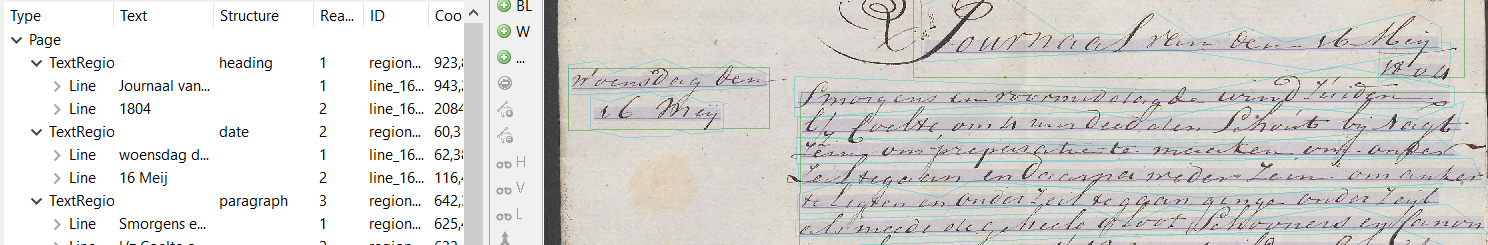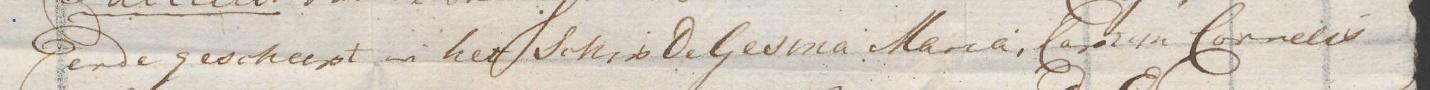Navigating the Transcription of Dutch Prize Papers
READ-COOP SCE
Have you ever sent a letter that never arrived? From 1652-1815 the British navy and privateers seized all types of documents from enemy ships, ship logs, cargo lists and even private letters. Hundreds of years later, the Huygens Institute in the Netherlands started the Dutch Prize Papers project to digitise and analyse these historical documents and transcribe them with the help of Transkribus.
Marijcke Schillings, historian, researcher and coordinator of the Dutch Prize Papers told us more about the project from its start in 2016, its documents and how the Transkribus software was involved to create an AI text recognition model.
The Dutch Prize Papers project
What are the Prize Papers?
From ship logs, cargo lists, plantation records, and crew interrogations to letters, the documents making up the Dutch Prize Papers are anything but trivial. These papers are kept at The National Archives in Kew (London).
Marijcke Schillings explains that “the Prize Papers are documents seized by the British navy and privateers from enemy ships in the period 1652-1815”. As a powerful player on the seas, the British Navy, together with privately owned and operated ships, engaged in naval warfare to disrupt enemy trade.
“This collection also contains approximately 38,000 Dutch business and private letters,” says Schillings1. With the great variety of documents, the Prize Papers therefore offer the possibility of “different types of international research” and insights into “all social strata of society”.
PrizePapers Collection, folder 1800-1810_25/HCA32-1210-0033, fragment of a GT-transcription. Transkribus platform
What is the Dutch Prize Papers project?
As the national institute for research on the history and culture of the Netherlands, the Huygens Institute (HI) is dedicated to innovative and collaborative research on historical sources and literary texts. The aim of the Dutch Prize Paper project was, firstly, to have a large selection of digitised (Dutch) documents available for research and, secondly, “to make printed and handwritten texts more searchable and readable”.
At the end of 2015, the Huygens Institute received a substantial subsidy that made it possible to achieve the first step.
In June 2019, 72,000 scans or 140,000 pages of mainly Dutch documents from the seventeenth to the early nineteenth century and their metadata became available online on the Dutch Prize Papers website. To improve access to digitised documents, the Huygens Institute therefore created a Virtual Research Environment (VRE).
