Introduzione ai modelli di campo - IA addestrabile per i layout in Transkribus
26 luglio 2023
News, Transkribus
Se avete mai elaborato documenti storici con layout complessi in Transkribus, saprete che questo tipo di documenti può rappresentare una vera e propria sfida per il riconoscimento dei layout. Per questo motivo stiamo introducendo in Transkribus i Modelli di campo addestrabili, un modo nuovo e migliorato di lavorare con i diversi layout dei documenti storici.
In questo articolo spiegheremo perché stiamo introducendo questo nuovo modo di riconoscere i layout, discuteremo i vantaggi dei modelli di layout addestrabili e illustreremo i tipi di documenti con cui il modello di campo può essere utilizzato.
Il potere dei modelli di campo
Quando si lavora con documenti dal layout complicato o complesso, è essenziale riconoscere e catturare la struttura e il contenuto. La sfida non è solo quella di marcare layout complicati su una manciata di singole pagine, ma di estendere questo compito a un volume più ampio di pagine. Documenti storici come giornali, periodici, libri di bordo, registri, atti legali, moduli e molti altri tipi di documenti presentano spesso questi layout complicati nell'intera raccolta.
Per risolvere questo problema, stiamo introducendo in Transkribus i Field Models, una tecnologia innovativa per il riconoscimento dei layout. Questa novità è destinata ad aumentare l'efficienza e a garantire un'interpretazione accurata anche dei layout più intricati, consentendo di formare i propri modelli personalizzati.
Informazioni sui modelli di campo
È importante notare che i modelli di campo non sono una soluzione completa o pronta all'uso. Per ottenere risultati ottimali, i modelli devono essere addestrati in modo simile a un modello di riconoscimento del testo. L'utilizzo del riconoscimento predefinito del layout potrebbe non produrre sempre risultati soddisfacenti. I prossimi modelli di layout addestrabili saranno una tecnologia più personalizzabile che potrà essere addestrata per riconoscere accuratamente anche layout complessi e rilevare elementi di layout su larga scala. Questi modelli saranno particolarmente utili per i documenti contenenti moduli o regioni di testo multiple. I modelli di layout addestrabili consentiranno di ottenere una rappresentazione più accurata dei documenti, facilitando la trascrizione e l'analisi dei documenti storici.
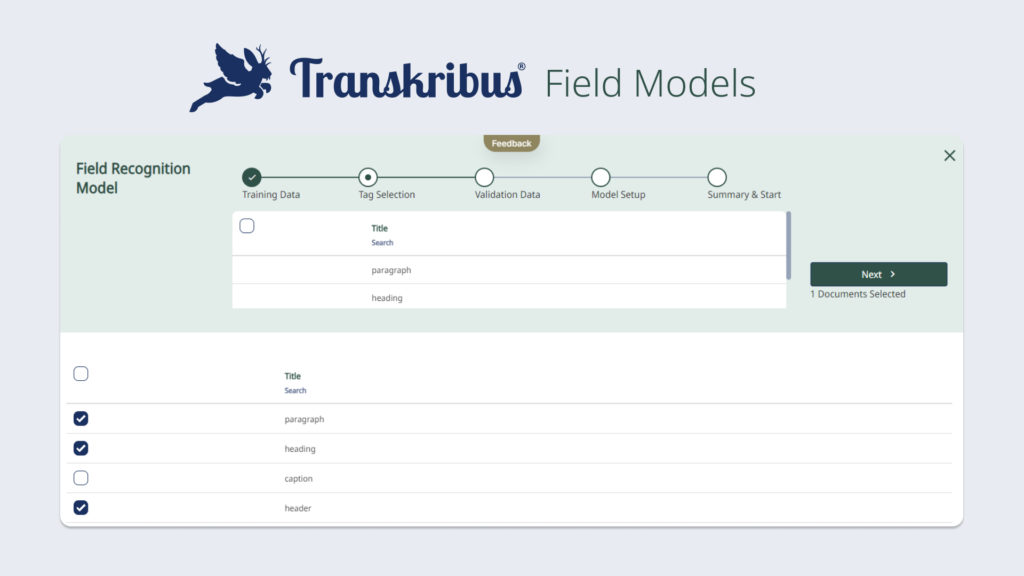
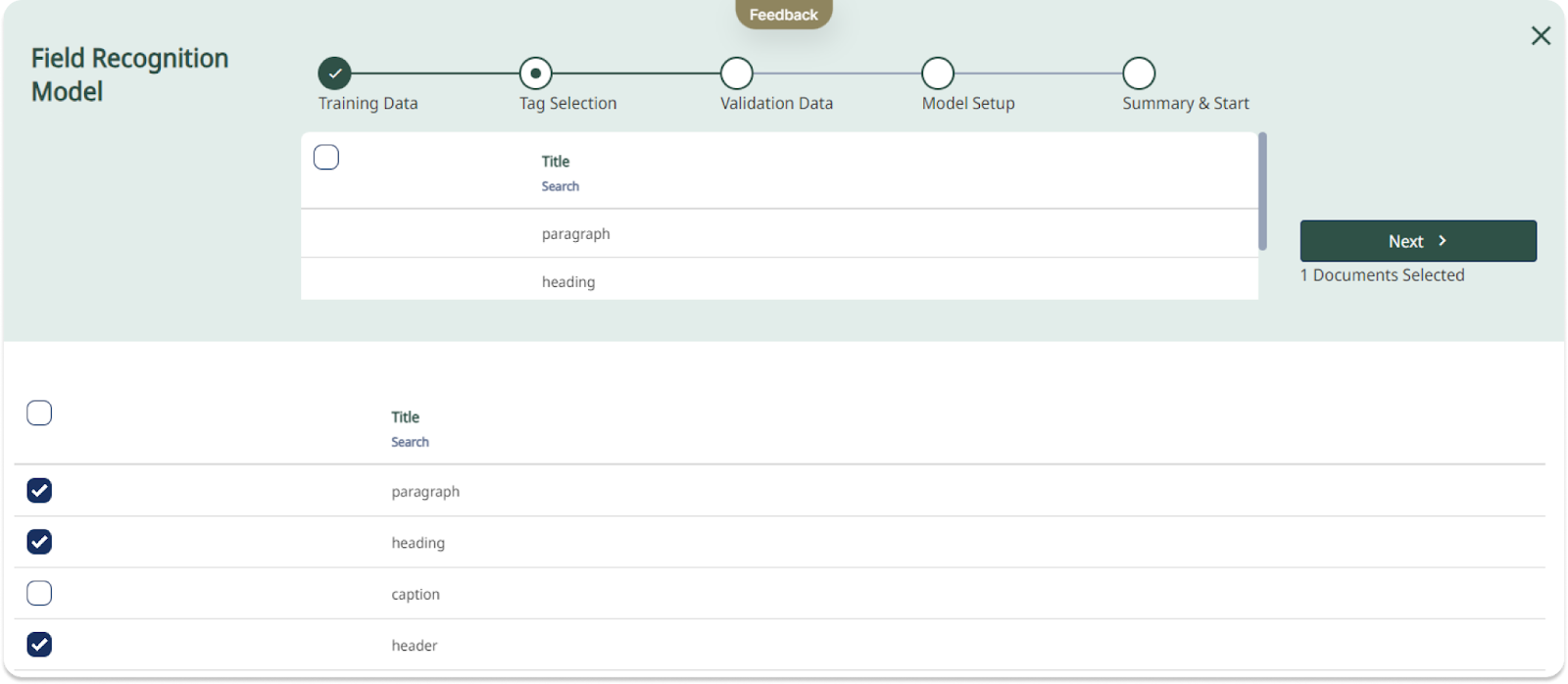
Un modello di riconoscimento del campo può essere addestrato per riconoscere e trascrivere il layout.
