Tuttavia, la formazione di modelli accurati è un'abilità che richiede un po' di tempo per essere padroneggiata. Se siete alle prime armi con l'addestramento dei modelli, potreste rapidamente sentirvi frustrati dall'elevato tasso di errore dei caratteri, o CER, del vostro modello. Si tratta di un numero compreso tra 0% e 100% che indica l'accuratezza del modello. Un modello con un CER di 100% produrrà una trascrizione molto imprecisa, mentre un modello con un CER di 0% fornirà una trascrizione perfetta e priva di errori.
In generale, si dovrebbe puntare a un CER di 10% o meno. In questo modo si otterranno trascrizioni sufficientemente accurate ai fini della ricerca e di ulteriori analisi. Ma se il CER del vostro modello è superiore a questo valore, non disperate: ci sono molti modi semplici per ridurre il CER e creare un modello adatto ai vostri documenti. Vediamo i cinque modi più semplici per migliorare il CER del vostro modello.
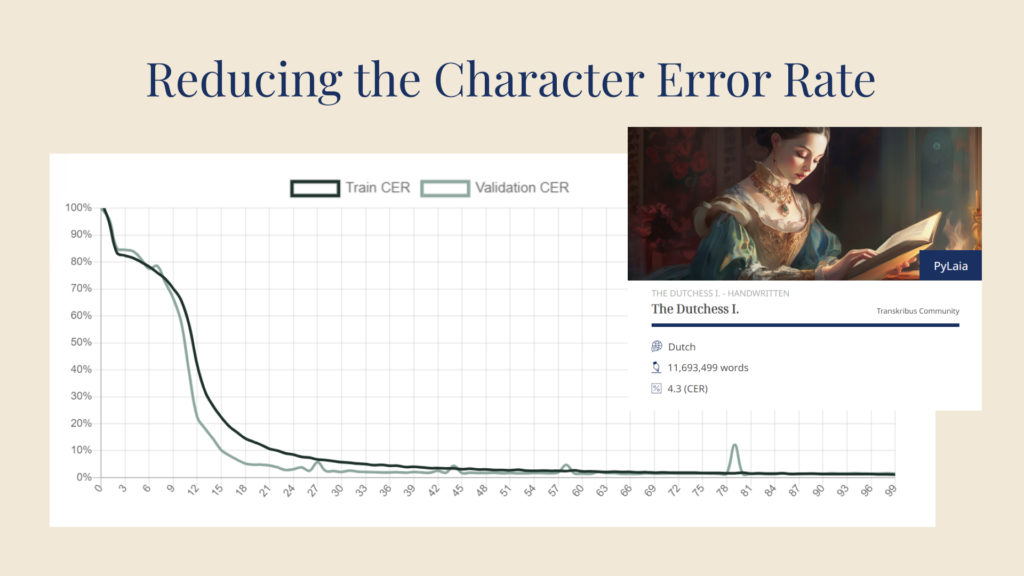
Il CER è indicato per ogni modello, insieme alla lingua e alla scrittura. Immagine tramite Transkribus.
Che cos'è il CER?
Prima di iniziare, diamo una rapida occhiata al CER. Il CER è la percentuale di caratteri trascritti in modo errato dal modello di riconoscimento del testo durante il test. Se un modello ha un CER di 5%, significa che, rispetto alla trascrizione manuale, 5 caratteri su 100 sono stati trascritti in modo errato dal modello, un numero relativamente basso.
Ma come viene calcolato il CER? Quando si crea un modello, è necessario fornire due serie di pagine accurate e trascritte manualmente: il set di addestramento, che viene utilizzato per addestrare il modello, e il set di validazione, che di solito contiene una selezione di pagine dal set di addestramento e viene utilizzato per testare il modello. Questi dati di addestramento sono noti anche come Ground Truth.
