- TranskribusTranskribus
Everything about Transkribus
Transkribus AppUse Transkribus in your Browser
Plans & PricingBuy Credits for Handwritten Text Recognition
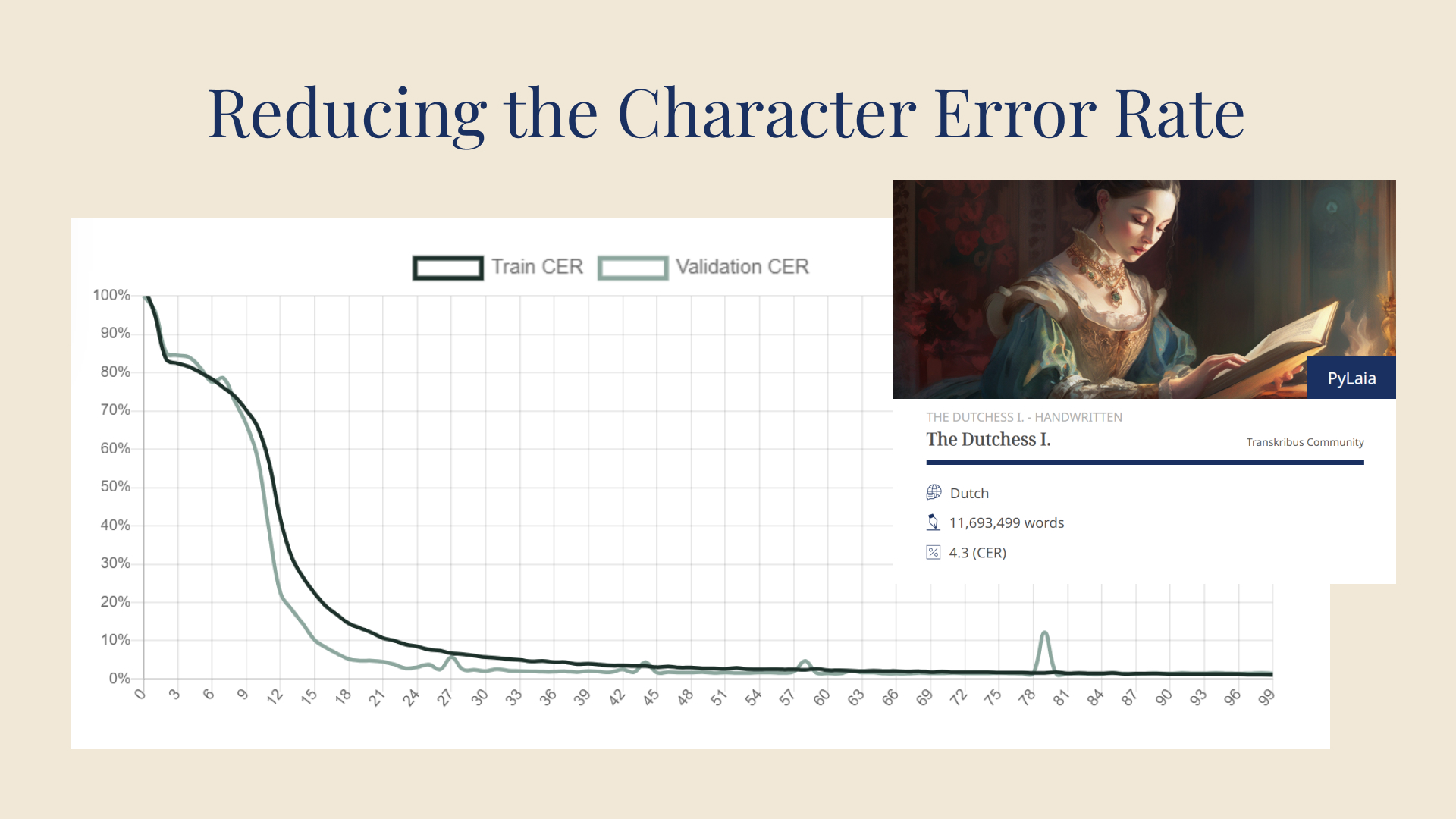
Public AI ModelsExplore all publicly available models
metagrapho apiHandwritten Text Recognition api for Transkribus
Transkribus.aiText recognition with the click of a button
- ScanTent
- read&search
- AboutOur Members
See all of our great Members
Our TeamMeet the READ-COOP Team
Success StoriesHave a look at some exceptional Projects
- Resources
- Plans & Pricing