Working towards the second step, Marijcke Schillings and her colleagues from the DPP project turned to Transkribus’ text recognition software. Since several Huygens Institute projects “already had experience with the user-friendly HTR platform and achieved good results”, the team decided to start a pilot project, with the primary goal of exploring automatic text recognition.
PrizePapers Collection, folder 1800-1810_24/HCA32-1210-0016b, fragment layout-analysis. Transkribus Platform
Creating an AI model with Transkribus
For this pilot project, 100 scans of documents from different centuries and written in varying languages were selected to train a custom text recognition model.
Layout Ground Truth
After choosing the material, the team started working on creating Ground Truth pages of the layout, specifically the text regions and the baselines of the historical pages. Schillings elaborates that the baselines were first placed automatically and then checked manually, as the lines of text tended to be disintegrated or crooked.
Using the P2PaLA layout analysis tool the Ground Truth pages were then used to train three structure recognition models. However, when these models were tested, the results were not as accurate as hoped, indicating the need for additional training material. Recognising the challenges with the P2PaLA layout analysis tool, Transkribus has since introduced trainable layout models, such as the Field Models and Table Models. These trainable layout models require less training data while being more precise.
Text Ground Truth
The next step was to create Ground Truth pages of transcribed text to train the text recognition model. The Ground Truth pages were generated by using existing models and then checked and manually corrected. Based on 100 pages of Ground Truth, the DPP team created two custom text recognition models. “We decided to let create a model including a base model (i.e. IJsberg) first and a second one, exclusive of a base model.”
Model Result Comparison: DPP= ede gescheept in het Schip de Gesina Mana, Comyn Cannelis
DPP2= Dene gescheept en her Schip de Gesena Aana, Comin Corneeir
Manual=ende gescheept in het schip De Gesina Maria, Captyn Cornelis
As the team expected, the first model, including the base model IJsberg, produced the best results, which is shown in the comparison of text recognition results.
Working with the Transkribus Platform
“The experience with the Transkribus tools was very good.” summarises Marijcke Schillings. By creating two multilingual models, the team explored the potential of Handwritten Text Recognition (HTR), which was the primary objective of the pilot project. This effort resulted in a positive evaluation report that showed a significant improvement in readability.
Due to challenges in the accuracy of the layout analysis, a different tool called “Loghi” was applied to the documents of the Dutch Prize Papers Project in June 2023, which improved considerably the readability and searchability of the documents.
Listening to the feedback of our users, Transkribus now offers an improved and more efficient way of recognising layouts: trainable layout models. The trainable Field Models and Table Models are designed to produce accurate results even with complex layouts such as those found in newspapers, index cards or spreadsheets.
Website Dutch Prize Papers, HCA30-1056-0072b, Bill of lading
Creating opportunities for further research
Marijcke Schillings concludes that with this project, the DDP team was able to allow “interested people anywhere to view a small selection of papers”, consisting of more than 100,000 images, that are legible and digitally available.
The next step of the DPP project is to focus on making one specific type of document accessible, the bills of lading. Bills of lading were not usually kept after the shipment of goods by sea, clarifies Schillings. They do, however, reappear in the cargoes seized by British privateers2.
We at Transkribus are delighted to have been part of this pilot and wish the DPP project team continued success in their research into the bills of lading.
Thank you Marijcke Schillings for taking the time to talk to us!
1 R. van Gelder, Zeepost. Nooit bezorgde brieven uit de 17de en 18de eeuw (Amsterdam/Antwerpen 2008) 20-21.
2 “Flessen op papier”, A.P. v[an] V[liet], in: Buitgemaakt en teruggevonden. Nederlandse brieven en scheepspapieren in een Engels archief. Sailing Letters Journaal V. Onder redactie van E. van der Doe, P. Moree, D.J. Tang, met medewerking van P. de Bode (Zutphen 2013) 196-197.
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.