising layouts, discuss the benefits of the trainable layout models and explain the types of documents with which the field model can be used.
The Power of Field Models
When working with documents that have a tricky or complex layout, it is essential to recognise and capture the structure as well as the content. The challenge is not just to mark up complicated layouts on a handful of individual pages, but to extend this task to a larger volume of pages. Historical documents such as newspapers, periodicals, log books, registries, legal records, forms and many other types of documents often have these complicated layouts throughout the entire collection.
To address this concern, we’re introducing Field Models, an innovative technology for layout recognition in Transkribus. This new addition is set to increase efficiency and ensure accurate interpretation of even the most intricate layouts by allowing you to train your own custom models.
About Field Models
It is important to note that Field Models are not an all-in-one or out-of-the-box solution. To achieve optimal results, the models need to be trained similarly to a text recognition model. Using the default layout recognition may not always produce satisfying results. The upcoming trainable layout models will be a more customisable technology that can be trained to accurately recognise even complex layouts and detect layout elements on a large scale. These models will be especially useful for documents containing forms or multiple text regions. The trainable layout models will enable you to achieve a more accurate representation of the documents, making it easier to further transcribe and analyse historical documents.
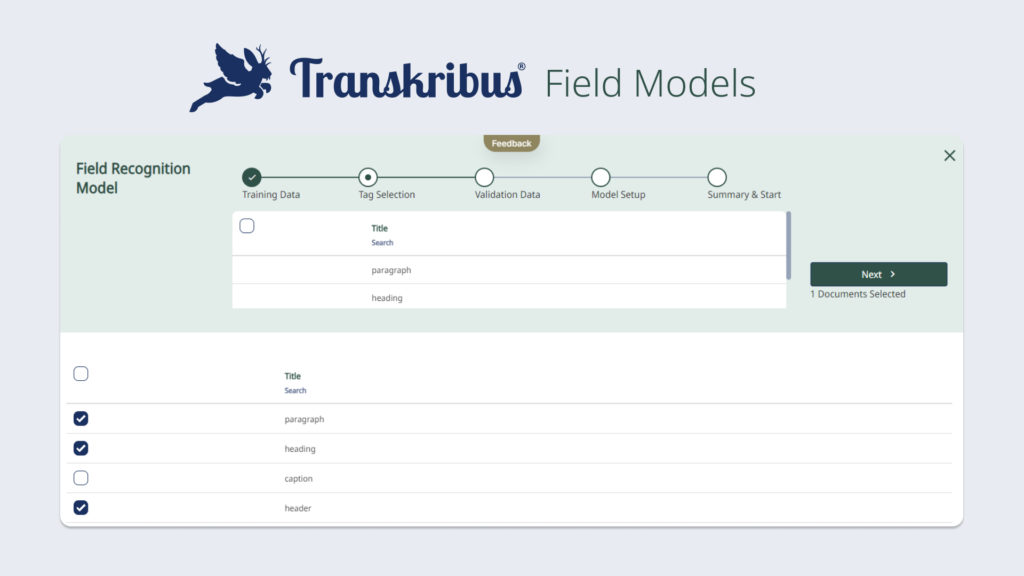
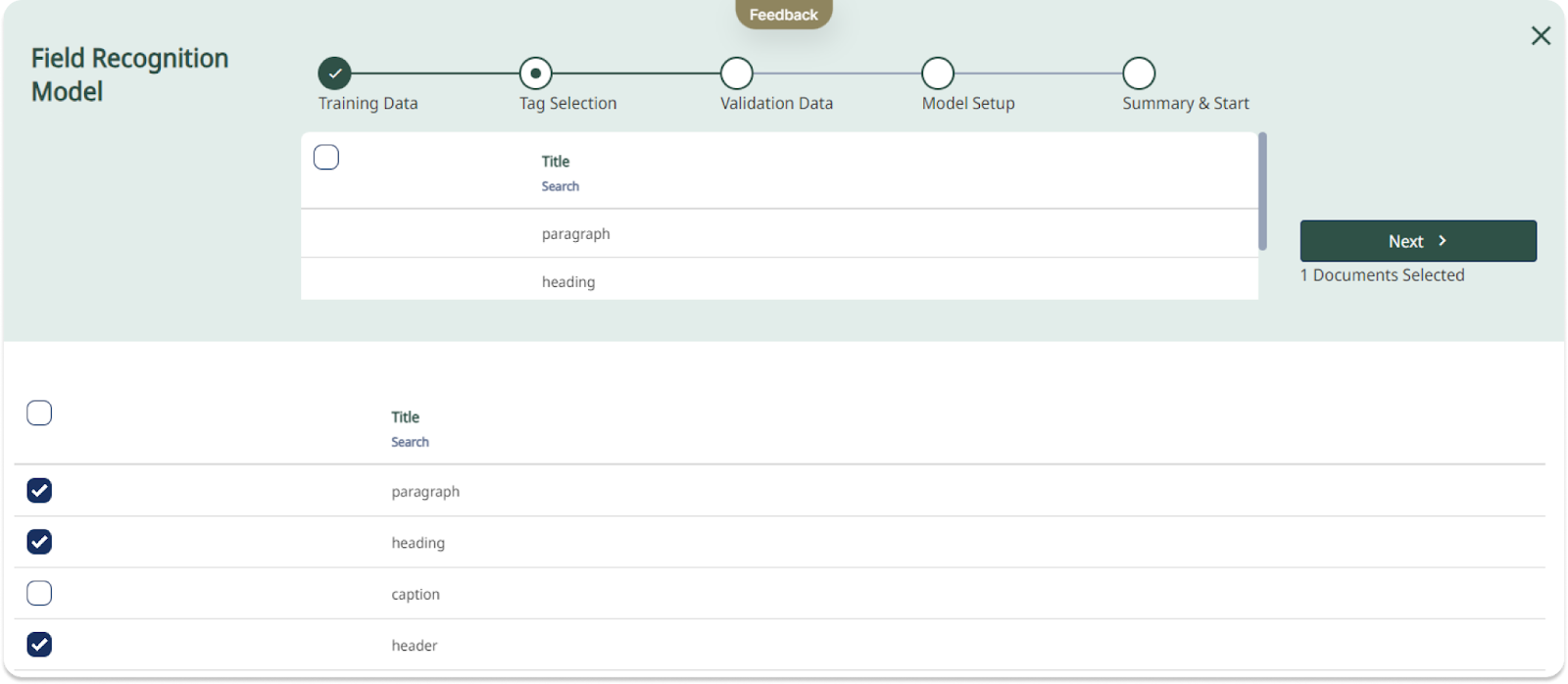
A Field Recognition Model can be trained to recognise and transcribe layout.
Benefit of Field Models
Now what does the introduction of Field Models mean for you, the users? Until now, the process of transcribing documents with complex layouts has taken quite a long time. Manually drawing text regions on each page and adjusting them to fit the subtle layout differences within a collection is a time-consuming task. With trainable layout recognition, however, Transkribus can be trained to recognise and transcribe complex layout automatically.
In contrast to the currently available P2PaLA Models, Field Models require less training data while being more precise. The new Field models are designed to be effectively trained with a limited amount of training material, streamlining the process. This approach has the potential to reduce the amount of time spent creating or adjusting regions or marking different layout elements on each page. Instead, users can focus on generating the correct layout shapes to train the model, allowing Transkribus to handle the rest.
You can already try out Field Models on a small dataset, here on beta.transkribus.eu
Which Document Types Do Field Models Support?
Having discussed the why and how of the model and the ways it will benefit our users, let’s take a closer look at the types of documents and layouts that can be processed better with this feature. Field Models will cover a large number of layout cases and can be used to find text regions, with newspapers and for form segmentation.