Vantaggi dei modelli di campo
Che cosa significa per voi utenti l'introduzione dei modelli di campo? Finora il processo di trascrizione di documenti con layout complessi richiedeva molto tempo. Disegnare manualmente le regioni di testo su ogni pagina e adattarle alle sottili differenze di layout all'interno di una raccolta è un compito che richiede molto tempo. Con il riconoscimento del layout addestrabile, tuttavia, Transkribus può essere addestrato a riconoscere e trascrivere automaticamente layout complessi.
A differenza dei modelli P2PaLA attualmente disponibili, i modelli Field richiedono meno dati di addestramento e sono più precisi. I nuovi modelli Field sono progettati per essere addestrati efficacemente con una quantità limitata di materiale di formazione, semplificando il processo. Questo approccio consente di ridurre il tempo dedicato alla creazione o alla regolazione delle regioni o alla marcatura di diversi elementi di layout su ogni pagina. Gli utenti possono invece concentrarsi sulla generazione delle forme di layout corrette per addestrare il modello, lasciando che Transkribus si occupi del resto.
È già possibile provare i Field Models su un piccolo set di dati, qui su beta.transkribus.eu
Quali tipi di documenti supportano i modelli di campo?
Dopo aver discusso il perché e il come del modello e i modi in cui esso sarà utile ai nostri utenti, diamo un'occhiata più da vicino ai tipi di documenti e layout che possono essere elaborati meglio con questa funzione. I modelli di campo copriranno un gran numero di casi di layout e potranno essere utilizzati per trovare regioni di testo, con giornali e per la segmentazione dei moduli.
Regioni di testo
Quando si ha a che fare con layout di documenti complessi come giornali, periodici o registri, è importante comprendere il concetto di regione di testo. Una regione di testo è un'area distinta all'interno di un documento che contiene contenuti testuali specifici. Può trattarsi del corpo di un articolo, di un titolo, di un annuncio o di una didascalia, ognuno dei quali rappresenta un'informazione unica.
Queste regioni di testo diventano materiale di addestramento essenziale per i nostri nuovi modelli di campo. Segmentando manualmente queste regioni e creando una raccolta di pagine di verità, creiamo una guida di base. Questa guida serve ai modelli di campo come punto di riferimento per riconoscere e classificare con precisione regioni di testo simili in altri documenti. Di conseguenza, i nostri sforzi di digitalizzazione diventano più accurati e completi, il che è particolarmente prezioso quando si naviga negli intricati layout tipici dei giornali storici.
Esempio di impaginazione di un giornale con regioni di testo sovrapposte.
Newspapers
Un candidato privilegiato per l'applicazione dei modelli di campo all'interno del layout addestrabile è rappresentato dai giornali storici. 1TP16I giornali, con la loro particolare complessità di impaginazione, sono stati per lungo tempo una pietra miliare della distribuzione delle informazioni, risalente a secoli fa. Sono spesso divisi in più colonne, con intricate sezioni di intestazione e intercalati da immagini, pubblicità o illustrazioni: un layout che può essere difficile da digitalizzare con precisione.
In precedenza, il processo di conversione dei giornali in formato digitale si basava sul rilevamento dei blocchi stampati. Pur essendo utile, questo metodo non era sempre preciso, soprattutto quando si trattava di etichettare le regioni di sovrapposizione, che non sono rare nei layout dei giornali. Le regioni di sovrapposizione possono essere causate, ad esempio, dalla continuazione di articoli su più colonne o pagine o da annunci pubblicitari molto fitti.
I nuovi modelli di campo addestrabili, invece, offrono un approccio più sofisticato alla gestione di queste complessità. Sono in grado di riconoscere ed etichettare con precisione anche le regioni che si sovrappongono, il che si rivela un grande vantaggio quando si ha a che fare con i layout sfaccettati dei giornali.
