Warum es mehr als 60 Jahre gedauert hat, bis KI sich durchgesetzt hat
Felix Dietrich
Vor 3 Jahren
Eine kleine Einführung in Deep Learning
Die Theorie hinter dem so genannten Perzeptron, dem wichtigsten Baustein künstlicher neuronaler Netze und damit aller modernen Deep Learning- oder "KI"-Modelle, ist fast so alt wie der Transistor. Wenn diese Algorithmen also so alt sind wie die Computer selbst, warum hat es dann mehr als ein halbes Jahrhundert gedauert, bis sie die Hauptbühne der Wissenschaft und Technologie betreten haben? Die Antwort lautet: Es ist kompliziert. Im wahrsten Sinne des Wortes. Bestehende Modelle auszuführen ist relativ einfach, aber sie zu trainieren ist es nicht. Vor allem dann nicht, wenn man Anwendungen in der realen Welt im Sinn hat. Doch bevor wir uns einige der Durchbrüche ansehen können, die uns dorthin gebracht haben, wo wir heute stehen, sollten wir einen Schritt zurücktreten und verstehen, wie künstliche neuronale Netze eigentlich funktionieren. Der erste Schritt bei der Nachbildung des Gehirns in einem Computer besteht natürlich darin, sich anzuschauen, wie das Gehirn seine Rechenleistung erbringt. Unten sehen Sie eine Skizze eines Neurons, der grundlegenden Rechenkomponente des Nervensystems praktisch aller Tiere.
Diagramm eines Neurons | Quelle: Wikipedia
Es gibt auch andere Zelltypen im Gehirn, aber Neuronen sind für die elektrochemischen Kommunikationsprozesse verantwortlich, die nicht nur Informationen übertragen, sondern auch manipulieren können. Wenn ein Neuron aktiviert wird, sendet es einen elektrischen Impuls entlang seines Axons an alle angeschlossenen Neuronen. Die Stärke des schließlich empfangenen Signals wird durch die synaptischen Verbindungen zwischen den einzelnen Neuronen bestimmt. Wenn das gesamte eingehende Signal eine Erregungsschwelle überschreitet, wird auch das empfangende Neuron aktiviert. Vereinfacht kann man diesen Vorgang in seine Bestandteile zerlegen, indem man eine graphenartige Struktur aus Knoten und Kanten mit Gewichten für jede Verbindung verwendet. In einem vollständig verbundenen Netzwerk ist jedes Neuron in einer Schicht mit jedem Neuron in der nächsten Schicht verbunden.
Bei einer Reihe von numerischen Eingabewerten können wir den Wert des ersten Neurons in der mittleren Schicht auf der linken Seite formal als die Summe aller Eingaben multipliziert mit dem Gewicht der jeweiligen Verbindung wie folgt berechnen
Wenn wir alle Gewichte für alle Neuronen in einer Matrix zusammenfassen, können wir die Werte der zweiten Schicht als einen Vektor schreiben:
Dann wenden wir eine Aktivierungsfunktion an f das den Prozess in einem Neuron nachahmt, bei dem der Ausgang nur aktiv ist, wenn der Eingang einen bestimmten Schwellenwert erreicht. Die Ausgabe dieses Netzes für eine bestimmte Eingabe x ist dann
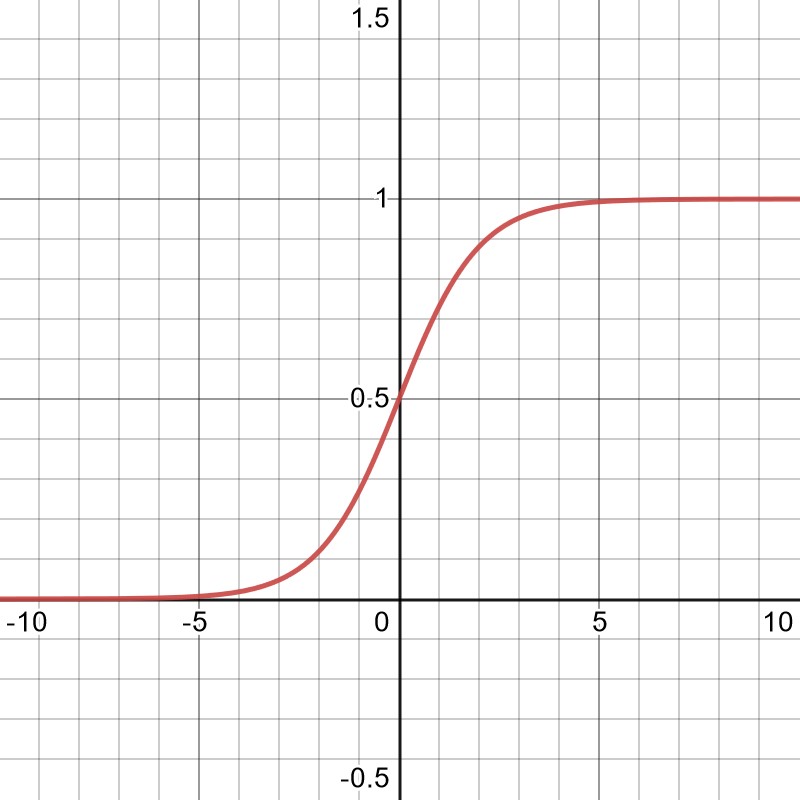
