Einführung von Feldmodellen - Trainierbare Layout-KI in Transkribus
Juli 26, 2023
News, Transkribus
Wer schon einmal historische Dokumente mit komplexen Layouts in Transkribus bearbeitet hat, weiß, dass diese Art von Dokumenten eine echte Herausforderung für die Layouterkennung darstellen kann. Aus diesem Grund führen wir mit den trainierbaren Feldmodellen in Transkribus eine neue und verbesserte Möglichkeit ein, mit unterschiedlichen Layouts in historischen Dokumenten zu arbeiten.
In diesem Artikel erläutern wir, warum wir diese neue Art der Erkennung von Layouts einführen, diskutieren die Vorteile der trainierbaren Layout-Modelle und erläutern die Arten von Dokumenten, mit denen das Feldmodell verwendet werden kann.
Die Macht der Feldmodelle
Bei der Arbeit mit Dokumenten, die ein kompliziertes oder komplexes Layout aufweisen, ist es wichtig, neben dem Inhalt auch die Struktur zu erkennen und zu erfassen. Die Herausforderung besteht nicht nur darin, komplizierte Layouts auf einer Handvoll einzelner Seiten zu markieren, sondern diese Aufgabe auf ein größeres Volumen von Seiten auszuweiten. Historische Dokumente wie Zeitungen, Zeitschriften, Logbücher, Register, Gerichtsakten, Formulare und viele andere Arten von Dokumenten weisen oft diese komplizierten Layouts in der gesamten Sammlung auf.