Text Regions
When dealing with complex document layouts such as newspapers, periodicals or registries, it is important to understand the concept of text regions. A text region is a distinct area within a document that contains specific textual content. It could be an article body, a headline, an advertisement or a caption, each of which represents unique information.
These text regions become essential training material for our new Field Models. By manually segmenting these regions and creating a collection of ground truth pages, we create a basic guide. This guide serves as a reference point for the Field Models to accuratly recognise and categorise similar regions of text in other documents. As a result, our digitisation efforts become more accurate and comprehensive, which is especially valuable when navigating the intricate layouts typical in historical newspapers.
Example of newspaper layout with overlapping text regions.
Newspapers
One prime candidate for the application of the Field Models within the trainable layout is historical newspapers. Newspapers, with their distinct layout complexities, have long been a cornerstone of information distribution, dating back centuries. They are often divided into multiple columns, intricate header sections, and interspersed images, advertisements or illustrations — a layout that can be challenging to digitise accurately.
Previously, the process of converting newspapers to digital format relied on printed block detection. While useful, this method was not always precise, especially when it came to labelling overlapping regions, which are not uncommon in newspaper layouts. Overlapping regions can be caused by such things as the continuation of articles across columns or pages, or densely packed advertisements.
In contrast, the newly introduced trainable Field Models bring a more sophisticated approach to dealing with these complexities. They have the ability to recognise and accurately label even overlapping regions, which proves to be a great advantage when dealing with the multifaceted layouts of newspapers.
To effectively apply a customised Field Model to newspapers, you first need to prepare your Ground Truth pages. This preparation involves accurately identifying and labelling the various regions within the newspaper layout. Once you have created these labelled ground truth pages, you can then proceed to train the model, ensuring that it is prepared to handle the layout specifics of newspapers. This method promises greater accuracy and, in turn, a more effective and reliable digitisation process.
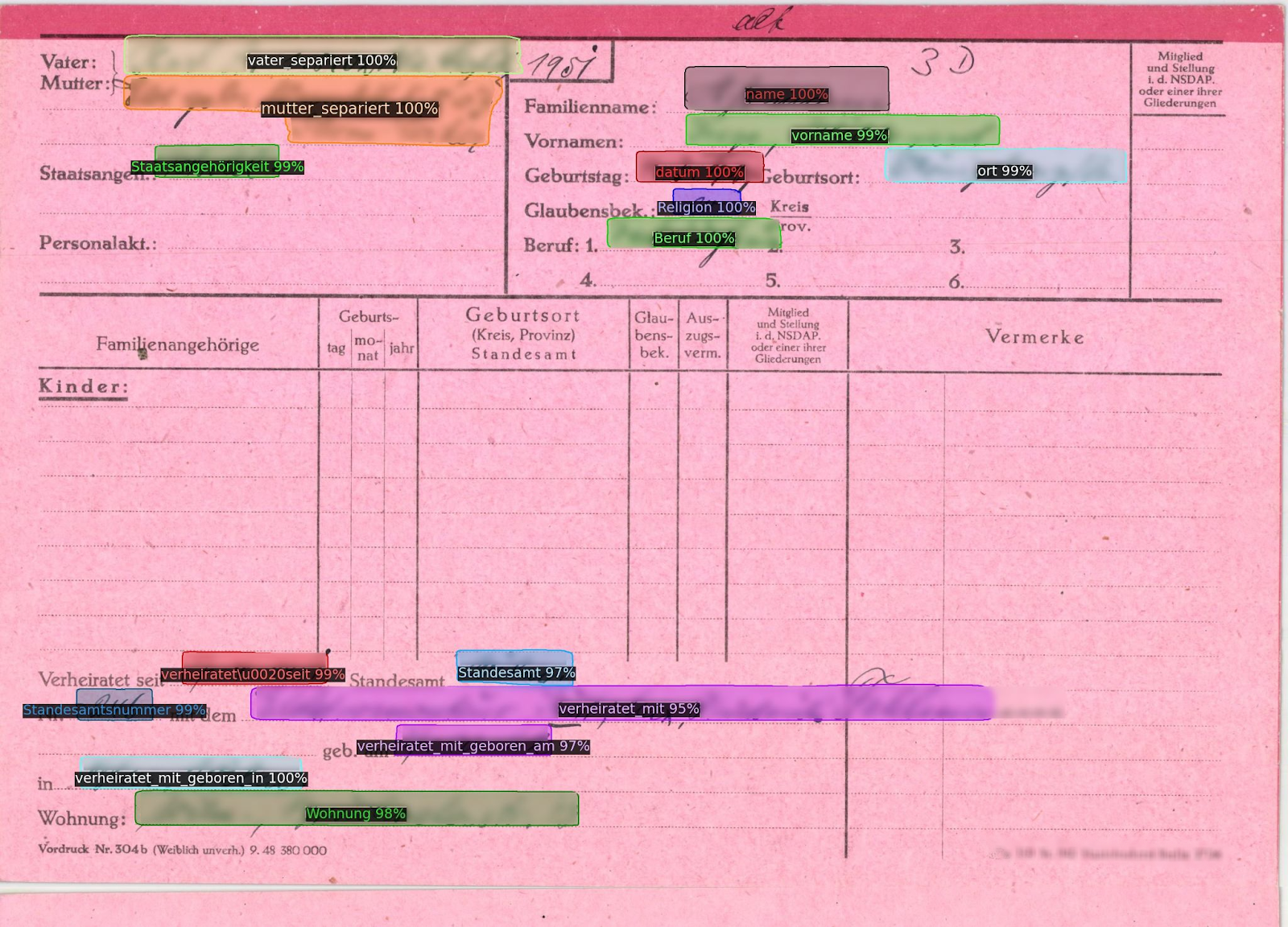
Example of a historical form with multiple tags.
