Introducing Table Models – Trainable Layout AI in Transkribus
October 27, 2023
News, Transkribus
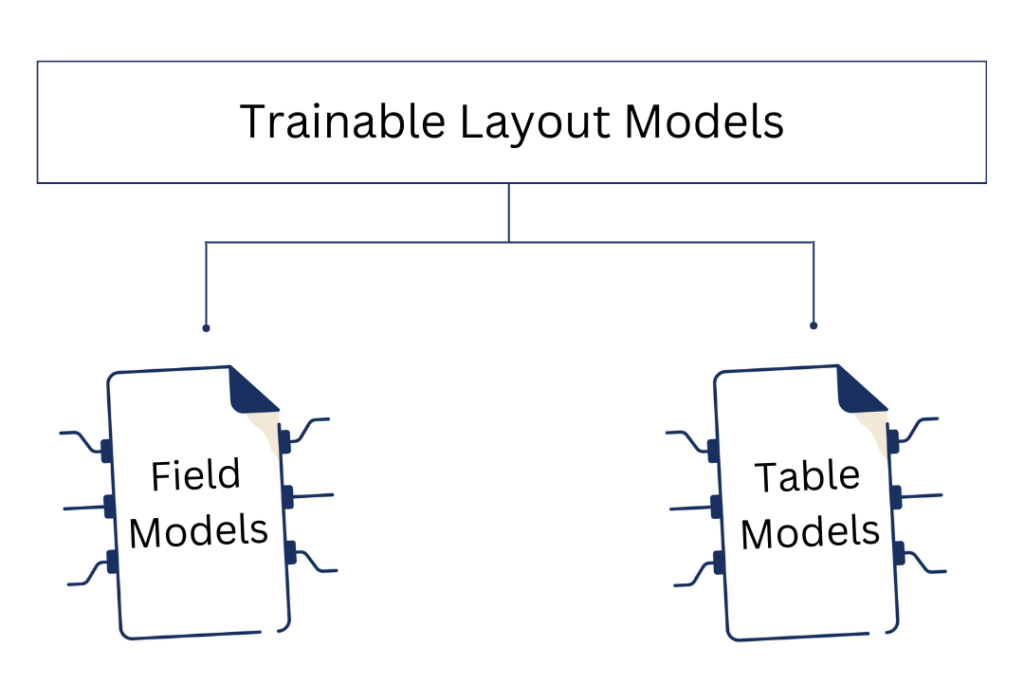
Following the launch of the new and improved web app, we are able to reveal more about the new generation of trainable layout technology. With the previously introduced trainable Field Models, it will be much easier to process documents with more complex layouts, such as newspapers, periodicals, log books, legal records or forms.
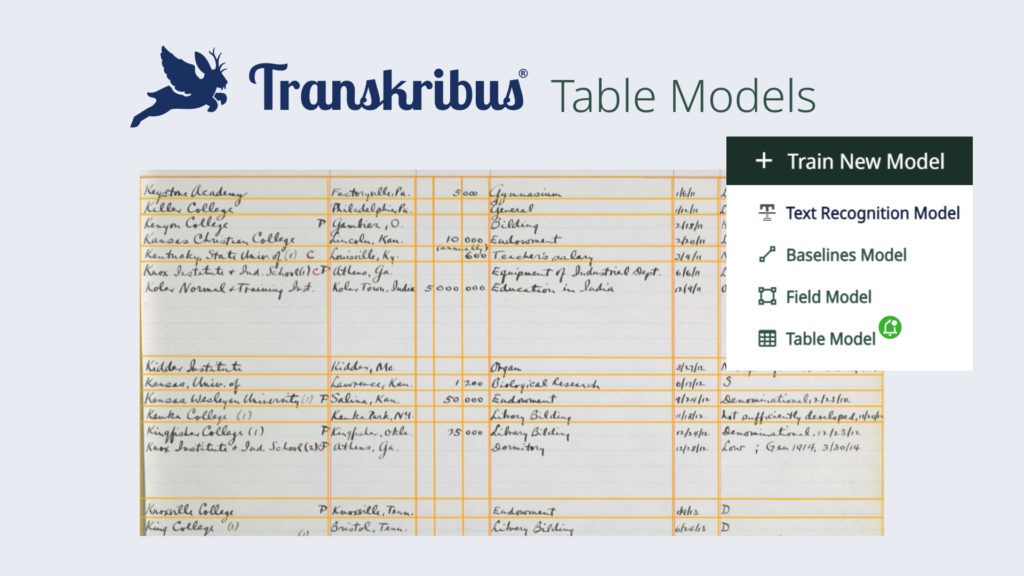
But what about the unique structure of tables? To tackle the challenge of recognising and transcribing tables, we are introducing the trainable Table Models. After the Field Models, the Table Models are the next step towards improved and more efficient layout recognition of your historical documents. We will first introduce the trainable table model and its benefits, and then explain how to get started.