Um diesem Problem zu begegnen, führen wir Field Models ein, eine innovative Technologie zur Layout-Erkennung in Transkribus. Diese neue Ergänzung soll die Effizienz steigern und eine genaue Interpretation selbst der kompliziertesten Layouts gewährleisten, indem sie es Ihnen ermöglicht, Ihre eigenen benutzerdefinierten Modelle zu trainieren.
Über Field Models
Es ist wichtig zu beachten, dass Field Models keine All-in-One-Lösung sind. Um optimale Ergebnisse zu erzielen, müssen die Modelle ähnlich wie ein Texterkennungsmodell trainiert werden. Die Verwendung der Standard-Layouterkennung führt nicht immer zu zufriedenstellenden Ergebnissen. Die kommenden trainierbaren Layout-Modelle werden eine besser anpassbare Technologie sein, die so trainiert werden kann, dass sie selbst komplexe Layouts genau erkennt und Layout-Elemente in großem Umfang aufspürt. Diese Modelle werden insbesondere für Dokumente nützlich sein, die Formulare oder mehrere Textbereiche enthalten. Die trainierbaren Layout-Modelle werden Ihnen eine genauere Darstellung der Dokumente ermöglichen, was die weitere Transkription und Analyse historischer Dokumente erleichtert.
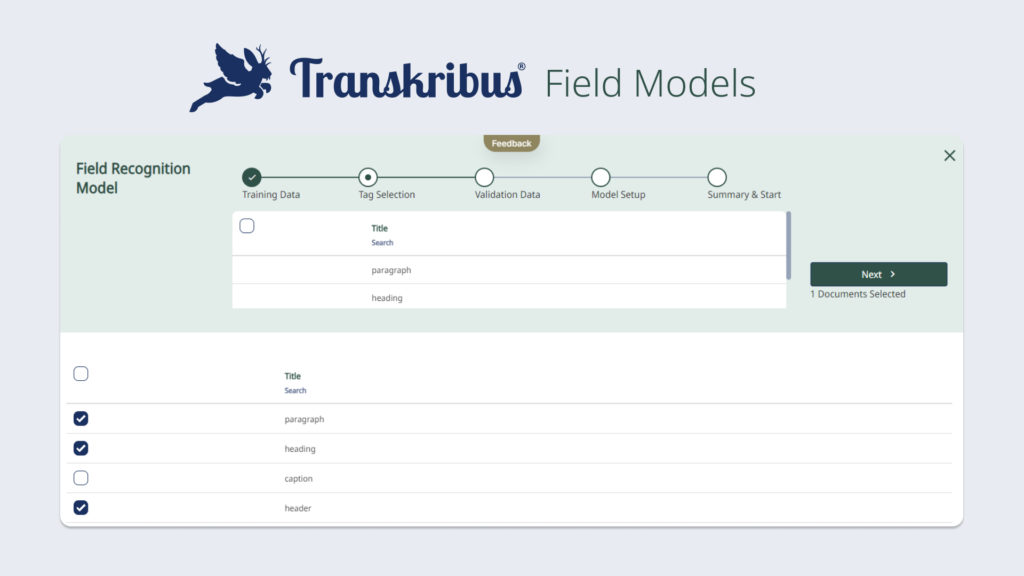
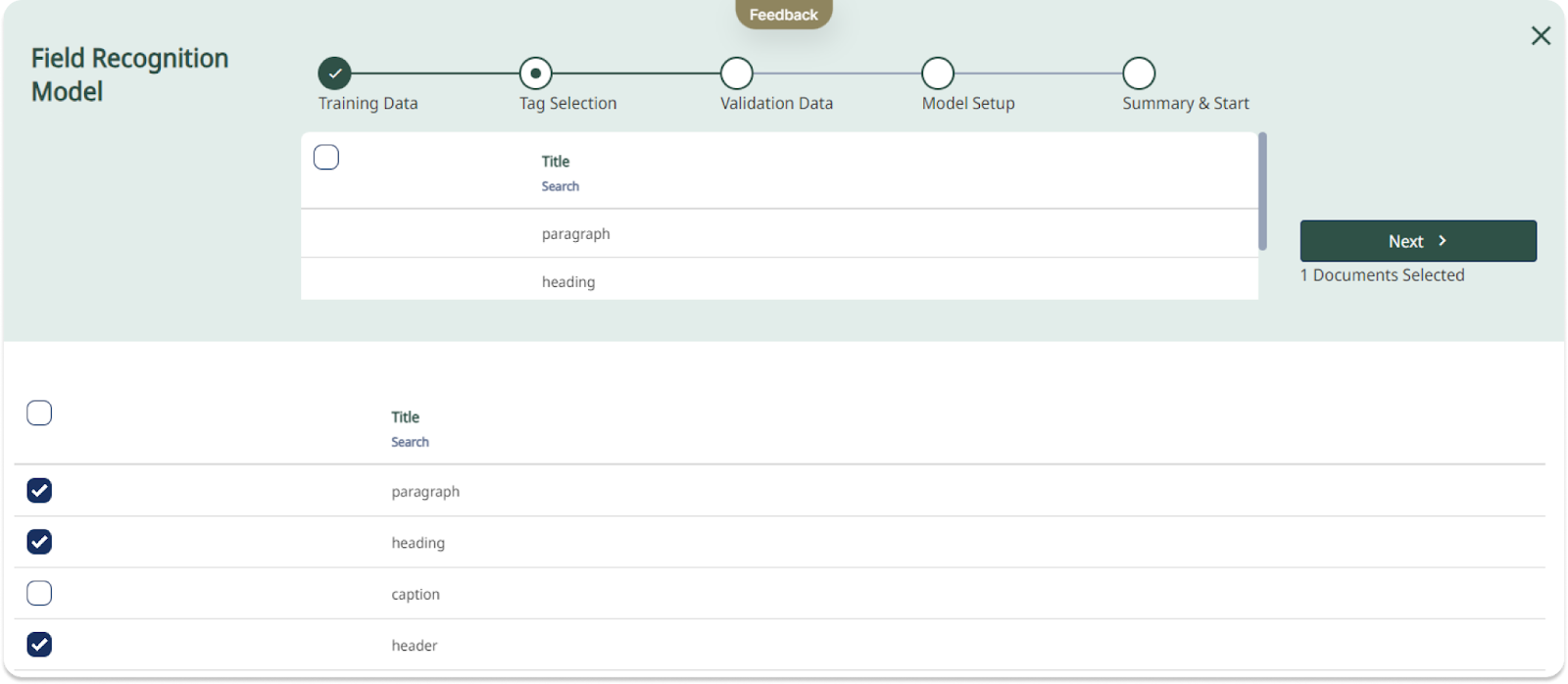
Ein Field Recognition Model kann für die Erkennung und Transkription von Layouts trainiert werden.