Durante l'addestramento, il modello analizza tutte le pagine dell'insieme di addestramento e cerca di imparare la scrittura. Successivamente, verifica ciò che ha appreso tentando la trascrizione automatica delle pagine dell'insieme di validazione. La trascrizione automatica delle pagine effettuata dal modello viene confrontata con la trascrizione manuale accurata e viene calcolato il numero di errori. Questo viene poi trasformato in una percentuale e si ottiene il CER.
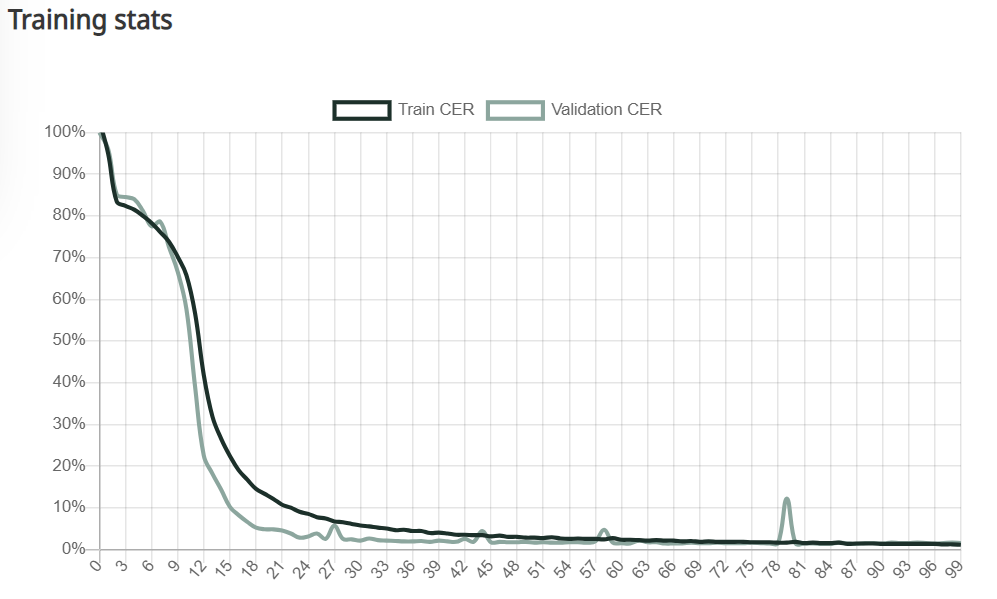
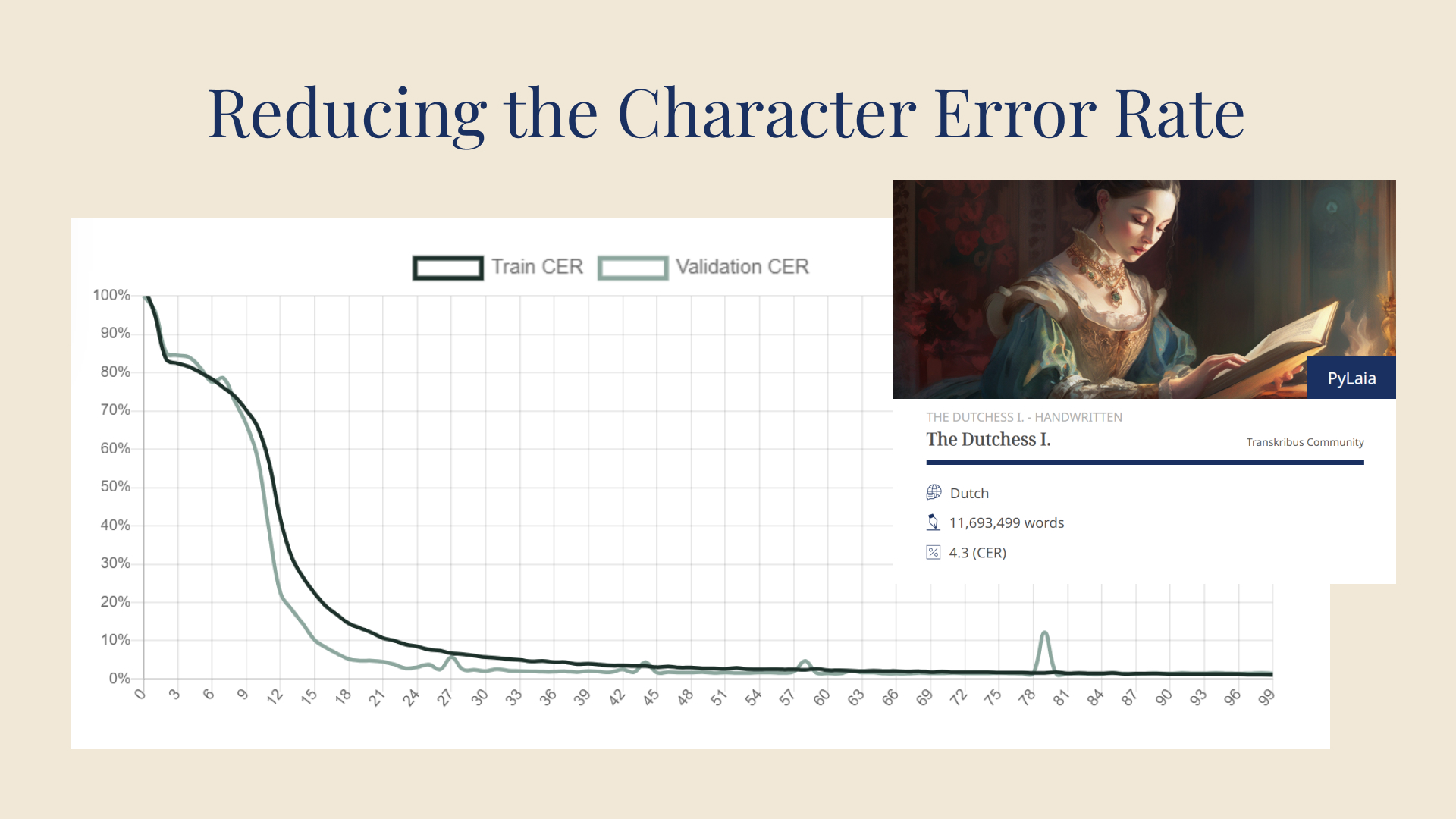
Più epoche (indicate sull'asse x) vengono eseguite, più basso diventa il CER (indicato sull'asse y). Immagine da Transkribus.
La prima volta che il modello esegue questo processo - noto come epoch - ci si può aspettare che il CER sia piuttosto alto. Tuttavia, il modello eseguirà molte altre epoch, imparando ogni volta di più e commettendo sempre meno errori durante il test sul set di validazione. Nel corso del tempo, il modello avrà imparato tutto il possibile e ogni epoch avrà lo stesso CER. Questo dato viene considerato il CER del modello.
Un'altra cosa...
Tenete presente che il CER calcola ogni minima discrepanza rispetto ai dati di addestramento come errori, compresi spazi, punteggiatura e lettere minuscole al posto di quelle maiuscole. È possibile che il modello abbia un CER elevato, ma che la maggior parte degli errori non riguardi le lettere vere e proprie e che le trascrizioni siano in realtà abbastanza accurate. Pertanto, vale sempre la pena di testare il modello su alcune pagine dopo l'addestramento, perché anche un modello con un CER elevato potrebbe comunque fornire un testo ricercabile adatto ai propri scopi.
Cinque modi per migliorare il CER del vostro modello
Se il vostro modello ha completato molte epoche di addestramento e state ancora ricevendo un CER piuttosto alto e trascrizioni imprecise, ecco cinque cose che potete fare per migliorare l'accuratezza del vostro modello.
1. Assicuratevi che i dati di formazione siano accurati.
I dati di addestramento sono le pagine trascritte manualmente fornite per il set di addestramento e il set di convalida. Devono essere 100% accurate e completamente prive di errori.
