How to digitise archival materials with Transkribus
April 4, 2023
Transkribus
Think of an archive and you might think of old, dusty basements full of disorganised boxes of papers. But in the technological age, archives are taking on a new role. No longer are they purely physical collections of papers, manuscripts, or physical media, such as photographs or artwork. Instead, archives are becoming fully searchable digital collections, making it easier for researchers and the general public to access historical records and items from anywhere, at any time.
However, digitising an archive in this way is a challenge. A large national archive can hold millions of pages of text, which all have to be transcribed in order to produce digital versions. Previously, this was done manually — each individual word in the document was typed into a computer program by a human being. As you can imagine, transcribing in this way is a very time-consuming process and it would take literally decades to transcribe the millions of archival materials in a large archive.
That’s where Transkribus comes in. Transkribus is an AI-powered platform that uses machine learning to learn how to read a specific type of handwriting, no matter which language the text is in or when it was written. Once the platform can sufficiently recognise the handwriting, it can then transcribe thousands of pages at the click of a button.
In this post, we would like to give you an overview of the different kinds of archival materials which can be transcribed using Transkribus. You will learn how to process materials using the platform and there are also examples of archives which have successfully digitised their collections with Transkribus and made them fit for the future.
There are many different types of archival materials but they all have one thing in common: they are all primary sources. This means they were written at the time a particular historical event took place, usually by someone who was there. Because of this, archival materials are particularly useful for historical research and most items in an archive can be used as scholarly sources. Some of the key types of archival materials include:
Manuscripts: These are any kind of material that is written by hand (“manu scripti” is Latin for “handwritten”). The oldest manuscripts still surviving today are thousands of years old and extremely fragile. Handling archival material such as old manuscripts is a delicate task and so creating digital versions of them makes it possible for everyone to access the contents without damaging the manuscript.
Archival records: These are documents written by individuals or organisations to keep a written account of events such as births, deaths, meetings, finances, and many others. According to the SAA Glossary, the term “archival record” usually denotes unpublished documents, rather than published artefacts such as books.
Letters, diaries, and personal papers: These very important types of material give an insight into the lives of the people who wrote them and the world they were living in at the time. They are particularly useful when studying a single individual or small group.
Organising archival materials is more than just writing a description and putting it on the right shelf. Each item is classified according to several “elements”, which are included in the archival description. These include intellectual elements, such as the name, date and type of material; physical occurrence elements such as the number of pages or location; and the media occurrence element, which covers the media type, colour, dimensions, piece count, and reproduction count. These archival materials elements make it easier for someone to find a certain material and immediately understand its context.
A step-by-step guide to digitising archival materials with Transkribus
Transkribus is an AI-powered platform which converts handwritten or printed text into digital transcriptions. It is used in many different archives around the world to transcribe materials in just a fraction of the time it would take a human being. This allows whole collections to be quickly digitised and made accessible to everyone.
Below is a short overview of how to transcribe materials with Transkribus. For more details, check out our Help Center, which contains detailed information on each step of the process.
Step 1: Create images of the archival materials
To use Transkribus, you need high-quality images or scans of the documents you want to transcribe. These should be in JPEG, PNG or PDF format.
You can create images using anything from sophisticated scanning technology to just your regular smartphone. If you are using this second option, we recommend using a device such as the ScanTent, to ensure optimal lighting and image quality.
Step 2: Sign up to Transkribus
Before you can do any transcribing in Transkribus, you first need to create an account. Go to app.transkribus.eu , click on “Sign up for free” and follow the instructions. Find out more about registration and login in our Help Center.
Step 3: Upload your images
Images are stored in “collections” on Transkribus. You can organise collections however you like. For example, a collection could include all the scans from a certain book or physical collection.
Start your collection by clicking “Tools” and then “Create a collection”. Once the collection has been created, select it on your Workdesk and then click “Upload” from the left-hand toolbar. You can then select the documents you wish to upload.
Your images and data will be stored on the servers of READ-COOP SCE, which are all located in Innsbruck, Austria, in a GDPR-compliant manner, and may be processed according to our terms & conditions. If data cannot leave your infrastructure for privacy reasons, check our On-Prem solution (https://readcoop.eu/transkribus/on-prem/).