Nutzen von Feldmodellen
Was bedeutet nun die Einführung von Feldmodellen für Sie, die Benutzer? Bislang hat die Transkription von Dokumenten mit komplexem Layout sehr viel Zeit in Anspruch genommen. Manuelles Zeichnen von Textbereichen auf jeder Seite und deren Anpassung an die feinen Layoutunterschiede innerhalb einer Sammlung ist eine zeitraubende Aufgabe. Mit der trainierbaren Layout-Erkennung kann Transkribus jedoch darauf trainiert werden, komplexe Layouts automatisch zu erkennen und zu transkribieren.
Im Gegensatz zu den derzeit verfügbaren P2PaLA-Modellen benötigen die Field-Modelle weniger Trainingsdaten und sind gleichzeitig präziser. Die neuen Field-Modelle sind so konzipiert, dass sie mit einer begrenzten Menge an Trainingsmaterial effektiv trainiert werden können, wodurch der Prozess rationalisiert wird. Dieser Ansatz hat das Potenzial, den Zeitaufwand für die Erstellung oder Anpassung von Regionen oder die Markierung verschiedener Layoutelemente auf jeder Seite zu reduzieren. Stattdessen können sich die Anwender darauf konzentrieren, die richtigen Layoutformen zu erzeugen, um das Modell zu trainieren, und Transkribus den Rest überlassen.
Sie können Field Models bereits an einem kleinen Datensatz ausprobieren, hier auf beta.transkribus.eu
Welche Dokumenttypen werden von Feldmodellen unterstützt?
Nachdem wir das Warum und Wie des Modells und die Vorteile für unsere Benutzer erörtert haben, wollen wir nun einen genaueren Blick auf die Arten von Dokumenten und Layouts werfen, die mit dieser Funktion besser verarbeitet werden können. Feldmodelle decken eine große Anzahl von Layoutfällen ab und können zum Auffinden von Textbereichen, bei Zeitungen und zur Formularsegmentierung verwendet werden.
Text-Regionen
Beim Umgang mit komplexen Dokumentenlayouts wie Zeitungen, Zeitschriften oder Registern ist es wichtig, das Konzept der Textbereiche zu verstehen. Ein Textbereich ist ein bestimmter Bereich innerhalb eines Dokuments, der einen bestimmten Textinhalt enthält. Dabei kann es sich um einen Artikeltext, eine Überschrift, eine Anzeige oder eine Bildunterschrift handeln, die jeweils eindeutige Informationen darstellen.
Diese Textregionen werden zum wesentlichen Trainingsmaterial für unsere neuen Feldmodelle. Durch die manuelle Segmentierung dieser Regionen und die Erstellung einer Sammlung von Referenzseiten erstellen wir einen grundlegenden Leitfaden. Dieser Leitfaden dient den Feldmodellen als Referenzpunkt, um ähnliche Textregionen in anderen Dokumenten genau zu erkennen und zu kategorisieren. Dadurch werden unsere Digitalisierungsbemühungen genauer und umfassender, was besonders wertvoll ist, wenn man sich in den komplizierten Layouts historischer Zeitungen zurechtfindet.
Beispiel für ein Zeitungslayout mit überlappenden Textbereichen.
News-Papiere
Ein Hauptkandidat für die Anwendung der Feldmodelle innerhalb des trainierbaren Layouts sind historische Zeitungen. NewsZeitungen mit ihrer ausgeprägten Layout-Komplexität sind seit Jahrhunderten ein Eckpfeiler der Informationsverbreitung. Sie sind oft in mehrere Spalten unterteilt, haben komplizierte Kopfzeilen und eingestreute Bilder, Anzeigen oder Illustrationen - ein Layout, dessen genaue Digitalisierung eine Herausforderung darstellen kann.
Bisher beruhte die Konvertierung von Zeitungen in ein digitales Format auf der Erkennung gedruckter Blöcke. Diese Methode war zwar nützlich, aber nicht immer präzise, insbesondere wenn es um die Kennzeichnung sich überlappender Bereiche ging, die in Zeitungslayouts nicht selten sind. Überlappende Bereiche können z. B. durch die Fortsetzung von Artikeln über Spalten oder Seiten hinweg oder durch dicht gedrängte Anzeigen verursacht werden.