Eine gängige Wahl für die Aktivierungsfunktion ist eine sogenannte sigmoid Funktion,
in der nachstehenden Grafik dargestellt. Die Form der Funktion und ihr kontinuierliches Verhalten unterscheiden sich von dem, was man in biologischen Systemen finden würde, aber sie erweisen sich als ausreichend.
Hergestellt mit desmos.com
Durch Hinzufügen eines zusätzlichen Bias-Neurons mit einem festen Wert von eins zu den Eingangs- und versteckten Schichten kann der Aktivierungsgraph einzelner Neuronen nach links und rechts verschoben werden, während die Gewichte der anderen Eingänge ihn nach oben und unten skalieren. In Kombination mit den anderen Neuronen ist es einfach, beliebig dimensionale Funktionen mit beliebiger kontinuierlicher Form zu erzeugen, indem man die in den Gewichten der beiden Matrizen kodierten Einträge abstimmt. Dieser einfache Aufbau mag nicht nach viel klingen, aber die mehrschichtige Feedforward-Architektur ist tatsächlich in der Lage Annäherung an eine beliebige kontinuierliche Funktion über kompakte Domänen. Im Prinzip bedeutet dies, dass jeder Algorithmus, der eine Eingabe annimmt und eine Ausgabe erzeugt, als ein solches neuronales Netz realisiert werden kann. Die große Frage ist: Wie erhalten wir die Gewichte? Bei unglaublich kleinen Netzen ist es vielleicht sogar möglich, sie von Hand einzustellen, aber das wird sehr schnell unpraktikabel. Stattdessen werden die Netze anhand vorhandener, unverfälschter Datensätze trainiert, indem vorgegebene Eingaben mit voretikettierten Ausgaben abgeglichen werden. Auf diese Weise kann man den "Fehler" oder die Differenz zwischen der Ausgabe des Modells und der gewünschten Ausgabe berechnen und dann den Prozess der Backpropagation zur iterativen Aktualisierung der Modellparameter nutzen. Die Backpropagation nutzt die automatische Differenzierung und den Gradientenabstieg, um den Fehler bei jedem Iterationsschritt etwas zu verringern. Beim Gradientenabstieg wird die Funktion, die den Fehler erzeugt hat (d. h. der gesamte Berechnungsgraph des Modells), betrachtet und ihre partiellen Ableitungen in Bezug auf die trainierbaren Parameter genommen. Durch Änderung der Parameter in Richtung ihrer Ableitung, die den Gesamtfehler senkt, kann das Modell iterativ so eingestellt werden, dass es die gewünschte Ausgabe erzeugt. Normalerweise kann die Berechnung von Ableitungen komplizierter verschachtelter Funktionen wie der oben beschriebenen sehr mühsam sein, aber wenn man die Ableitung der Aktivierungsfunktion kennt, lässt sie sich leicht automatisieren. Noch besser: Da alle Computerchips im Wesentlichen durch die Zerlegung von Funktionen in einfache Additions- und Multiplikationsoperationen rechnen, kann die Berechnung der Ableitungen dieser verschachtelten Funktionen mit einer einfachen Anwendung der Kettenregel erfolgen.