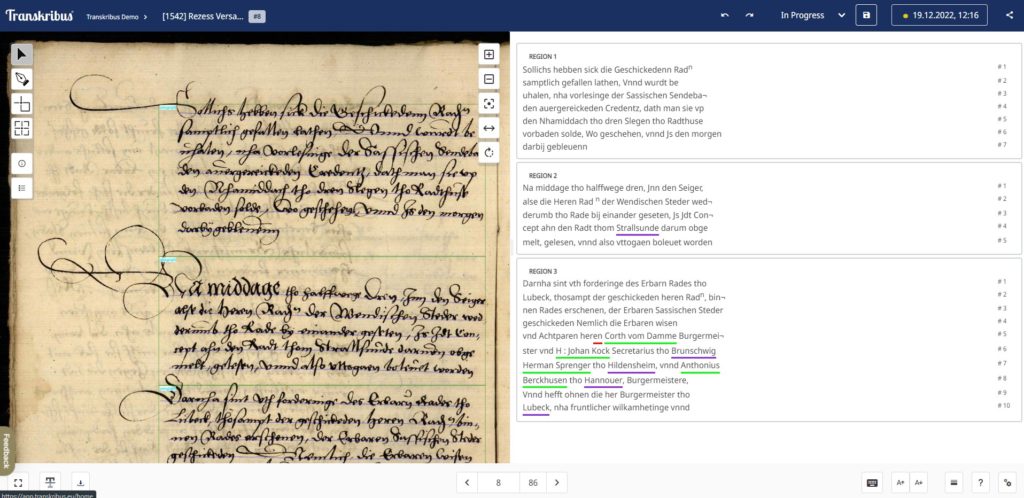
Open your collection and select a particular image. Click “Start automatic transcription” to begin the transcription process.
You will then need to select a model. This is a piece of code that contains all the information Transkribus needs to transcribe the text accurately. There are over 100 public models available, covering different languages and time periods. Select the one that is most relevant to your material and then click “Start”.
Once the processing is complete, the automatic transcription will appear on the right side of the screen. Find out more about automatically transcribing documents in our Help Center.
How to improve the accuracy and efficiency of your transcriptions
Public models like the ones described above are trained to transcribe a broad range of archival materials with reasonable accuracy. However, if you want to improve the accuracy or efficiency of your transcriptions, here are a couple of tips.
Check the quality of your scans
The better the quality of your scans, the better the automatic transcriptions will be. Therefore, it makes sense to check that all the text on your scans is clearly legible — as mentioned above, good lighting when taking the images helps a lot here. You should also make sure that there are no marks or other “noise” which might affect how Transkribus processes them.
Finally, check that all the scans were uploaded with the correct orientation (portrait or landscape), as this will also have an impact on the layout recognition. Rotate any incorrect scans back to their original orientation and re-upload them to Transkribus.
Improve layout recognition
Before the text can be recognised, Transkribus first needs to know where on the page the text is located. It does this using layout recognition. This analyses which parts of the document contain text and visibly marks each individual line. It is these lines of text which are then recognised by the platform.
However, that also means that if the layout recognition is incorrect, then the text will also be incorrectly transcribed. Therefore, any errors in the layout recognition must be corrected manually to ensure an accurate transcription. If you have a material based on a table — for example, a birth register — then you can also programme this separately into Transkribus, so that the platform recognises the rows and columns correctly.
Transkribus doesn’t just provide public models, it allows you to train custom models, too. These are models that are tailor-made to your individual materials, resulting in more accurate transcriptions.
To train a custom model, you first need to manually transcribe around 5,000-15,000 words, depending on the complexity of the handwriting. Transkribus will then use this transcribed material to learn how to read the handwriting and create a model so that it can recognise similar texts in the future.
Many archives train custom models to recognise a specific type of collection, for example, council records from a particular time period or notarial deeds written by a select group of notaries. This allows the collections to be transcribed much more accurately, with less post-editing required afterwards. Find out more about training models in our Help Center.
3 archives that have successfully digitised their materials with Transkribus
Archives around the world have used Transkribus to transcribe many different types of materials and create digital versions of them. For more information about some of our most successful archival projects, check out the blog articles below.
Transcribing 3 million scans at the National Archives of the Netherlands
The National Archives of the Netherlands is home to literally millions of pages of material, both printed and handwritten. As part of their digitisation strategy, the archives used Transkribus to transcribe 3 million pages of records and notarial deeds from the 17th-19th centuries. The custom model they trained is also now available to all as a public model. Find out more about the project here.
Creating a digital scholarly edition of the Lovelace papers
Housed at the Bodleian Library in Oxford, the Lovelace papers are the private letters and memos of 19th-century mathematician Ada Lovelace. There are around 14,000 pages in all, which researcher Jessica Cook is using to train a custom model tailored to Lovelace’s individual handwriting, as well as the handwriting of other contributors, such as her husband and mother. Find out more about the project here.
How the State Archives of Zurich published 50,000 pages online
The State Archives of Zurich is a mine of historical information about the Swiss city. However, physically accessing the archive’s premodern collection was a challenge, prompting the archive to create a digital version which could be easily accessed online. Thanks to an accurate model, the team was able to transcribe and publish 50,000 pages of council minutes in just three years. Find out more about the project here.
Try Transkribus for yourself
Transkribus is an AI-powered platform that transcribes handwritten text at the push of a button.
You can try the full version of Transkribus at app.transkribus.eu or try our demo version below.
Understanding historical documents is key to understanding history. But understanding historical documents in Polish can be a challenge. Not only ...
🍪 Some cookies for you 🍪
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.