Questo è importante perché il modello è tanto preciso quanto i dati di addestramento che gli sono stati forniti. Se ci sono errori nei dati di addestramento, questi errori si riprodurranno in qualsiasi cosa il modello cerchi di trascrivere. Se si ricevono CER molto elevati, vale la pena di esaminare i dati di addestramento e verificare che siano il più accurati possibile.
Quanto più accurati sono i dati di addestramento, tanto più accurato sarà il modello. Immagine tratta da NAF Court Records, via Transkribus
2. Assicuratevi che i dati di allenamento siano coerenti.
Allo stesso modo, i dati di addestramento devono essere coerenti. Ciò è particolarmente importante se i documenti contengono abbreviazioni, punteggiatura insolita o altri elementi linguistici "non standard". Se questi elementi sono trascritti in modo incoerente nei dati di addestramento, si rischia di confondere il modello, con conseguente aumento del CER.
Visitate il nostro Centro assistenza per ulteriori informazioni sulla coerenza con i dati di allenamento.
Essere coerenti con le convenzioni di trascrizione insegna al modello a trascrivere nello stesso modo. Immagine dal Diario di Marjory Fleming, via Transkribus
3. Non dimenticatevi delle linee di base.
Sebbene sia facile concentrarsi solo sulla parte testuale della trascrizione, non bisogna dimenticare il layout. Prima di ogni riconoscimento del testo, Transkribus esegue un'analisi del layout. Ciò consente alla piattaforma di individuare la posizione del testo sulla pagina, in modo da sapere cosa trascrivere durante la fase di riconoscimento del testo.
È quindi importante che le linee di base (le linee colorate sotto ogni riga di testo) siano indicate con precisione nei dati di addestramento. In questo modo, il modello cercherà di trovare i caratteri solo nei punti in cui esistono effettivamente, creando trascrizioni più accurate. Per sapere come regolare le linee di base, consultate il nostro sito Centro assistenza.
Le linee di base precise assicurano che il modello apprenda correttamente la posizione del testo nella pagina. Immagine da "Bulliot, Bibracte et moi", via Transkribus
4. Continuate ad aggiungere altri dati.
Se si sono esaminati i dati di addestramento e si è certi che il testo e le linee di base siano del tutto accurati e coerenti, il passo successivo sarà quello di aggiungere altri dati di addestramento.
In generale, si consiglia di avere almeno 25 pagine di dati di addestramento per un modello. Naturalmente, più dati di addestramento si hanno, più informazioni il modello può apprendere e più sarà accurato.
Ciò è particolarmente vero se i documenti sono molto eterogenei, ad esempio se presentano diversi tipi di scrittura. In questi casi, potrebbero essere necessari più dati di addestramento per ridurre il CER del modello.