The power of Table Models
When working with documents that contain or consist of tables, it is often important to recognise and capture the structure of the table’s layout as well as its content. Tables are a common way of organising data in documents such as registers, accounts, records, inventories or catalogues. When researching these documents, the data needing to be extracted is usually not limited to a few pages, but extends to a larger volume of pages. Therefore the optimal tool to help our users would be an automated but reliable layout recognition.
This is what Transkribus set out to achieve when working on the trainable Layout Models: the Field Models and the Table Models. With the trainable Table Models, our users will now be able to train a custom layout recognition model that is specifically designed to recognise the layout of the documents they are currently working on and can be applied to automatically recognise the entire collection. The new feature of a trainable Table Model will result in a more reliable layout recognition, a more efficient transcription process and easier analysis of historical data in a structured environment.
New trainable Layout options with Transkribus.
The benefit of Table Models
Using the default layout recognition may not always produce satisfying results. However, with the new trainable Table Models, you will be able utalise this customisable technology that can be trained to accurately recognise even irregular tables and detect layout elements on a large scale. These models will be especially useful for documents with multiple text regions, enabling you to achieve a more accurate representation of the documents.
When it comes to tables, the current standard automatic layout analysis and text recognition feature can transcribe the text from different table cells. However the reading order of the transcribed text in the text regions or lines often does not match the original table layout, nor are they represented in table format. While this is fine for simply searching for specific names or terms, transfering the data in a structured form is often very difficult if even possible. It would take time to restructure and organise the transcription to make it useful for building a database.
In contrast to the currently available P2PaLA Models, Table Models require less training data while being more precise. The new Table models are designed to be effectively trained with a limited amount of training material, streamlining the process. This approach has the potential to reduce the amount of time spent creating or adjusting the tables or marking different layout elements on each page. Instead, users can focus on constructing the correct layout shapes to train the model, allowing Transkribus to handle the rest.
It is important to note that Table Models are not an all-in-one or out-of-the-box solution. To achieve optimal results, the models need to be trained similarly to a text recognition model. Soon it will be possible to train a custom layout model not only for complex field layouts, but also for tables in Transkribus.
