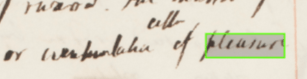+ Searching Jeremy Bentham’s manuscripts with Keyword Spotting
October 15, 2018
Data sets, HTR models, Keyword Spotting, News, Success stories, Transkribus
The Bentham Project has been experimenting with the Handwritten Text Recognition (HTR) of Bentham’s manuscripts for the past five years, first as a partner in the tranScriptorium project and now as part of READ .
The results have thus far been impressive, especially considering the immense difficulty of Bentham’s own handwriting. But automated transcription is not yet at a point where it is sufficiently accurate to be used by Bentham Project researchers as a basis for scholarly editing.
However, the current state of the technology is strong enough for keyword searching! And thanks to a collaboration with the PRHLT research center at the Universitat Politècnica de València (another partner in the READ project), there are some exciting new results to report. It is now possible to search over 90,000 digital images of the central collections of Bentham’s manuscripts, which are held at Special Collections University College London and The British Library.
A Google sheet has been prepared with some suggested search terms in 5 different spreadsheet tabs (Bentham’s neologisms, concepts, people, places and other). The Bentham Project is appealing for people to record their searches online, using the suggested search terms and some new ones too. Some of the results will be shared at the upcoming Transkribus User Conference in November.
Background
The PRHLT team have processed the Bentham papers with cutting-edge HTR and probabilistic word indexing technologies. This sophisticated form of searching is often called Keyword Spotting. It is more powerful than a conventional full-text search because it uses statistical models trained for text recognition to search through probability values assigned to character sequences (words), considering most possible readings of each word on a page.
The result is that this vast collection of Bentham’s papers can be efficiently searched, including those papers that have not yet been transcribed! The accuracy rates are impressive. The spots suggest around 84-94% accuracy (6-16% Character Error Rate) when compared with manual transcriptions of Bentham’s manuscripts. More precisely speaking, laboratory tests show that the word average search precision ranges from 79% to 94%. This means that, out of 100 average search results, only as few as 6 may fail to actually be the words searched for. The accuracy of spotted words depends on the difficulty of Bentham’s handwriting – although it is possible to find useful results in Bentham’s scrawl! There could be as many as 25 million words waiting to be found.
A search for the word ‘happiness’ uncovers Bentham’s most famous phrase, written in his own hand.
Use cases
This fantastic site will be invaluable to anyone interested in Bentham’s philosophy. It will help Bentham Project researchers to find previously unknown references in pages that have not yet been transcribed. It will allow researchers to quickly investigate Bentham’s concepts and correspondents. It should also help volunteer transcribers in the Transcribe Bentham initiative to find interesting material to transcribe.
This interface is a prototype beta version. In the future, there are plans to increase the power of this research tool by connecting it to other digital resources, allowing users to quickly search the manuscripts at the UCL library repository, the Bentham papers database and the Transcribe Bentham Tanscription Desk and linking these images to rich existing metadata.
Understanding historical documents is key to understanding history. But understanding historical documents in Polish can be a challenge. Not only ...
🍪 Some cookies for you 🍪
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.