Transcribing 3 million scans at the National Archives of the Netherlands
READ-COOP SCE
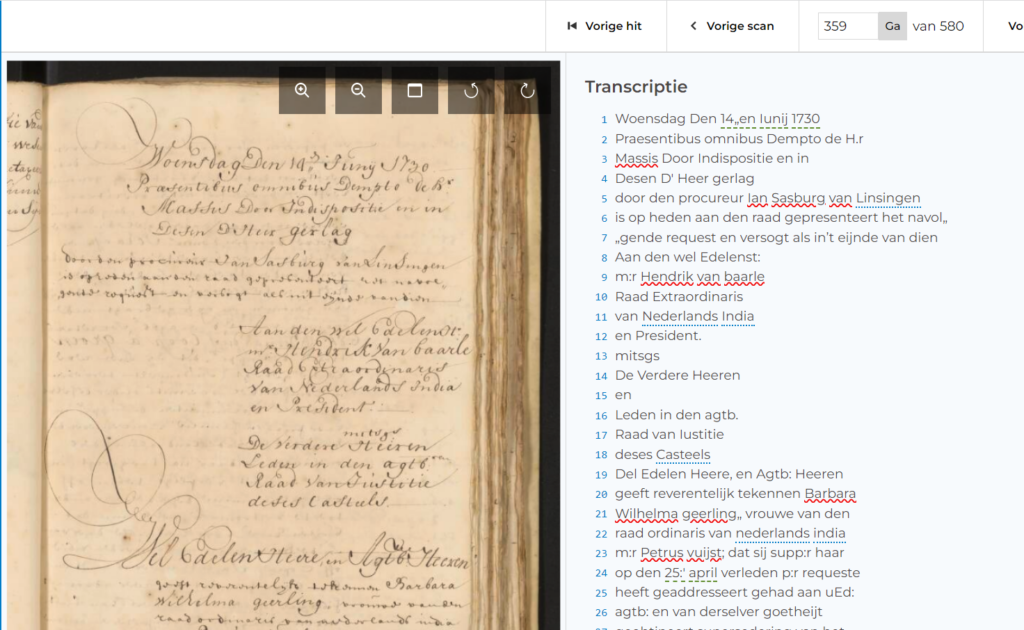
Some Transkribus projects are just a few pages long. Many are a few hundred or thousand pages long. But the latest Transkribus project at the National Archives of the Netherlands involved a whopping 3 million pages of documents. And this is just the beginning. Over the next few years, the Dutch archive aims to scan about 10% of its entire collection—that’s more than 10 million scans a year—and transcribe at least a part of the collection to make it more accessible.
We spoke to Liesbeth Keijser, Project Manager for Digitisation at the National Archives of the Netherlands, to discover more about digitising such large collections of documents with Transkribus.
Welcome to the National Archives of the Netherlands
Based in the Dutch coastal city of The Hague, the National Archives of the Netherlands is the country’s largest archive. It is home to hundreds of years of governmental and official documents, as well as private documents relevant to the history of the Netherlands. Millions of pages are looked after at the archive. In fact, the collection is so large that if you were to line it all up in a row, it would stretch for over 140km!
However, most of the archive’s documents are still paper-based, which makes accessing them difficult in two ways. Firstly, you have to travel to The Hague to browse the archive. Secondly, and probably more importantly, there is no way to quickly search whole collections for specific information. Instead of simply typing a search term into a database, you have to manually search through collections of papers, which is infinitely more time-consuming.
With that in mind, the National Archives embarked on an ambitious digitisation strategy. “Our plan is to scan 10% of our archives over the next 15 years,” digitisation manager Liesbeth explained. “That will add up to more than 100 million scans in a couple of years.”
To make the scans more accessible, the archive is using handwritten text recognition technology to automatically transcribe the handwritten text and convert it into a digital text file. They decided to start with a collection of 3 million pages, mainly records regarding the Dutch East India Company in the 17th and 18th centuries and notarial deeds from the 19th century. This first project would set the groundwork for later parts of the digitisation strategy.
Creating an AI model with Transkribus
The National Archives started working with handwriting recognition technology about five years ago and the team have been pleasantly surprised by how easy it is. “Using Transkribus and creating a custom AI model was actually quite straightforward,” Liesbeth said. At the start, we were aiming for a CER [character error rate] of 20%, we would have been happy with that. But after creating 6000 pages of training data, we got down to a CER of 7%, which was even better for us.”
In keeping with Transkribus’ cooperative values, Liesbeth’s team also decided to make their AI model public, so that other people can benefit from their work. Their model, Dutch Handwriting 17th-19th century, now contains almost 1.5 million words and can be used by any Transkribus user working with similar documents.
Publishing the transcriptions
For Liesbeth and her team, the transcription was actually the less complicated step of the project. “Transcribing everything was the easy part,” she explained. “Publishing everything online was a lot more complex, both from an archival and a technical perspective.” Deciding how to organise everything into a logical online format was one challenge, finding people with the right development skills to build exactly what the archive needed was yet another.
After considering different solutions, the team decided to build a custom system divided into a back end and a separate front end by two suppliers. The result was the “Zoeken in transcripties” platform. Although the project is still ongoing, the platform already provides access to a wealth of documents, making it much easier for researchers and interested persons to find the information they need. The team also added named entity recognition to the system, so that it would automatically enrich the transcriptions with named entities such as people and places.
“Ideally, we would have a platform that integrates seamlessly with our existing IT infrastructure. That isn’t quite possible yet, but we are still pretty happy with the results so far.”
The benefits of digitisation
And it is not just Liesbeth’s team who is happy with the new digitised collection. “We’re still collating exact data about user satisfaction, but our impression is that people like the new system.”
“A good example of this was the bittersweet feedback we got from some academic researchers. They really liked that so many documents were suddenly so easily accessible. But because they suddenly had so many new sources to work with, they realised they had to scrap their current conclusions and start again. I think this shows just how much impact a digitisation project like this can have on academic research.”
Thank you, Liesbeth, for talking to us!
Liesbeth’s Transkribus Tip:
“When embarking on a project like this, make sure there is someone in your team who has a background in AI. It is hard to compare different technologies if you don’t understand the differences between them, so make sure the team has that knowledge before you start.”
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.