Im Gegensatz dazu bieten die neu eingeführten trainierbaren Feldmodelle einen ausgefeilteren Ansatz zur Bewältigung dieser Komplexität. Sie sind in der Lage, auch sich überschneidende Regionen zu erkennen und genau zu beschriften, was sich als großer Vorteil beim Umgang mit den vielfältigen Layouts von Zeitungen erweist.
Um ein individuelles Feldmodell effektiv auf Zeitungen anzuwenden, müssen Sie zunächst Ihre Ground Truth-Seiten vorbereiten. Diese Vorbereitung umfasst die genaue Identifizierung und Kennzeichnung der verschiedenen Regionen innerhalb des Zeitungslayouts. Sobald Sie diese beschrifteten Ground-Truth-Seiten erstellt haben, können Sie mit dem Training des Modells fortfahren, um sicherzustellen, dass es auf die Layout-Spezifika von Zeitungen vorbereitet ist. Diese Methode verspricht eine höhere Genauigkeit und damit einen effektiveren und zuverlässigeren Digitalisierungsprozess.
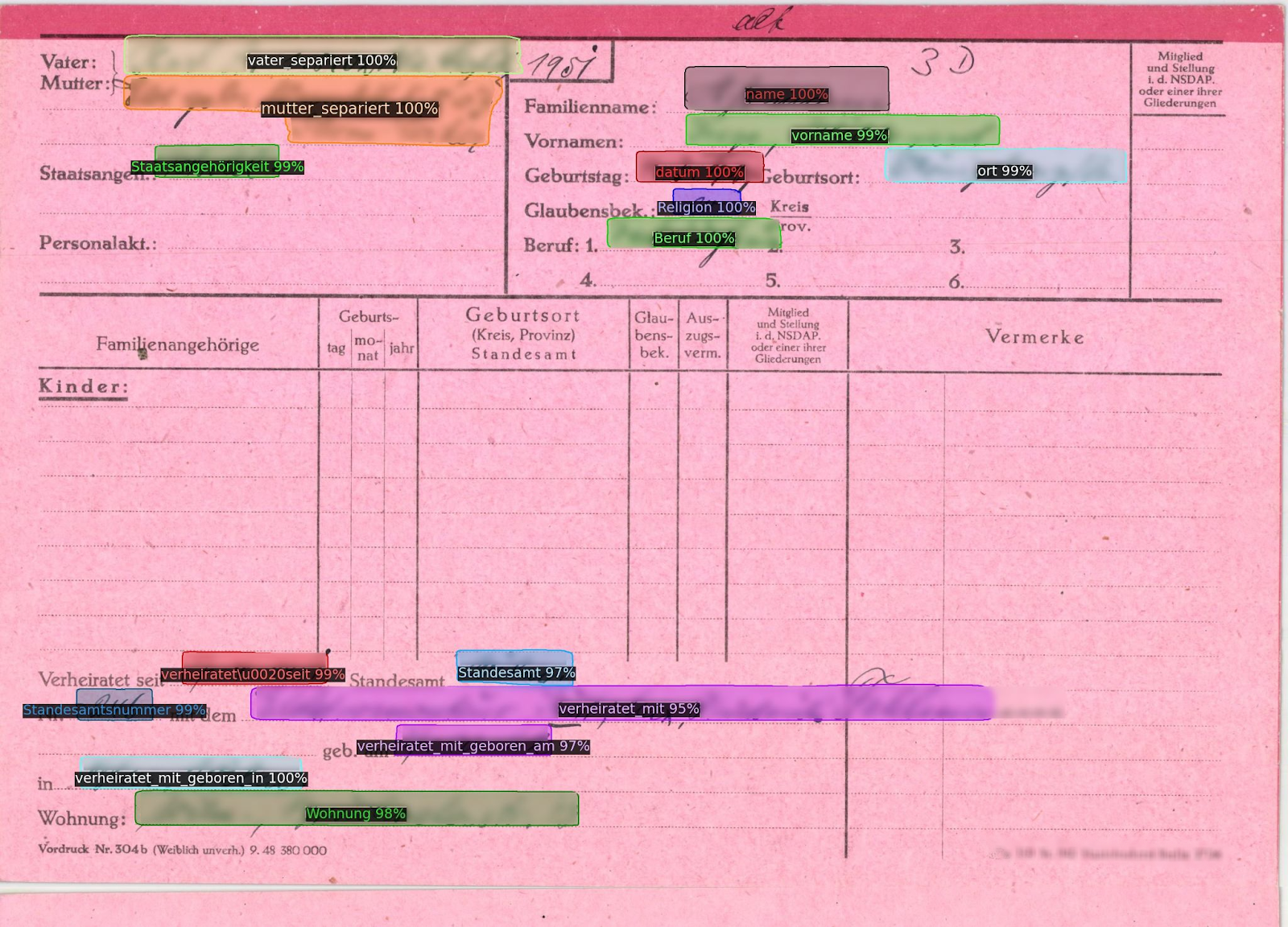
Beispiel für ein historisches Formular mit mehreren Tags.