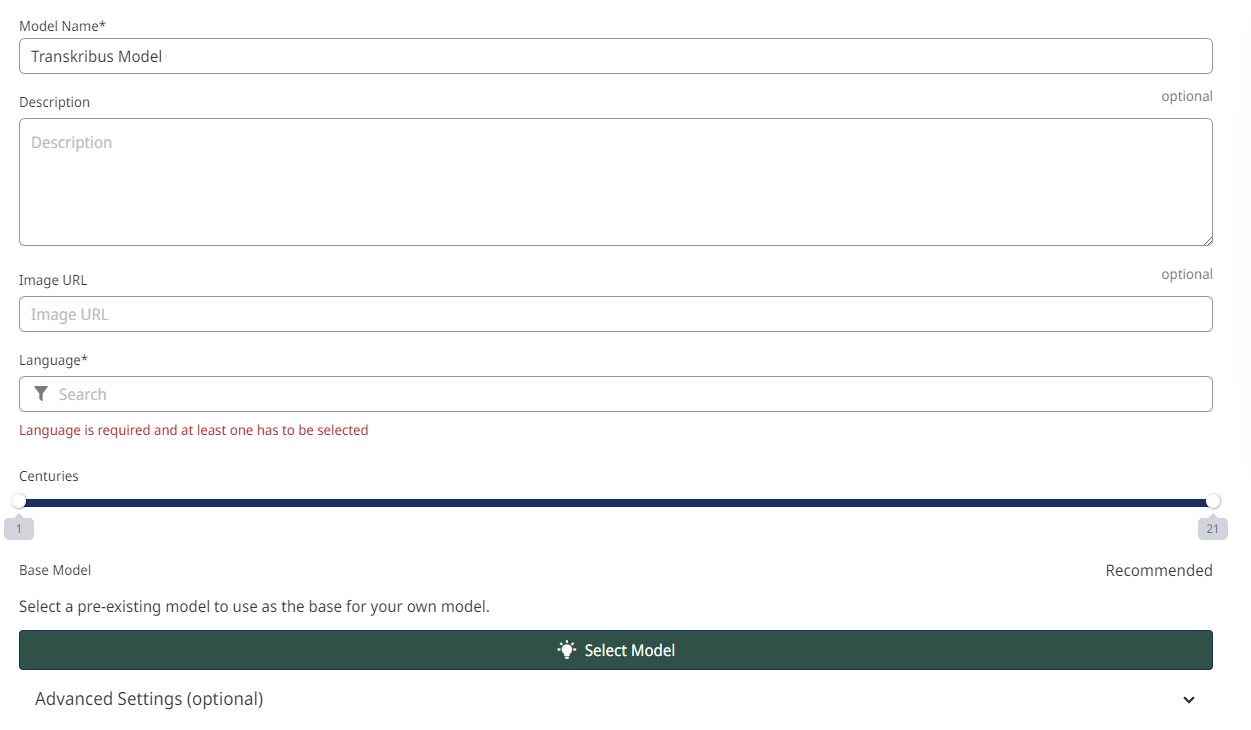
Selezionare un modello di base significa che il nuovo modello non deve essere addestrato da zero. Immagine da Transkribus.
5. Utilizzare un modello base.
Quest'ultimo suggerimento può non solo migliorare il CER del modello, ma anche far risparmiare tempo. Quando si imposta un nuovo modello, è possibile selezionare un "modello base". Si tratta di un modello preesistente che verrà utilizzato come base per il nuovo modello personalizzato. Il modello di base deve essere addestrato su una lingua, una grafia e un periodo di tempo simili a quelli dei vostri documenti.
L'utilizzo di un modello di base significa che il nuovo modello non deve essere addestrato completamente da zero. Può invece utilizzare le informazioni memorizzate nel modello di base ed espanderle con i dati di addestramento. In genere si ottiene un modello più accurato con meno dati di addestramento, risparmiando tempo e fatica.
Avete bisogno di ulteriori informazioni sull'addestramento dei modelli di riconoscimento del testo con Transkribus? Consultate la sezione Modelli di addestramento nel nostro Centro assistenza.
A gennaio abbiamo annunciato i nostri nuovi piani di abbonamento: Individuale, Studente e Organizzazione. Ciascun piano è adattato a un particolare ...
Uno dei maggiori vantaggi di Transkribus è la possibilità di addestrare modelli personalizzati di riconoscimento del testo scritto a mano. Questa caratteristica unica ...
La primavera è arrivata e così anche l'uscita di aprile 2024 di Transkribus. Ecco una rapida panoramica di tutte le ...
