La strada per il riconoscimento del testo scritto a mano - Parte 1
Felix Dietrich
2 anni fa
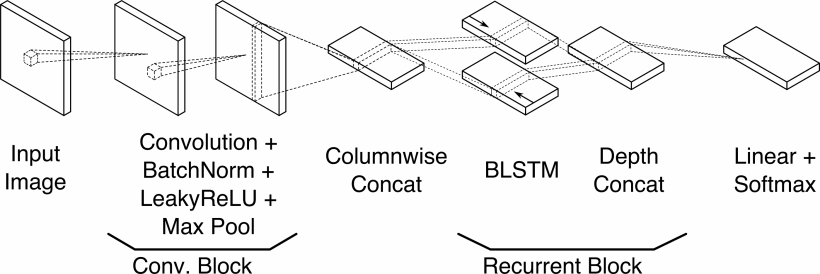
In questo articolo, esamineremo da vicino uno degli approcci al riconoscimento automatico del testo scritto a mano: PyLaia. Si tratta del successore di Laia, realizzato nel 2018 da Joan Puigcerver e Carlos Mocholí. Nella descrizione più semplificata, prende in input un'immagine di testo e genera in output i caratteri corrispondenti. Al centro di questo algoritmo si trova una rete neurale profonda, ma i suoi componenti sono leggermente più sofisticati di quelli di un semplice perceptron (vedi la nostra introduzione alle reti neurali qui). L'intera architettura del modello è riassunta nell'immagine sottostante, ma per comprenderla dobbiamo prima dare un'occhiata più da vicino ad alcuni dei maggiori progressi nel deep learning degli ultimi dieci anni.
Il primo stadio consiste nei cosiddetti Conv. Blocks, o blocchi convoluzionali. Abbiamo già parlato di questi in un altro articoloma diamo un'occhiata più da vicino a ciò che accade in realtà. In uno strato convoluzionale, l'immagine in ingresso viene convoluta con un kernel, che è essenzialmente una matrice di numeri. Poiché anche i dati grezzi dell'immagine possono essere considerati una matrice di valori numerici dei pixel, l'intera operazione di convoluzione si riduce a un numero enorme di moltiplicazioni matriciali, in cui il kernel scorre sull'intera immagine - colonna per colonna e riga per riga - per produrre una nuova serie di valori dei pixel. Ai vecchi tempi dell'elaborazione delle immagini, si progettavano manualmente questi kernel per ottenere compiti specifici, ad esempio il rilevamento dei bordi. Il kernel qui sotto fa esattamente questo: rileva i bordi verticali passando in rassegna tutte le sotto-immagini di 3×3 pixel contenute nell'immagine originale. Tradizionalmente, questo potrebbe essere il primo passo di un complicato algoritmo codificato manualmente che cerca di trovare gli oggetti in un'immagine. In passato, tuttavia, questa operazione era così difficile che anche gli algoritmi più sofisticati non riuscivano a trovare in modo affidabile gli oggetti in un'immagine. differenziare le immagini di cani e gatti.
Kernel di rilevamento dei bordi
Fonte Immagine
Valori dei pixel
Risultato della convoluzione con il kernel di rilevamento dei bordi
Poi, circa 10 anni fa, tutto è cambiato. Il progetto ImageNet, che gestisce uno dei più grandi concorsi di riconoscimento delle immagini, ha improvvisamente registrato enormi progressi tra i suoi principali concorrenti. In questo concorso, gli algoritmi devono individuare diverse migliaia di classi di oggetti in un set di dati che comprende milioni di immagini etichettate a mano. Uno dei vincitori più famosi, AlexNetè una rete neurale profonda che fornisce stime di probabilità per ogni singola classe. È riuscita notoriamente a classificare correttamente 63% di tutte le immagini (cioè a dare alla classe corretta la massima probabilità) e per quasi 85% di tutte le immagini, la classe vera era almeno tra le prime 5 delle previsioni di AlexNet. Numeri del genere erano considerati del tutto impossibili solo pochi anni prima. Come è stato possibile? Si è scoperto che è possibile designare i kernel come parametri regolabili all'interno di una rete neurale, consentendo essenzialmente al modello di apprendere le matrici giuste quando gli vengono forniti dati di addestramento sufficienti.
Kernel convoluzionali autoappresi nel primo strato di AlexNet (Krizhevsky et al.)
Utilizzando il calcolo accelerato dalle GPU, questi tipi di reti neurali potevano improvvisamente imparare in poche ore ciò che gli esseri umani non erano riusciti a capire in molti decenni. Nei due anni successivi, le architetture di convnet sono state sempre più perfezionate. Una parte importante è stata l'introduzione delle cosiddette residuo in cui le uscite degli strati a volte bypassavano gli strati per poi essere reinserite in un secondo momento. Ciò ha migliorato notevolmente l'efficienza dell'addestramento, in quanto le reti sono diventate sempre più profonde per comprendere livelli di astrazione più elevati. Alla fine, questi sviluppi hanno dato vita a modelli in grado di battere l'uomo medio in un'ampia gamma di compiti di riconoscimento delle immagini. Oggi, una classificazione accurata delle immagini utilizzando reti convoluzionali sta diventando quasi banale. Grazie alle moderne librerie software e ai fornitori di GPU, la classificazione delle immagini può essere considerata un problema quasi risolto. Inoltre, grazie a concetti come il fine-tuning e l'apprendimento per trasferimento, è possibile risolvere i problemi con quantità relativamente piccole di dati di addestramento. Cosa stiamo ancora cercando di ottenere quando si tratta di riconoscimento del testo? Se avessimo a che fare solo con immagini di singole lettere o numeri, la nostra storia finirebbe qui. Etichettarli correttamente è infatti banale. Ma il testo scritto a mano è più complicato. Innanzitutto, esistono quasi infiniti stili di scrittura e i modelli di solito non si trasferiscono bene tra testi di autori diversi. Inoltre, anche per l'occhio umano allenato alcuni caratteri possono avere senso solo nel contesto di una parola o forse di un'intera frase. Pertanto, per ottenere previsioni HTR più accurate, dobbiamo andare oltre la semplice classificazione delle immagini e considerare anche l'elaborazione del linguaggio naturale. Nella seconda parte di questa serie, daremo un'occhiata più da vicino agli altri grandi progressi del deep learning: reti neurali ricorrenti.