Per applicare efficacemente un Modello di campo personalizzato ai giornali, è necessario innanzitutto preparare le pagine di Ground Truth. Questa preparazione comporta l'identificazione e l'etichettatura accurata delle varie regioni all'interno del layout del giornale. Una volta create queste pagine di verità di terra etichettate, si può procedere all'addestramento del modello, assicurandosi che sia preparato a gestire le specifiche del layout dei giornali. Questo metodo promette una maggiore precisione e, di conseguenza, un processo di digitalizzazione più efficace e affidabile.
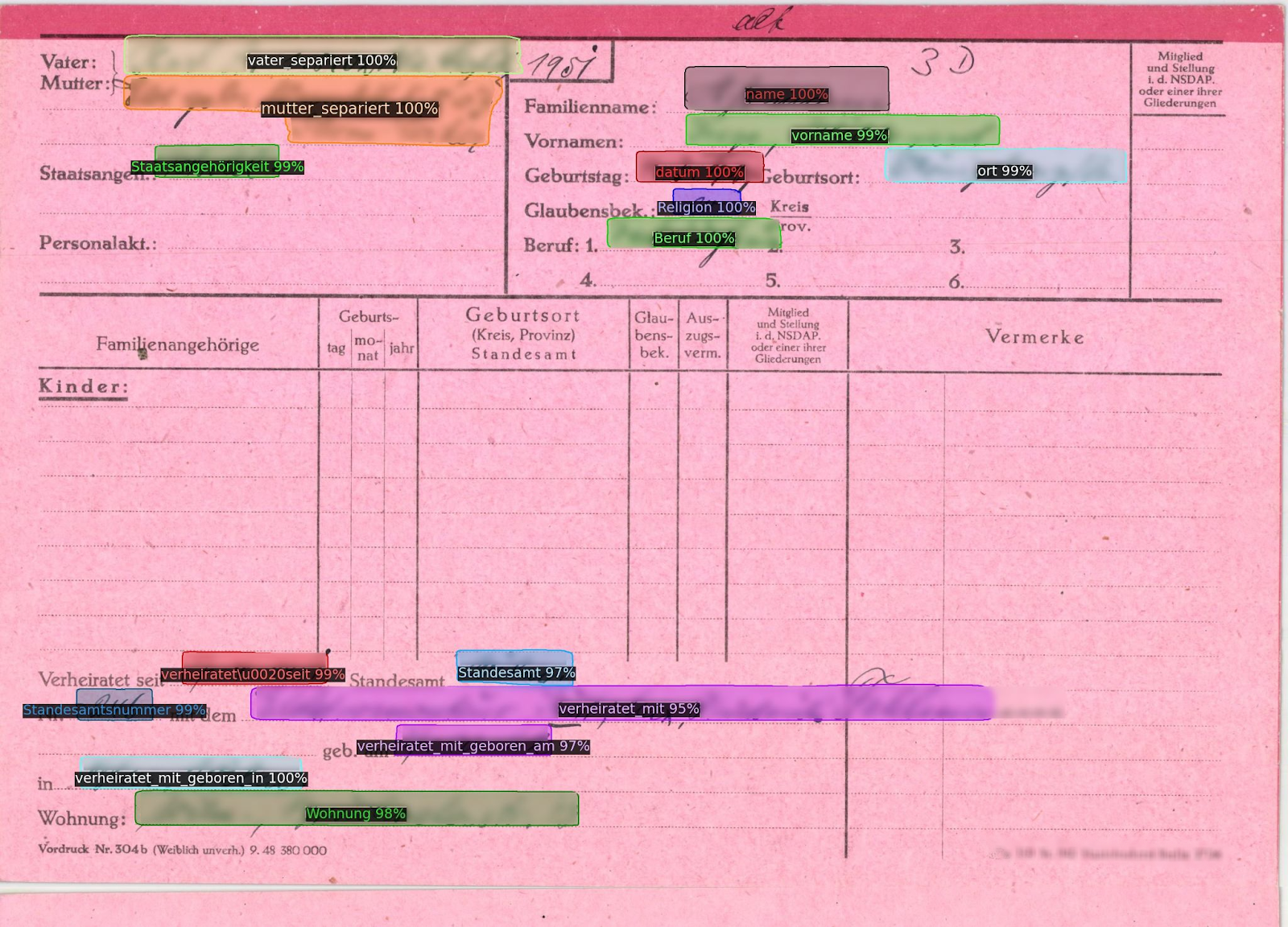
Esempio di modulo storico con più tag.