🍪 Un po' di cookies per te 🍪
Utilizziamo i cookie per personalizzare e migliorare i contenuti e i servizi, fornire pubblicità pertinente e migliorare la sicurezza dei nostri utenti. È possibile controllare le impostazioni dei cookie in qualsiasi momento. Per ulteriori informazioni sull'uso dei cookie e sulle impostazioni dei cookie, consultare il nostro Privacy policy Cookie settingsRejectAccept
Politica sulla privacy e sui cookie
Panoramica sulla privacy
Questo sito web utilizza i cookie per migliorare la tua esperienza durante la navigazione nel sito. Di questi cookie, quelli classificati come necessari vengono memorizzati nel tuo browser, perché sono essenziali per il funzionamento delle funzionalità di base del sito web. Utilizziamo anche cookie di terze parti che ci aiutano ad analizzare e capire come utilizzi questo sito web. Questi cookie vengono memorizzati nel tuo browser solo con il tuo consenso. Hai anche la possibilità di rinunciare a questi cookie. Ma l'opt-out di alcuni di questi cookie può avere un effetto sulla tua esperienza di navigazione.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questa categoria comprende solo i cookie che assicurano le funzionalità di base e le caratteristiche di sicurezza del sito web. Questi cookie non memorizzano alcuna informazione personale.
Cookie
Descrizione
Durata
politica dei cookie visualizzati
Il cookie è impostato dal plugin GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
1 ora
PHPSESSID
Questo cookie è nativo delle applicazioni PHP. Il cookie viene utilizzato per memorizzare e identificare l'ID di sessione unico di un utente allo scopo di gestire la sessione dell'utente sul sito web. Il cookie è un cookie di sessione e viene cancellato quando tutte le finestre del browser vengono chiuse.
I cookie pubblicitari sono utilizzati per fornire ai visitatori annunci pertinenti e campagne di marketing. Questi cookie tracciano i visitatori attraverso i siti web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Descrizione
Durata
VISITATORE_INFO1_LIVE
Questo cookie è impostato da Youtube. Utilizzato per tracciare le informazioni dei video di YouTube incorporati in un sito web.
5 mesi
IDE
Utilizzato da Google DoubleClick e memorizza le informazioni su come l'utente utilizza il sito web e qualsiasi altra pubblicità prima di visitare il sito. Questo viene utilizzato per presentare agli utenti gli annunci che sono rilevanti per loro in base al profilo dell'utente.
I cookie analitici sono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, la frequenza di rimbalzo, la fonte del traffico, ecc.
Cookie
Descrizione
Durata
GPS
Questo cookie è impostato da Youtube e registra un ID unico per tracciare gli utenti in base alla loro posizione geografica
30 minuti
tk_or
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
5 anni
tk_r3d
Il cookie è installato da JetPack. Utilizzato per le metriche interne delle attività dell'utente per migliorare l'esperienza dell'utente
3 giorni
tk_lr
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
1 anno
{\an8}Che cosa?
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per calcolare i dati del visitatore, della sessione, del camapign e per tenere traccia dell'utilizzo del sito per il rapporto di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato randoly per identificare i visitatori unici.
2 anni
_gid
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per memorizzare informazioni su come i visitatori utilizzano un sito web e aiuta a creare un rapporto analitico su come sta andando il sito web. I dati raccolti includono il numero di visitatori, la fonte da cui provengono e le pagine visitate in forma anonima.
1 giorno
matomo
Per l'analisi statistica, usiamo "Matomo" su questo sito web. Si tratta di uno strumento open source per l'analisi del web. Matomo non trasmette dati a server al di fuori del controllo di READ-COOP. Matomo viene disattivato quando si visita il nostro sito web. Solo se lei acconsente attivamente, il suo comportamento d'uso viene registrato in modo anonimo.
1 anno
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot è un servizio di gestione di database di utenti fornito da HubSpot, Inc. Su questo sito web utilizziamo HubSpot per le nostre attività di assistenza clienti online.
I cookie di performance sono utilizzati per capire e analizzare gli indici di performance chiave del sito web che aiuta a fornire una migliore esperienza utente per i visitatori.
Cookie
Descrizione
Durata
YSC
Questo cookie è impostato da Youtube e viene utilizzato per monitorare le visualizzazioni dei video incorporati.
1 anno
_gat
Questo cookie è installato da Google Universal Analytics per strozzare il tasso di richiesta per limitare la raccolta di dati su siti ad alto traffico.