Formulare
Historische Formulare sind eine weitere Art von Dokumenten, die von der Verwendung von Field Models stark profitieren können. Diese Formulare, seien es Volkszählungsaufzeichnungen, militärische Einberufungsformulare oder Einwanderungsdokumente, haben im Laufe der Geschichte eine entscheidende Rolle bei der Aufzeichnung wichtiger Informationen über Personen und Bevölkerungsgruppen gespielt.
Bei der Digitalisierung dieser Formulare sind jedoch oft nur die eingegebenen und ausgefüllten Daten von Interesse. Bei einem Einwanderungsformular beispielsweise sind die tatsächlichen Namen, Geburtsdaten und Herkunftsorte die benötigten Informationen und nicht die sich wiederholenden Felder wie "Nachname" oder "Geburtsdatum".
Um sich auf diese relevanten Daten zu konzentrieren, können die Benutzer Textbereiche speziell um die ausgefüllten Informationen herum erstellen und ihnen einfach entsprechende Bezeichnungen oder Tags zuweisen, z. B. "Nachname", "Name", "Geburtsdatum". Die geschulten Feldmodelle können dann diese Bezeichnungen erkennen und automatisch das richtige Layout auf die übrigen Seiten der Sammlung anwenden, um nur die wesentlichen Daten zu extrahieren. Dies bietet einen wesentlich effizienteren und gezielteren Ansatz für die Digitalisierung historischer Formulare, spart Zeit und stellt sicher, dass nur die erforderlichen Informationen extrahiert werden.
Was kommt als Nächstes?
Die aktuelle Version der trainierbaren Feldmodelle stellt einige Herausforderungen dar, insbesondere bei nicht rechteckigen Objekten, Textumbrüchen und ungewöhnlich dünnen oder langen Objekten. Wir betrachten diese jedoch nicht als Rückschläge, sondern als Möglichkeiten für zukünftige Verbesserungen. Unser Ziel ist es, die Grenzen der aktuellen Layout-Erkennung zu überwinden und die neuen Layout-Modelle zu verbessern, indem wir ihre Anwendung auf verschiedene Dokumentenformate und Layout-Typen ausweiten.
Wir freuen uns daher, Ihnen mitteilen zu können, dass wir in den kommenden Wochen auch unsere neu entwickelten trainierbaren Tabellenmodelle vorstellen werden, die speziell für die Digitalisierung historischer Dokumententabellen entwickelt wurden. Die Tabellenmodelle bieten Flexibilität bei der Anpassung der Erkennung und können sich an Layout-Änderungen anpassen, was eine genaue Interpretation und umfassende Datenextraktion auch aus Tabellen mit unregelmäßigen Formaten gewährleistet.
Die neuen Transkribus-Feldmodelle werden in den nächsten Wochen in unsere Benutzeroberfläche für die allgemeine Nutzung aufgenommen. Auf einer kleinen Anzahl von Seiten können Sie das trainierbare Feldmodell bereits hier ausprobieren beta.transkribus.eu. Dieses Update ermöglicht es jedem Nutzer, sein eigenes Layoutmodell für Felder zu trainieren, den Prozess der Dokumentendigitalisierung zu demokratisieren und noch mehr Potenzial innerhalb unserer Plattform freizusetzen.
Einer der größten Vorteile von Transkribus ist die Möglichkeit, benutzerdefinierte Modelle zur Erkennung von handschriftlichem Text zu trainieren. Diese einzigartige Funktion ...
