Der Weg zur Erkennung von handgeschriebenem Text - Teil 1
Felix Dietrich
Vor 2 Jahren
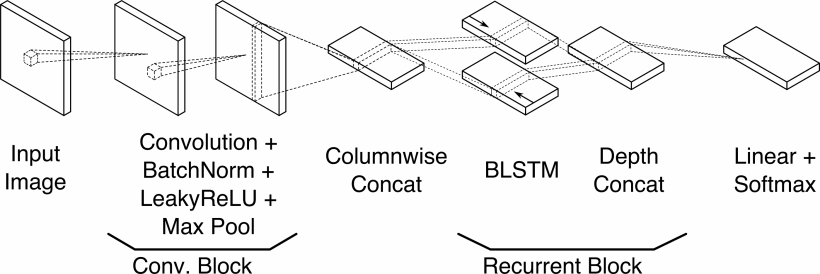
In diesem Artikel werden wir uns einen der Ansätze zur automatischen Erkennung von handgeschriebenen Texten genauer ansehen: PyLaia. Es ist ein Nachfolger von Laia, der 2018 von Joan Puigcerver und Carlos Mocholí entwickelt wurde. In der einfachsten Beschreibung nimmt es ein Bild von Text als Eingabe und erzeugt die entsprechenden Zeichen als Ausgabe. Der Kern dieses Algorithmus ist ein tiefes neuronales Netz, dessen Komponenten jedoch etwas anspruchsvoller sind als die eines einfachen Perzeptrons (siehe unsere Einführung in neuronale Netze hier). Die gesamte Modellarchitektur ist in der nachstehenden Abbildung zusammengefasst, aber um sie zu verstehen, müssen wir uns zunächst einige der größten Fortschritte beim Deep Learning im letzten Jahrzehnt genauer ansehen.
Die erste Stufe besteht aus sogenannten Conv. Blöcken, oder Faltungsblöcken. Wir sprachen bereits über diese in einem anderen ArtikelAber lassen Sie uns einen genaueren Blick auf das werfen, was tatsächlich passiert. In einer Faltungsschicht wird das Eingabebild mit einer Kernel, die im Wesentlichen nur eine Zahlenmatrix ist. Da die rohen Bilddaten ebenfalls als eine Matrix numerischer Pixelwerte betrachtet werden können, läuft der gesamte Vorgang der Faltung auf eine riesige Anzahl von Matrixmultiplikationen hinaus, bei denen der Kernel über das gesamte Bild gleitet - Spalte für Spalte und Zeile für Zeile -, um einen neuen Satz von Pixelwerten zu erzeugen. In den alten Tagen der Bildverarbeitung wurden diese Kernel manuell entwickelt, um bestimmte Aufgaben zu erfüllen, z. B. die Kantenerkennung. Der folgende Kernel tut genau das: Er erkennt vertikale Kanten, indem er über alle 3×3-Pixel-Unterbilder des Originalbildes streicht. Traditionell könnte dies der erste Schritt in einem komplizierten, manuell kodierten Algorithmus sein, der versucht, Objekte in einem Bild zu finden. Früher war dies jedoch so schwierig, dass selbst die ausgefeiltesten Algorithmen nicht zuverlässig waren. differenzierte Bilder von Katzen und Hunden.
Dann, vor etwa 10 Jahren, änderte sich alles. Das ImageNet-Projekt, das einen der größten Bilderkennungswettbewerbe durchführt, verzeichnete plötzlich enorme Fortschritte bei seinen Spitzenkandidaten. Bei diesem Wettbewerb müssen die Algorithmen mehrere tausend Objektklassen in einem Datensatz erkennen, der Millionen von handbeschrifteten Bildern umfasst. Einer der berühmtesten Gewinner, AlexNetist ein tiefes neuronales Netz, das Wahrscheinlichkeitsschätzungen für jede einzelne Klasse liefert. Es hat es geschafft, 63% aller Bilder richtig zu klassifizieren (d. h. der richtigen Klasse die höchste Wahrscheinlichkeit zuzuordnen), und bei fast 85% aller Bilder war die richtige Klasse zumindest unter den Top 5 der AlexNet-Vorhersagen. Solche Zahlen wurden noch vor wenigen Jahren für völlig unmöglich gehalten. Wie war dies also möglich? Es stellte sich heraus, dass man Kernel als abstimmbare Parameter in einem neuronalen Netz festlegen kann, so dass das Modell bei ausreichenden Trainingsdaten einfach die richtigen Matrizen lernt.
Selbst erlernte Faltungskerne in der ersten Schicht von AlexNet (Krizhevsky et al.)