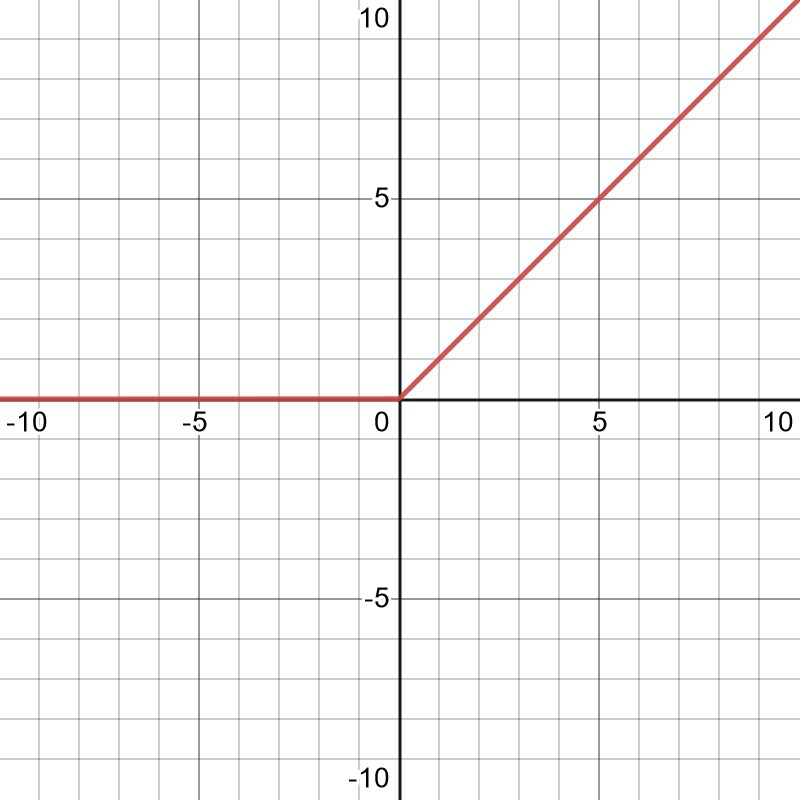
Mit der Zeit wurde klar, dass realistische Probleme extrem große Netze erfordern würden. Das erste Problem besteht darin, dass bei derart großen Netzen die Ableitungen einer normalen sigmoidartigen Aktivierungsfunktion dazu neigen, zu verschwinden. Dies lässt sich leicht erkennen, wenn man sich das obige Diagramm ansieht und sich vorstellt, dass viele Neuronen zum gesamten Input beitragen, der auf der x-Achse erscheinen würde. Wenn man zu weit nach links oder rechts geht, ändert sich die Funktion nur wenig, was eine sinnvolle Aktualisierung der Netzparameter erschwert. Dieses Problem wurde gelöst, indem man sich weiter von den ursprünglichen, biologischen Inspirationen entfernte und stattdessen die gleichgerichtete lineare Einheit (ReLU) als Aktivierungsfunktion einführte.
Hergestellt mit desmos.com
Diese Funktion ist extrem einfach - sie ist einfach x für x>0 und sonst 0. Sie behält jedoch gerade genug Nichtlinearität bei, um komplexes Verhalten in neuronalen Netzen ausreichend zu erfassen, und sie hat den zusätzlichen Vorteil, dass ihr Gradient nicht verschwindet - zumindest nicht für große Werte von x. Sie ist auch viel einfacher zu berechnen als die komplizierten nichtlinearen Sigmoid-Funktionen, was die Modelle viel leistungsfähiger macht. Heute gibt es viele Variationen von ReLU, aber es ist zu einem Eckpfeiler von Deep Learning-Modellen geworden und wird praktisch überall verwendet, auch in den in Transkribus verfügbaren Modellen.