Forms
Historical forms are another type of document that can greatly benefit from the use of Field Models. These forms, be they census records, military enlistment forms or immigration documents, have played a crucial role throughout history in recording key information about individuals and populations.
However, when digitising these forms, it is often the case that only the entered and filled-in data is of interest. For instance, in an immigration form, the actual names, birth dates, and places of origin are the information needed, rather than the repetitive fields like ‘Surname’ or ‘Date of Birth’.
To focus on this relevant data, users can create text regions specifically around the filled-in information and simply assign them appropriate labels or tags, such as ‘Surname’, ‘Name’, ‘Date of Birth’. The trained Field Models can then recognise these labels and apply the right layout to the remaining pages of the collection automatically, extracting just the essential data. This offers a much more streamlined and focused approach to digitising historical forms, saving time and making sure that only the required information is extracted.
What’s Next?
The current version of the trainable field models does present some challenges, particularly with non-rectangular objects, text wraps and unusually thin or long objects. However, we do not view these as setbacks, but as avenues for future improvement. Our focus is to address the limitations of the current layout recognition and to improve the new layout models by extending their use to different document formats and layout types.
We are therefore pleased to announce that in the coming weeks we will also be introducing our newly developed trainable Table Models, designed specifically for the digitisation of historical document tables. The Table Models offer flexibility in customising recognition and can adapt to layout changes, ensuring accurate interpretation and comprehensive data extraction, even from tables with irregular formats.
As for the new Transkribus Field Models, within the next few weeks they will be added to our user interface for general use. On a small set of pages, you can already try out the trainable field model here on beta.transkribus.eu. This update will enable every user to train their own layout model for fields, democratising the process of document digitisation and unlocking even more potential within our platform.
Understanding historical documents is key to understanding history. But understanding historical documents in Polish can be a challenge. Not only ...
🍪 Some cookies for you 🍪
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.