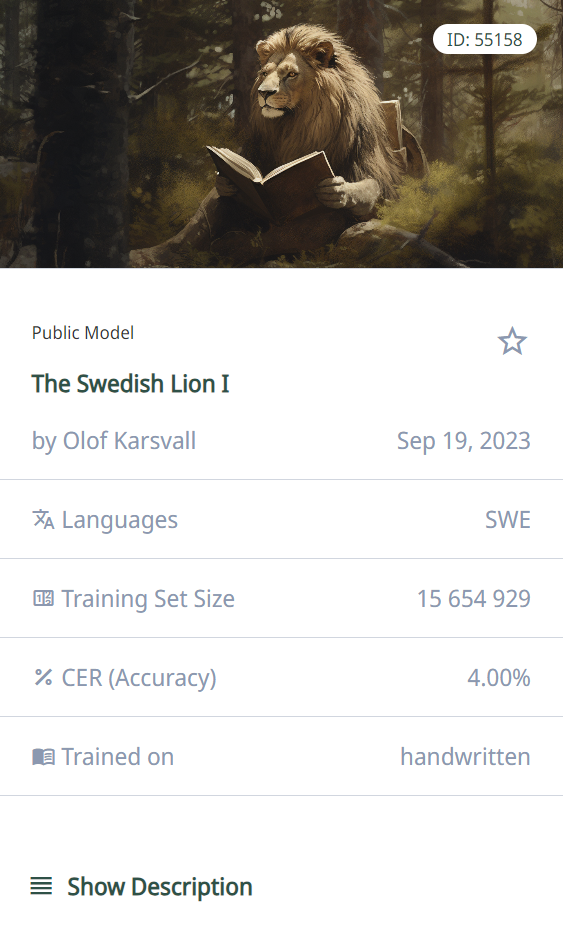
Creating the Swedish Lion Ⅰ text recognition model
READ-COOP SCE
Simplicity, citizen engagement and AI-driven transcription were key factors that intrigued Olof Karsvall and the team at the Swedish National Archives when they discovered Transkribus.
Olof Karsvall, Research Manager at the Swedish National Archives, has been involved in several research projects, most recently the integration of AI, which has revolutionised the research of archival materials. In this blog post, he shares insights into how the Swedish Lion Ⅰ model is supporting this transformative journey.
Archival Material from the Swedish Lion Ⅰ Project.
A collaboration of archives, researchers and universities
The Swedish Lion Ⅰ Handwritten Text Recognition (HTR) model is a collaborative effort involving institutions such as the National Archives of Sweden and Finland, Stockholm City Archives, Jämtlands läns fornskriftsällskap and researchers from Stockholm and Uppsala Universities. “As we collectively focus on generating training data for HTR in Swedish, we recognised the advantages of collaboration. Consequently, we merged our training data to create a joint model”, says Olof Karsvall. Once trained, the Swedish Lion Ⅰ model can automatically transcribe other documents with similar handwriting, making it a valuable tool for digitising and analysing historical manuscripts and archival materials.
At the heart of this collaboration is Transkribus, a platform that allows users to create and train models for specific handwriting styles and historical periods. A key moment came in 2019 when the Stockholm National Archives joined READ-COOP SCE, the cooperative behind Transkribus. Olof Karsvall emphasises, “Primarily, it was the ease of use and the opportunity to engage citizens and volunteers in utilising AI for machine transcription that fascinated us”.
With external funding from the Swedish Innovation Agency (Vinnova), and now most recently from the Swedish National Heritage Board, this fascination evolved into a transformative journey, resulting in innovative projects that bring citizen science together with HTR seamlessly, all made possible by Transkribus. In this way, the Swedish Lion Ⅰ model, together with Transkribus, opens up new possibilities for accessing and researching historical documents.
Archival Material from the Swedish Lion Ⅰ Project and transcription in Transkribus.
Expanding research possibilities
When looking more closely at the history of models, it is always interesting to find out what the aim and motivation behind their creation was. Karsvall explains that “By incorporating texts of diverse types from various historical periods, the goal is for the model to generalise effectively and apply to archival material beyond its original training scope.” To create this model, it was necessary to include a variety of texts from different historical periods. This diversity of training data helps to make the model more effective and applicable to a wide range of archival materials, ensuring better accuracy and performance when transcribing handwritten documents from different periods and styles.
The Swedish Lion Ⅰ is envisioned as a basic model for Swedish historical texts, which will simplify access to handwritten materials and support data-driven research.
The Swedish Lion Ⅰ model for Swedish handwriting.
Training a versatile model
The Swedish Lion Ⅰ model, carefully trained using a wide range of historical documents, particularly court records and minutes from the 1600s, 1700s and 1800s, truly demonstrates the capabilities of Transkribus. Olof Karsvall attests: “Getting started with Transkribus was easy”. The software’s potential can be seen in the collaborative process of transcribing 3.3 million lines of text from 268 archival volumes. The final model was a result of various projects that have created ground truth data utilising specialised models and applying manual corrections The model’s remarkable Character Error Rate (CER) of just 4% confirms the model’s great performance. This is particularly evident in the processing of running text and marginal notes.
Olof Karsvall acknowledges a challenge in managing diverse documents “As we manage a wide array of documents, a significant challenge has been the segmentation of regions and lines.” Fortunately, the introduction of new trainable layout models, the Field Models and Table Models, will bring greater accuracy and easier segmentation and recognition of layout structures. After three years of careful transcription, manual review and correction, the Swedish Lion Ⅰ model is now ready and available as a public model!
The hope is that the Swedish Lion I text recognition model will reach new users via Transkribus and stimulate the usage of historical archive material in Swedish. Its collaborative development, involving several institutions, researchers and volunteers, is already a great inspiration. Karsvall highlights the intention to extend this collaboration, creating a larger model covering older periods and diverse materials, and thereby promoting citizen science. Colleagues and the archival community have already shown growing interest, leading to increased requests to collaborate. The team plans to apply the model on several large collections to meet the expectations of increased accessibility to archives, following the publication of the Swedish Lion Ⅰ model.
Thank you Olof Karsvall for the interview and for sharing the journey of the Swedish Lion Ⅰ model!
Olof Karsvall’s Transkribus Tips:
“seek advice from others who have undertaken similar projects previously”
“share your data; everyone benefits if data can be reused”
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.