Utilizziamo i cookie per personalizzare e migliorare i contenuti e i servizi, fornire pubblicità pertinente e migliorare la sicurezza dei nostri utenti. È possibile controllare le impostazioni dei cookie in qualsiasi momento. Per ulteriori informazioni sull'uso dei cookie e sulle impostazioni dei cookie, consultare il nostro Privacy policy Cookie settingsRejectAccept
Politica sulla privacy e sui cookie
Panoramica sulla privacy
Questo sito web utilizza i cookie per migliorare la tua esperienza durante la navigazione nel sito. Di questi cookie, quelli classificati come necessari vengono memorizzati nel tuo browser, perché sono essenziali per il funzionamento delle funzionalità di base del sito web. Utilizziamo anche cookie di terze parti che ci aiutano ad analizzare e capire come utilizzi questo sito web. Questi cookie vengono memorizzati nel tuo browser solo con il tuo consenso. Hai anche la possibilità di rinunciare a questi cookie. Ma l'opt-out di alcuni di questi cookie può avere un effetto sulla tua esperienza di navigazione.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questa categoria comprende solo i cookie che assicurano le funzionalità di base e le caratteristiche di sicurezza del sito web. Questi cookie non memorizzano alcuna informazione personale.
Cookie
Descrizione
Durata
politica dei cookie visualizzati
Il cookie è impostato dal plugin GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
1 ora
PHPSESSID
Questo cookie è nativo delle applicazioni PHP. Il cookie viene utilizzato per memorizzare e identificare l'ID di sessione unico di un utente allo scopo di gestire la sessione dell'utente sul sito web. Il cookie è un cookie di sessione e viene cancellato quando tutte le finestre del browser vengono chiuse.
I cookie pubblicitari sono utilizzati per fornire ai visitatori annunci pertinenti e campagne di marketing. Questi cookie tracciano i visitatori attraverso i siti web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Descrizione
Durata
VISITATORE_INFO1_LIVE
Questo cookie è impostato da Youtube. Utilizzato per tracciare le informazioni dei video di YouTube incorporati in un sito web.
5 mesi
IDE
Utilizzato da Google DoubleClick e memorizza le informazioni su come l'utente utilizza il sito web e qualsiasi altra pubblicità prima di visitare il sito. Questo viene utilizzato per presentare agli utenti gli annunci che sono rilevanti per loro in base al profilo dell'utente.
I cookie analitici sono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, la frequenza di rimbalzo, la fonte del traffico, ecc.
Cookie
Descrizione
Durata
GPS
Questo cookie è impostato da Youtube e registra un ID unico per tracciare gli utenti in base alla loro posizione geografica
30 minuti
tk_or
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
5 anni
tk_r3d
Il cookie è installato da JetPack. Utilizzato per le metriche interne delle attività dell'utente per migliorare l'esperienza dell'utente
3 giorni
tk_lr
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
1 anno
{\an8}Che cosa?
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per calcolare i dati del visitatore, della sessione, del camapign e per tenere traccia dell'utilizzo del sito per il rapporto di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato randoly per identificare i visitatori unici.
2 anni
_gid
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per memorizzare informazioni su come i visitatori utilizzano un sito web e aiuta a creare un rapporto analitico su come sta andando il sito web. I dati raccolti includono il numero di visitatori, la fonte da cui provengono e le pagine visitate in forma anonima.
1 giorno
matomo
Per l'analisi statistica, usiamo "Matomo" su questo sito web. Si tratta di uno strumento open source per l'analisi del web. Matomo non trasmette dati a server al di fuori del controllo di READ-COOP. Matomo viene disattivato quando si visita il nostro sito web. Solo se lei acconsente attivamente, il suo comportamento d'uso viene registrato in modo anonimo.
1 anno
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot è un servizio di gestione di database di utenti fornito da HubSpot, Inc. Su questo sito web utilizziamo HubSpot per le nostre attività di assistenza clienti online.
I cookie di performance sono utilizzati per capire e analizzare gli indici di performance chiave del sito web che aiuta a fornire una migliore esperienza utente per i visitatori.
Cookie
Descrizione
Durata
YSC
Questo cookie è impostato da Youtube e viene utilizzato per monitorare le visualizzazioni dei video incorporati.
1 anno
_gat
Questo cookie è installato da Google Universal Analytics per strozzare il tasso di richiesta per limitare la raccolta di dati su siti ad alto traffico.






{kind=link}