Ein weiteres großes Problem größerer Netze besteht darin, dass mit zunehmender Anzahl von Parametern die Überanpassung immer häufiger auftritt. Um sicherzustellen, dass das Modell nicht nur die Trainingsdaten repliziert, sondern auch lernt, daraus zu verallgemeinern, haben sich Regularisierungsmethoden als sehr hilfreich erwiesen. Eines der etabliertesten Verfahren nutzt die sogenannten Aussetzerschichten. Während des Trainings nimmt eine Dropout-Schicht eine Schicht versteckter Neuronen und setzt die Ausgabe zufällig ausgewählter Neuronen auf Null - unabhängig von ihrer Eingabe. Dadurch wird das Netzwerk gezwungen, alle Informationen zu streuen, und es wird verhindert, dass es sich auf bestimmte Korrelationen verlässt, die in den Trainingsdaten vorherrschen könnten. Dropout-Schichten sind zu einem weiteren Eckpfeiler des Deep Learning geworden und werden auch für das Training von Modellen in Transkribus verwendet.
Was wir noch nicht erwähnt haben, was aber bei großen Modellen ebenfalls sehr wichtig ist, ist die anfängliche Festlegung der Parameter. Schließlich muss der iterative Trainingsprozess ja irgendwo beginnen. Bei kleinen Netzen reicht es in der Regel aus, die Parameter nach dem Zufallsprinzip gemäß einer Wahrscheinlichkeitsverteilung zu setzen. Das bedeutet jedoch, dass aufeinander folgende Schichten diese Verteilungen erwarten, und eine kleine Parameteränderung in einer frühen Schicht kann bei Modellen mit vielen versteckten Schichten zu großen Veränderungen führen. Um diese tiefen Netze zu trainieren, ist es notwendig, die Eingaben für jede Schicht zu standardisieren. Dies geschieht durch einen Prozess namens Batch-Normalisierung. Dabei wird die Ausgabe einer bestimmten Schicht für eine Reihe verschiedener Eingaben untersucht und dann so skaliert, dass die gesamte Gruppe bestimmte statistische Eigenschaften beibehält - in der Regel einen Mittelwert von Null und eine Varianz von Eins. Diese Technik wurde erstmals 2015 vorgeschlagen und ist heute in fast allen tiefen neuronalen Netzen verbreitet, auch in denen, die von Transkribus verwendet werden.
Im Laufe der Jahre gab es viele, viele weitere Verbesserungen im Bereich der künstlichen neuronalen Netze. Einige von ihnen waren klein, während andere wirklich bahnbrechend waren, wie z. B. Faltungsnetze, rekurrente Netze und in jüngerer Zeit Transformatoren (mehr dazu in künftigen Blogbeiträgen). Zusammengenommen haben sie es schließlich ermöglicht, gigantische Netze zu trainieren, die Folgendes leisten können unglaubliche Aufgaben. Zusammen mit dem Aufkommen unglaublich leistungsfähiger paralleler Computerchips, die ursprünglich für Videospiele entwickelt wurden (sich aber auch als perfekt für das Training neuronaler Netze erwiesen haben), haben wir nun endlich die Mittel, um die Big-Data-Revolution zu nutzen.
Wir verwenden Cookies, um Inhalte und Dienste zu personalisieren und zu verbessern, relevante Werbung zu liefern und die Sicherheit unserer Nutzer zu erhöhen. Sie können Ihre Cookie-Einstellungen jederzeit überprüfen. Weitere Informationen über die Verwendung von Cookies und Cookie-Einstellungen finden Sie in unserem Privacy policy Cookie settingsRejectAccept
Datenschutz & Cookies-Richtlinie
Datenschutz Übersicht
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die als notwendig eingestuften Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der grundlegenden Funktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Ablehnen einiger dieser Cookies kann jedoch Auswirkungen auf Ihr Surferlebnis haben.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Kategorie umfasst nur Cookies, die grundlegende Funktionalitäten und Sicherheitsmerkmale der Website gewährleisten. Diese Cookies speichern keine persönlichen Informationen.