Durch den Einsatz von GPU-beschleunigtem Rechnen konnten diese Art von neuronalen Netzen plötzlich in wenigen Stunden lernen, was Menschen in vielen Jahrzehnten nicht herausfinden konnten. In den nächsten Jahren wurden die Convnet-Architekturen immer weiter verfeinert. Einen großen Anteil daran hatte die Einführung der so genannten restliche Netze, bei denen die Ausgaben der Schichten manchmal die Schichten umgingen, um dann zu einem späteren Zeitpunkt wieder eingespeist zu werden. Dies verbesserte die Trainingseffizienz erheblich, da die Netze immer tiefer wurden, um höhere Abstraktionsebenen zu erfassen. Schließlich führten diese Entwicklungen zu Modellen, die den durchschnittlichen Menschen bei einer Vielzahl von Bilderkennungsaufgaben übertreffen konnten. Heute ist eine genaue Bildklassifizierung mit Hilfe von Faltungsnetzen fast trivial geworden. Dank moderner Softwarebibliotheken und GPU-Anbietern, die auf den Zug aufgesprungen sind, kann die Bildklassifizierung fast als gelöstes Problem betrachtet werden. Darüber hinaus ist es dank Konzepten wie Feinabstimmung und Transferlernen sogar möglich, Probleme mit vergleichsweise geringen Mengen an Trainingsdaten zu lösen. Was wollen wir also noch erreichen, wenn es um Texterkennung geht? Hätten wir es nur mit Bildern von einzelnen Buchstaben oder Zahlen zu tun, wäre unsere Geschichte hier zu Ende. Deren korrekte Kennzeichnung ist in der Tat trivial. Aber handgeschriebener Text ist komplizierter. Erstens gibt es fast unendlich viele Handschriften, und die Modelle lassen sich in der Regel nicht gut auf Texte verschiedener Autoren übertragen. Hinzu kommt, dass selbst für das geschulte menschliche Auge bestimmte Zeichen nur im Kontext eines Wortes oder vielleicht eines ganzen Satzes einen Sinn ergeben können. Um genauere HTR-Vorhersagen zu erhalten, müssen wir also über die reine Bildklassifizierung hinausgehen und auch die Verarbeitung natürlicher Sprache berücksichtigen. In Teil 2 dieser Serie werden wir einen genaueren Blick auf die anderen großen Fortschritte beim Deep Learning werfen: rekurrente neuronale Netze.
Wir verwenden Cookies, um Inhalte und Dienste zu personalisieren und zu verbessern, relevante Werbung zu liefern und die Sicherheit unserer Nutzer zu erhöhen. Sie können Ihre Cookie-Einstellungen jederzeit überprüfen. Weitere Informationen über die Verwendung von Cookies und Cookie-Einstellungen finden Sie in unserem Privacy policy Cookie settingsRejectAccept
Datenschutz & Cookies-Richtlinie
Datenschutz Übersicht
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die als notwendig eingestuften Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der grundlegenden Funktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Ablehnen einiger dieser Cookies kann jedoch Auswirkungen auf Ihr Surferlebnis haben.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Kategorie umfasst nur Cookies, die grundlegende Funktionalitäten und Sicherheitsmerkmale der Website gewährleisten. Diese Cookies speichern keine persönlichen Informationen.
Cookie
Beschreibung
Dauer
viewed_cookie_policy
Das Cookie wird vom GDPR Cookie Consent Plugin gesetzt und dient dazu, zu speichern, ob der Benutzer der Verwendung von Cookies zugestimmt hat oder nicht. Es speichert keine persönlichen Daten.
1 Stunde
PHPSESSID
Dieses Cookie ist in PHP-Anwendungen enthalten. Der Cookie wird verwendet, um die eindeutige Sitzungs-ID eines Benutzers zu speichern und zu identifizieren, um die Benutzersitzung auf der Website zu verwalten. Das Cookie ist ein Sitzungscookie und wird gelöscht, wenn alle Browserfenster geschlossen werden.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Beschreibung
Dauer
BESUCHER_INFO1_LIVE
Dieses Cookie wird von Youtube gesetzt. Wird verwendet, um die Informationen der eingebetteten Youtube-Videos auf einer Website zu verfolgen.
5 Monate
IDE
Wird von Google DoubleClick verwendet und speichert Informationen darüber, wie der Nutzer die Website und andere Werbung vor dem Besuch der Website nutzt. Dies wird verwendet, um Nutzern Anzeigen zu präsentieren, die für sie entsprechend dem Nutzerprofil relevant sind.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Beschreibung
Dauer
GPS
Dieses Cookie wird von Youtube gesetzt und registriert eine eindeutige ID für die Nachverfolgung von Benutzern basierend auf ihrem geografischen Standort
30 Minuten
tk_oder
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
5 Jahre
tk_r3d
Das Cookie wird von JetPack installiert. Wird für die internen Metriken für Benutzeraktivitäten verwendet, um die Benutzererfahrung zu verbessern
3 Tage
tk_lr
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
1 Jahr
_ga
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Besucher-, Sitzungs- und Camapign-Daten zu berechnen und die Nutzung der Website für den Analysebericht der Website zu verfolgen. Die Cookies speichern Informationen anonym und weisen eine zufällig generierte Nummer zu, um eindeutige Besucher zu identifizieren.
2 Jahre
_gid
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Informationen darüber zu speichern, wie Besucher eine Website nutzen, und hilft bei der Erstellung eines Analyseberichts darüber, wie sich die Website verhält. Die gesammelten Daten umfassen die Anzahl der Besucher, die Quelle, von der sie kommen, und die besuchten Seiten in anonymer Form.
1 Tag
matomo
Für die statistische Analyse verwenden wir auf dieser Website "Matomo". Dies ist ein Open-Source-Tool für die Webanalyse. Matomo überträgt keine Daten an Server außerhalb der Kontrolle von READ-COOP. Matomo ist deaktiviert, wenn Sie unsere Website besuchen. Nur wenn Sie aktiv zustimmen, wird Ihr Nutzungsverhalten anonymisiert erfasst.
1 Jahr
Hubspot
Hubspot, Inc. 25 First Street, Cambridge, MA 02141 USA
HubSpot ist ein Dienst zur Verwaltung von Benutzerdatenbanken, der von HubSpot, Inc. bereitgestellt wird. Wir verwenden HubSpot auf dieser Website für unsere Online-Kundensupport-Aktivitäten.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Beschreibung
Dauer
YSC
Dieses Cookie wird von Youtube gesetzt und dient dazu, die Aufrufe von eingebetteten Videos zu verfolgen.
1 Jahr
_gat
Dieses Cookie wird von Google Universal Analytics installiert, um die Abfragerate zu drosseln und so die Datensammlung auf stark frequentierten Seiten zu begrenzen.






{kind=link}