🍪 Einige Cookies für Sie 🍪
Wir verwenden Cookies, um Inhalte und Dienste zu personalisieren und zu verbessern, relevante Werbung zu liefern und die Sicherheit unserer Nutzer zu erhöhen. Sie können Ihre Cookie-Einstellungen jederzeit überprüfen. Weitere Informationen über die Verwendung von Cookies und Cookie-Einstellungen finden Sie in unserem Privacy policy Cookie settingsRejectAccept
Datenschutz & Cookies-Richtlinie
Datenschutz Übersicht
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die als notwendig eingestuften Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der grundlegenden Funktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Ablehnen einiger dieser Cookies kann jedoch Auswirkungen auf Ihr Surferlebnis haben.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Kategorie umfasst nur Cookies, die grundlegende Funktionalitäten und Sicherheitsmerkmale der Website gewährleisten. Diese Cookies speichern keine persönlichen Informationen.
Cookie
Beschreibung
Dauer
viewed_cookie_policy
Das Cookie wird vom GDPR Cookie Consent Plugin gesetzt und dient dazu, zu speichern, ob der Benutzer der Verwendung von Cookies zugestimmt hat oder nicht. Es speichert keine persönlichen Daten.
1 Stunde
PHPSESSID
Dieses Cookie ist in PHP-Anwendungen enthalten. Der Cookie wird verwendet, um die eindeutige Sitzungs-ID eines Benutzers zu speichern und zu identifizieren, um die Benutzersitzung auf der Website zu verwalten. Das Cookie ist ein Sitzungscookie und wird gelöscht, wenn alle Browserfenster geschlossen werden.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Beschreibung
Dauer
BESUCHER_INFO1_LIVE
Dieses Cookie wird von Youtube gesetzt. Wird verwendet, um die Informationen der eingebetteten Youtube-Videos auf einer Website zu verfolgen.
5 Monate
IDE
Wird von Google DoubleClick verwendet und speichert Informationen darüber, wie der Nutzer die Website und andere Werbung vor dem Besuch der Website nutzt. Dies wird verwendet, um Nutzern Anzeigen zu präsentieren, die für sie entsprechend dem Nutzerprofil relevant sind.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Beschreibung
Dauer
GPS
Dieses Cookie wird von Youtube gesetzt und registriert eine eindeutige ID für die Nachverfolgung von Benutzern basierend auf ihrem geografischen Standort
30 Minuten
tk_oder
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
5 Jahre
tk_r3d
Das Cookie wird von JetPack installiert. Wird für die internen Metriken für Benutzeraktivitäten verwendet, um die Benutzererfahrung zu verbessern
3 Tage
tk_lr
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
1 Jahr
_ga
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Besucher-, Sitzungs- und Camapign-Daten zu berechnen und die Nutzung der Website für den Analysebericht der Website zu verfolgen. Die Cookies speichern Informationen anonym und weisen eine zufällig generierte Nummer zu, um eindeutige Besucher zu identifizieren.
2 Jahre
_gid
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Informationen darüber zu speichern, wie Besucher eine Website nutzen, und hilft bei der Erstellung eines Analyseberichts darüber, wie sich die Website verhält. Die gesammelten Daten umfassen die Anzahl der Besucher, die Quelle, von der sie kommen, und die besuchten Seiten in anonymer Form.
1 Tag
matomo
Für die statistische Analyse verwenden wir auf dieser Website "Matomo". Dies ist ein Open-Source-Tool für die Webanalyse. Matomo überträgt keine Daten an Server außerhalb der Kontrolle von READ-COOP. Matomo ist deaktiviert, wenn Sie unsere Website besuchen. Nur wenn Sie aktiv zustimmen, wird Ihr Nutzungsverhalten anonymisiert erfasst.
1 Jahr
Hubspot
Hubspot, Inc. 25 First Street, Cambridge, MA 02141 USA
HubSpot ist ein Dienst zur Verwaltung von Benutzerdatenbanken, der von HubSpot, Inc. bereitgestellt wird. Wir verwenden HubSpot auf dieser Website für unsere Online-Kundensupport-Aktivitäten.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Beschreibung
Dauer
YSC
Dieses Cookie wird von Youtube gesetzt und dient dazu, die Aufrufe von eingebetteten Videos zu verfolgen.
1 Jahr
_gat
Dieses Cookie wird von Google Universal Analytics installiert, um die Abfragerate zu drosseln und so die Datensammlung auf stark frequentierten Seiten zu begrenzen.