Moduli
I moduli storici sono un altro tipo di documento che può trarre grande beneficio dall'uso dei Field Models. Questi moduli, che si tratti di registri di censimento, moduli di arruolamento militare o documenti di immigrazione, hanno svolto nel corso della storia un ruolo cruciale nella registrazione di informazioni chiave su individui e popolazioni.
Tuttavia, quando si digitalizzano questi moduli, spesso sono interessanti solo i dati inseriti e compilati. Ad esempio, in un modulo di immigrazione, le informazioni necessarie sono i nomi effettivi, le date di nascita e i luoghi di origine, piuttosto che i campi ripetitivi come "Cognome" o "Data di nascita".
Per concentrarsi su questi dati rilevanti, gli utenti possono creare regioni di testo specificamente intorno alle informazioni compilate e assegnare loro etichette o tag appropriati, come "Cognome", "Nome", "Data di nascita". I modelli di campo addestrati possono quindi riconoscere queste etichette e applicare automaticamente il layout corretto alle pagine rimanenti della raccolta, estraendo solo i dati essenziali. Ciò offre un approccio molto più snello e mirato alla digitalizzazione dei moduli storici, facendo risparmiare tempo e assicurando che vengano estratte solo le informazioni necessarie.
Cosa c'è dopo?
L'attuale versione dei modelli di campo addestrabili presenta alcune difficoltà, in particolare con gli oggetti non rettangolari, con gli involucri di testo e con gli oggetti insolitamente sottili o lunghi. Tuttavia, non consideriamo questi problemi come una battuta d'arresto, ma come una possibilità di miglioramento futuro. Il nostro obiettivo è quello di risolvere i limiti dell'attuale riconoscimento del layout e di migliorare i nuovi modelli di layout estendendone l'uso a diversi formati di documenti e tipi di layout.
Siamo quindi lieti di annunciare che nelle prossime settimane introdurremo anche i nostri nuovi modelli di tabella addestrabili, progettati specificamente per la digitalizzazione di tabelle di documenti storici. I modelli di tabella offrono flessibilità nella personalizzazione del riconoscimento e possono adattarsi ai cambiamenti di layout, garantendo un'interpretazione accurata e un'estrazione completa dei dati, anche da tabelle con formati irregolari.
Per quanto riguarda i nuovi modelli di campo di Transkribus, nelle prossime settimane saranno aggiunti alla nostra interfaccia utente per l'uso generale. Su un piccolo gruppo di pagine, è già possibile provare il modello di campo addestrabile qui su beta.transkribus.eu. Questo aggiornamento consentirà a ogni utente di formare il proprio modello di layout per i campi, democratizzando il processo di digitalizzazione dei documenti e liberando un potenziale ancora maggiore all'interno della nostra piattaforma.
A gennaio abbiamo annunciato i nostri nuovi piani di abbonamento: Individuale, Studente e Organizzazione. Ciascun piano è adattato a un particolare ...
Uno dei maggiori vantaggi di Transkribus è la possibilità di addestrare modelli personalizzati di riconoscimento del testo scritto a mano. Questa caratteristica unica ...