With a small data set, you can already try out Table Models here on beta.transkribus.eu.
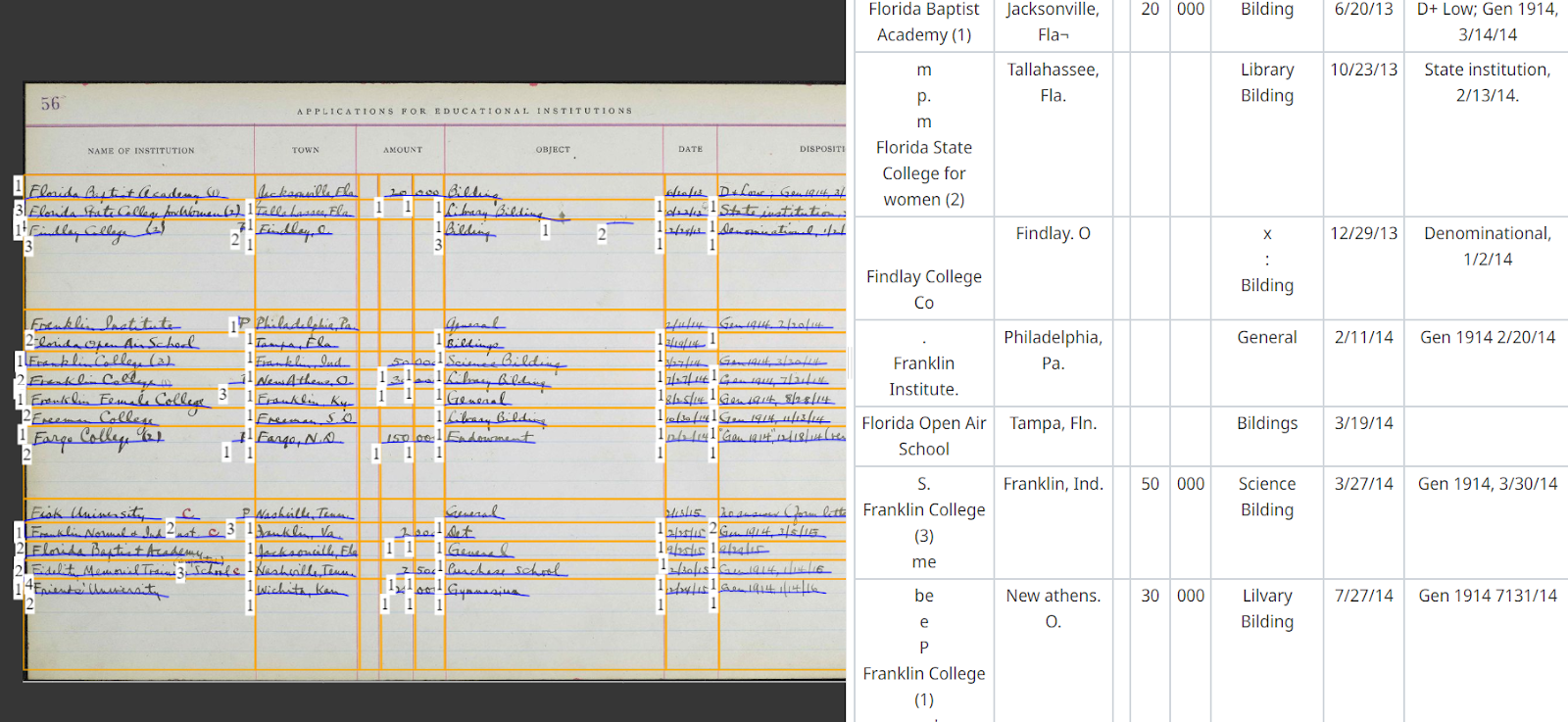
Transkribus Editor: Carnegie Corporation Register of Applications from Educational Institutions, 1911-1920. Via Carnegie Corporation of New York
Training Table Models
The digitisation of tables presents its own unique set of challenges, which our newly developed trainable Table Models are designed to address. Tables, which have been a standard feature in documents across the centuries, from medieval ledgers to modern spreadsheets, come in various formats and can contain critical data.
These new Table Models can handle a diverse range of table types, even those with irregular row heights or widths. To train these models effectively, it’s essential to create a sufficient collection of ground truth pages, ensuring that the models can accurately interpret the tables.
Within the document editor, users have the flexibility to customise how tables are recognised. You can define vertical and horizontal columns and specify what information should be selected within a single row or column. For instance, if the original document only shows vertical separators or merely uses spaces between entries like surnames and names, you can adapt the table creation process accordingly. By adding or omitting columns, you ensure that the Table Models recognise the specific layout and information needed.
Additionally, these models can adapt to changes over time. If the structure of tables within a collection evolves, a second set of Ground Truth data can be added to further train the Tables Models, ensuring the continued accuracy and usefulness of the digitised data.
What’s next?
Since the current version of layout recognition presents some challenges with more complex layouts, we have seen this as an opportunity to not only improve the current layout analysis, but to provide our users with a more targeted solution. With trainable layout models, Transkribus is extending the use of layout analysis to different document formats and layout types. The upcoming trainable Table Models offer flexibility in customising layout recognition and can adapt to layout changes, ensuring accurate interpretation and comprehensive data extraction, even from tables with irregular formats.
The Transkribus Table Models feature is ready to be tried out on a small set of pages here on beta.transkribus.eu. Within the next few weeks the trainable Table Models will be added to our user interface for general use. This update will allow any user to train their own layout model for tables, making the process of document digitisation more efficient and unlocking even more potential within our platform.
Thumbnail:Carnegie Corporation Register of Applications from Educational Institutions, 1911-1920. Via Carnegie Corporation of New York
Understanding historical documents is key to understanding history. But understanding historical documents in Polish can be a challenge. Not only ...
🍪 Some cookies for you 🍪
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.