+ Winning competitions and awards! READ technology is at the cutting-edge
December 21, 2017
Competitions, Data sets, Events, HTR models, News, Success stories
We wanted to round off 2017 by celebrating some fantastic advances in the Handwritten Text Recognition (HTR) and Layout analysis of historical documents.
In the field of computer science, official competitions give researchers the chance to refine new technologies and ensure that the best techniques rise to the fore. In fact, the READ project has its own platform for research competitions (ScriptNet), where computer scientists can participate in or organise competitions.
Joan Puigcerver (PRHLT Research Centre, Universitat Politècnica de València) won the conference award for ‘Best Student Paper’ , which was entitled ‘Are Multidimensional Recurrent Layers Really Necessary for Handwritten Text Recognition?’. Multidimensional Long Short-Term Memory (MLSTM) units have been widely used for HTR in recent years. Multidimensional LSTM is a powerful form of machine learning which is capable of processing images of any size. However, these units are much slower than other architectures and require a large amount of memory. The paper argued that MLSTM units may not be necessary for HTR after all, and proposed a cheaper architecture which is able to outperform the state-of-the-art MDLSTM model and significantly reduce the amount of time needed to train a model to read and process a set of handwritten documents.
Another achievement at ICDAR 2017 came from Tobias Grüning (CITlab, Universität Rostock) who won the Competition on Layout Analysis for Challenging Medieval Manuscripts. Layout Analysis is an important part of HTR since the latter technology requires lines of text in an image to be accurately matched with lines of transcribed text. This competition was organised by the Document, Image and Voice Analysis (DIVA) research group at the University of Fribourg. The competition required participants to analyse the layout and find the text lines in a challenging dataset of medieval manuscripts with complex layouts which included marginal and interlinear additions and corrections. Grüning and his team focused on the detection of lines of text and won two out of three tasks in this competition. Their effective layout analysis technology is now available in our Transkribus platform (choose ‘CITlab advanced’ in the ‘Layout Analysis’ section of the ‘Tools’ tab). As the below image shows, this technology can cope well with the complications common in medieval documents!
Document segmented into lines using prize-winning CITlab technology. Cologny, Fondation Martin Bodmer, Cod. Bodmer 28, f. 1r – Latin Bible (available via e-codices: http://www.e-codices.unifr.ch/en/list/one/fmb/cb-0028) [Image released under CC-BY-NC licence]
Tobias Grüning (CITlab, Universität Rostock) being congratulated for his work on text line segmentation [Image by Mathias Seuret ]Our last achievement to mention came from Tobias Strauss (CITlab, Universität Rostock). He led his team to win a competition on Information Extraction in Historical Handwritten Records. The task was to extract information from handwritten marriage licenses such as names, locations and occupations and then assign this information to the corresponding persons whether they were husband, wife or father of the bride. The team worked to extract and match this information from entire lines of text. This work was done with the same functionality that is now integrated in Transkribus as part of our new Keyword Spotting tool. Keyword Spotting is a powerful form of keyword searching where the technology analyses images of writing, rather than searching through transcriptions of these words generated either by humans or computers. This tool could therefore facilitate the searching of huge collections that have not yet been transcribed.
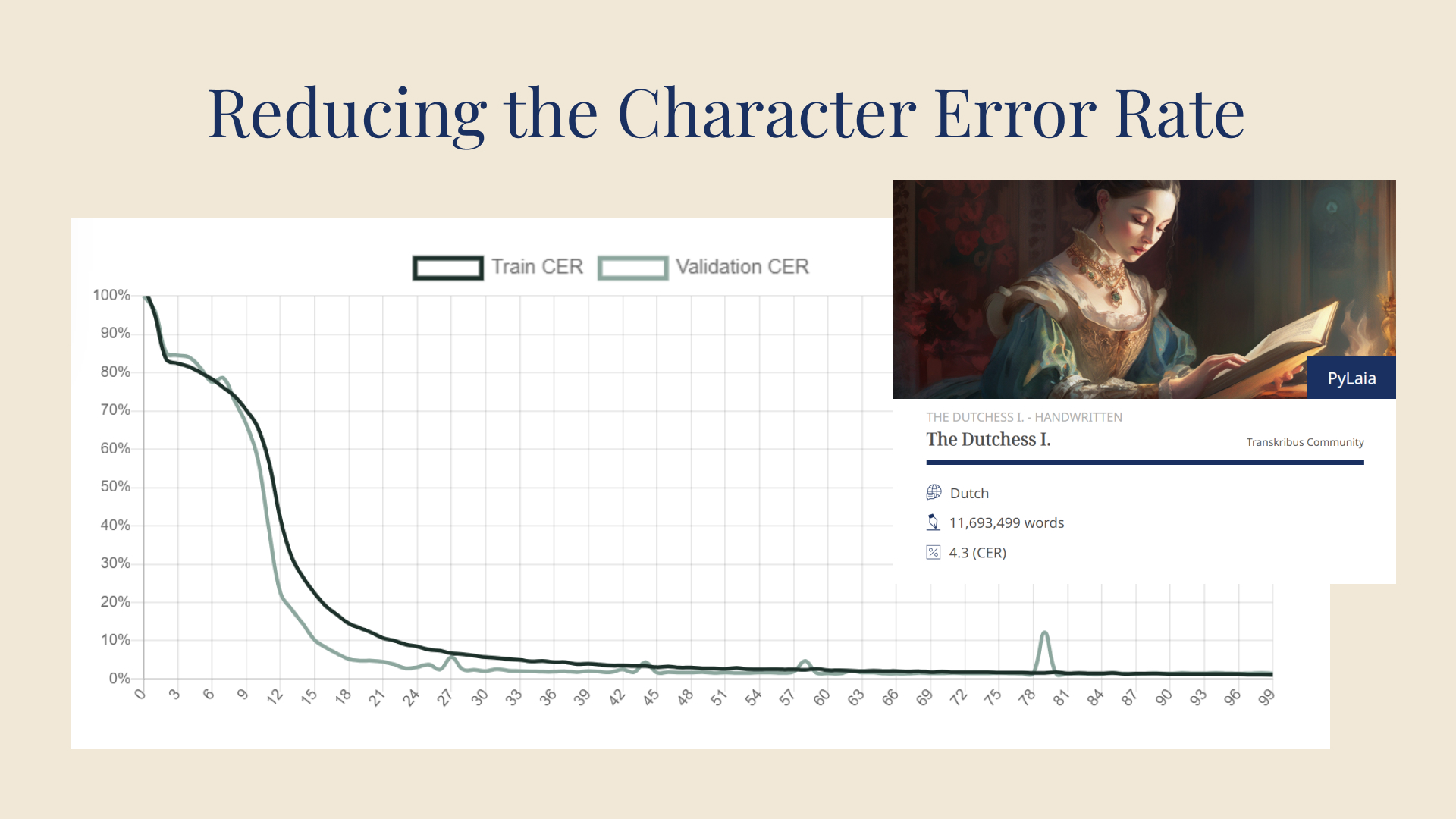
These accomplishments demonstrate that the READ project is at the cutting-edge in the developing field of HTR. We are proud to make such innovations available in Transkribus, allowing our users to automatically transcribe and search all kinds of handwritten historical documents.
Spring has sprung and so has the April 2024 release of Transkribus. Here is a quick overview of all the ...
🍪 Some cookies for you 🍪
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.