Perché ci sono voluti più di 60 anni perché l'IA decollasse
Felix Dietrich
4 anni fa
Una piccola introduzione al Deep Learning
La teoria dietro il cosiddetto perceptron, fondamentalmente l'elemento chiave delle reti neurali artificiali e quindi di tutti i moderni modelli di deep learning o di "IA", è vecchia quasi quanto il transistor. Quindi, se questi algoritmi sono vecchi come i computer stessi, perché c'è voluto più di mezzo secolo prima di essere posti al centro dell'attenzione della scienza e della tecnologia? La risposta è: è complicato. Letteralmente. Eseguire i modelli esistenti è relativamente facile, ma addestrarli non lo è. Soprattutto non se si hanno in mente applicazioni nel mondo reale. Ma prima di poter analizzare alcune delle scoperte che ci hanno portato dove siamo oggi, facciamo un passo indietro e capiamo come funzionano effettivamente le reti neurali artificiali. Il primo passo quando si ricrea il cervello in un computer è ovviamente quello di guardare come il cervello fa i suoi calcoli. Qui sotto c'è uno schizzo di un neurone, il componente di calcolo di base del sistema nervoso di quasi tutti gli animali.
Diagramma di un neurone | Fonte: Wikipedia
Ci sono anche altri tipi di cellule che si trovano nel cervello, ma i neuroni sono responsabili dei processi di comunicazione elettrochimica che possono non solo trasmettere ma anche manipolare le informazioni. Quando viene attivato, un neurone spara un impulso elettrico lungo l'assone a tutti i neuroni collegati. La forza del segnale ricevuto alla fine è determinata dalle connessioni sinaptiche tra i singoli neuroni. Quando il segnale totale in arrivo supera una soglia di eccitazione, anche il neurone ricevente si attiva. In modo semplificato, possiamo scomporre il tutto nelle sue componenti usando una struttura a grafo di nodi e spigoli con pesi per ogni connessione. In una rete completamente connessa, ogni neurone in uno strato è connesso ad ogni neurone nello strato successivo.
Dato un insieme di valori numerici in ingresso, possiamo formalmente calcolare il valore del primo neurone nello strato centrale a sinistra come la somma di tutti gli ingressi moltiplicata per il peso della rispettiva connessione come
Se raggruppiamo tutti i pesi di tutti i neuroni in una matrice, possiamo scrivere i valori del secondo strato come un vettore:
Poi applichiamo una funzione di attivazione f che imita il processo in un neurone in cui l'uscita è attiva solo quando l'ingresso raggiunge una certa soglia. L'output di questa rete per un dato input x è quindi
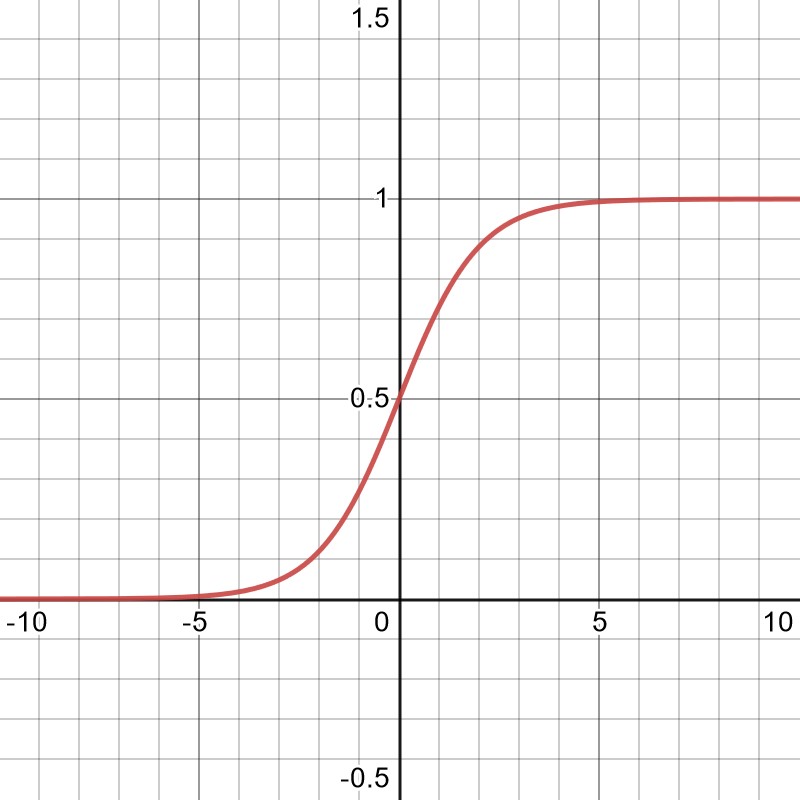
Una scelta comune per la funzione di attivazione è un cosiddetto sigmoide funzione,
mostrato nel grafico qui sotto. La forma della funzione e il suo comportamento continuo differiscono da qualcosa che si troverebbe nei sistemi biologici, ma risulta essere sufficiente.