Cookie
Beschreibung
Dauer
viewed_cookie_policy
Das Cookie wird vom GDPR Cookie Consent Plugin gesetzt und dient dazu, zu speichern, ob der Benutzer der Verwendung von Cookies zugestimmt hat oder nicht. Es speichert keine persönlichen Daten.
1 Stunde
PHPSESSID
Dieses Cookie ist in PHP-Anwendungen enthalten. Der Cookie wird verwendet, um die eindeutige Sitzungs-ID eines Benutzers zu speichern und zu identifizieren, um die Benutzersitzung auf der Website zu verwalten. Das Cookie ist ein Sitzungscookie und wird gelöscht, wenn alle Browserfenster geschlossen werden.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Beschreibung
Dauer
BESUCHER_INFO1_LIVE
Dieses Cookie wird von Youtube gesetzt. Wird verwendet, um die Informationen der eingebetteten Youtube-Videos auf einer Website zu verfolgen.
5 Monate
IDE
Wird von Google DoubleClick verwendet und speichert Informationen darüber, wie der Nutzer die Website und andere Werbung vor dem Besuch der Website nutzt. Dies wird verwendet, um Nutzern Anzeigen zu präsentieren, die für sie entsprechend dem Nutzerprofil relevant sind.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Beschreibung
Dauer
GPS
Dieses Cookie wird von Youtube gesetzt und registriert eine eindeutige ID für die Nachverfolgung von Benutzern basierend auf ihrem geografischen Standort
30 Minuten
tk_oder
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
5 Jahre
tk_r3d
Das Cookie wird von JetPack installiert. Wird für die internen Metriken für Benutzeraktivitäten verwendet, um die Benutzererfahrung zu verbessern
3 Tage
tk_lr
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
1 Jahr
_ga
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Besucher-, Sitzungs- und Camapign-Daten zu berechnen und die Nutzung der Website für den Analysebericht der Website zu verfolgen. Die Cookies speichern Informationen anonym und weisen eine zufällig generierte Nummer zu, um eindeutige Besucher zu identifizieren.
2 Jahre
_gid
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Informationen darüber zu speichern, wie Besucher eine Website nutzen, und hilft bei der Erstellung eines Analyseberichts darüber, wie sich die Website verhält. Die gesammelten Daten umfassen die Anzahl der Besucher, die Quelle, von der sie kommen, und die besuchten Seiten in anonymer Form.
1 Tag
matomo
Für die statistische Analyse verwenden wir auf dieser Website "Matomo". Dies ist ein Open-Source-Tool für die Webanalyse. Matomo überträgt keine Daten an Server außerhalb der Kontrolle von READ-COOP. Matomo ist deaktiviert, wenn Sie unsere Website besuchen. Nur wenn Sie aktiv zustimmen, wird Ihr Nutzungsverhalten anonymisiert erfasst.
1 Jahr
Hubspot
Hubspot, Inc. 25 First Street, Cambridge, MA 02141 USA
HubSpot ist ein Dienst zur Verwaltung von Benutzerdatenbanken, der von HubSpot, Inc. bereitgestellt wird. Wir verwenden HubSpot auf dieser Website für unsere Online-Kundensupport-Aktivitäten.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Beschreibung
Dauer
YSC
Dieses Cookie wird von Youtube gesetzt und dient dazu, die Aufrufe von eingebetteten Videos zu verfolgen.
1 Jahr
_gat
Dieses Cookie wird von Google Universal Analytics installiert, um die Abfragerate zu drosseln und so die Datensammlung auf stark frequentierten Seiten zu begrenzen.