🍪 Un po' di cookies per te 🍪
Utilizziamo i cookie per personalizzare e migliorare i contenuti e i servizi, fornire pubblicità pertinente e migliorare la sicurezza dei nostri utenti. È possibile controllare le impostazioni dei cookie in qualsiasi momento. Per ulteriori informazioni sull'uso dei cookie e sulle impostazioni dei cookie, consultare il nostro Privacy policy Cookie settingsRejectAccept
Politica sulla privacy e sui cookie
Panoramica sulla privacy
Questo sito web utilizza i cookie per migliorare la tua esperienza durante la navigazione nel sito. Di questi cookie, quelli classificati come necessari vengono memorizzati nel tuo browser, perché sono essenziali per il funzionamento delle funzionalità di base del sito web. Utilizziamo anche cookie di terze parti che ci aiutano ad analizzare e capire come utilizzi questo sito web. Questi cookie vengono memorizzati nel tuo browser solo con il tuo consenso. Hai anche la possibilità di rinunciare a questi cookie. Ma l'opt-out di alcuni di questi cookie può avere un effetto sulla tua esperienza di navigazione.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questa categoria comprende solo i cookie che assicurano le funzionalità di base e le caratteristiche di sicurezza del sito web. Questi cookie non memorizzano alcuna informazione personale.
Cookie
Descrizione
Durata
politica dei cookie visualizzati
Il cookie è impostato dal plugin GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
1 ora
PHPSESSID
Questo cookie è nativo delle applicazioni PHP. Il cookie viene utilizzato per memorizzare e identificare l'ID di sessione unico di un utente allo scopo di gestire la sessione dell'utente sul sito web. Il cookie è un cookie di sessione e viene cancellato quando tutte le finestre del browser vengono chiuse.
I cookie pubblicitari sono utilizzati per fornire ai visitatori annunci pertinenti e campagne di marketing. Questi cookie tracciano i visitatori attraverso i siti web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Descrizione
Durata
VISITATORE_INFO1_LIVE
Questo cookie è impostato da Youtube. Utilizzato per tracciare le informazioni dei video di YouTube incorporati in un sito web.
5 mesi
IDE
Utilizzato da Google DoubleClick e memorizza le informazioni su come l'utente utilizza il sito web e qualsiasi altra pubblicità prima di visitare il sito. Questo viene utilizzato per presentare agli utenti gli annunci che sono rilevanti per loro in base al profilo dell'utente.
I cookie analitici sono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, la frequenza di rimbalzo, la fonte del traffico, ecc.
Cookie
Descrizione
Durata
GPS
Questo cookie è impostato da Youtube e registra un ID unico per tracciare gli utenti in base alla loro posizione geografica
30 minuti
tk_or
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
5 anni
tk_r3d
Il cookie è installato da JetPack. Utilizzato per le metriche interne delle attività dell'utente per migliorare l'esperienza dell'utente
3 giorni
tk_lr
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
1 anno
{\an8}Che cosa?
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per calcolare i dati del visitatore, della sessione, del camapign e per tenere traccia dell'utilizzo del sito per il rapporto di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato randoly per identificare i visitatori unici.
2 anni
_gid
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per memorizzare informazioni su come i visitatori utilizzano un sito web e aiuta a creare un rapporto analitico su come sta andando il sito web. I dati raccolti includono il numero di visitatori, la fonte da cui provengono e le pagine visitate in forma anonima.
1 giorno
matomo
Per l'analisi statistica, usiamo "Matomo" su questo sito web. Si tratta di uno strumento open source per l'analisi del web. Matomo non trasmette dati a server al di fuori del controllo di READ-COOP. Matomo viene disattivato quando si visita il nostro sito web. Solo se lei acconsente attivamente, il suo comportamento d'uso viene registrato in modo anonimo.
1 anno
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot è un servizio di gestione di database di utenti fornito da HubSpot, Inc. Su questo sito web utilizziamo HubSpot per le nostre attività di assistenza clienti online.
I cookie di performance sono utilizzati per capire e analizzare gli indici di performance chiave del sito web che aiuta a fornire una migliore esperienza utente per i visitatori.
Cookie
Descrizione
Durata
YSC
Questo cookie è impostato da Youtube e viene utilizzato per monitorare le visualizzazioni dei video incorporati.
1 anno
_gat
Questo cookie è installato da Google Universal Analytics per strozzare il tasso di richiesta per limitare la raccolta di dati su siti ad alto traffico.