Fatto con desmos.com
Aggiungendo un ulteriore neurone di bias con un valore fisso di uno agli strati di ingresso e nascosto, il grafico di attivazione dei singoli neuroni può essere spostato a sinistra e a destra, mentre i pesi degli altri ingressi lo scalano verso l'alto e verso il basso. In combinazione con gli altri neuroni, è facile creare funzioni arbitrarie-dimensionali di qualsiasi forma continua sintonizzando le voci codificate nei pesi delle due matrici. Questa semplice configurazione potrebbe non sembrare molto, ma l'architettura feedforward multistrato è in realtà capace di approssimare qualsiasi funzione continua su domini compatti. Fondamentalmente questo significa che qualsiasi algoritmo che prende un input e produce un output potrebbe essere realizzato come una rete neurale. La grande domanda è: come otteniamo i pesi? Per reti incredibilmente piccole, potrebbe anche essere possibile sintonizzarle a mano, ma questo diventa inattuabile molto velocemente. Invece, le reti sono addestrate su insiemi di dati esistenti e veritieri, facendo corrispondere input dati a output pre-etichettati. In questo modo, si può calcolare l'"errore" o la differenza tra l'output del modello e l'output desiderato e poi usare il processo di backpropagation per aggiornare iterativamente i parametri del modello. La backpropagation fa uso della differenziazione automatica e della discesa del gradiente per abbassare leggermente l'errore ad ogni passo dell'iterazione. La discesa del gradiente funziona guardando la funzione che ha generato l'errore (cioè l'intero grafico computazionale del modello) e prendendo le sue derivate parziali rispetto ai parametri allenabili. Cambiando i parametri nella direzione della loro derivata che abbassa l'errore totale, il modello può essere sintonizzato iterativamente per produrre l'output desiderato. Normalmente, calcolare le derivate di complicate funzioni annidate come quella descritta sopra può essere molto noioso, ma se si conosce la derivata della funzione di attivazione può essere facilmente automatizzato. Ancora meglio, poiché essenzialmente tutti i chip dei computer calcolano scomponendo le funzioni in semplici operazioni di addizione e moltiplicazione, il calcolo delle derivate di queste funzioni annidate può essere fatto con una semplice applicazione della regola della catena.
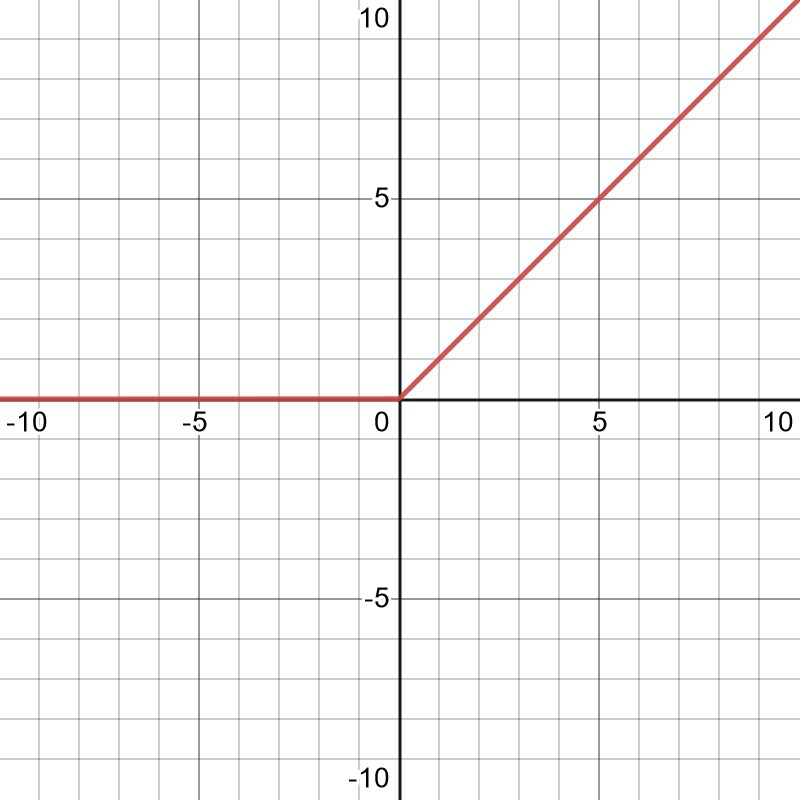
Col tempo divenne chiaro che i problemi realistici avrebbero richiesto reti estremamente grandi. Il primo problema sta nel fatto che per reti così grandi, le derivate di una normale funzione di attivazione di tipo sigmoide tendono a svanire. Questo può essere facilmente visto guardando il grafico sopra e immaginando molti neuroni che contribuiscono all'input totale che apparirebbe sull'asse delle x. Andando troppo a sinistra o a destra del grafico, la funzione cambia molto poco, rendendo difficile aggiornare i parametri della rete in modo ragionevole. Questo problema è stato risolto allontanandosi ulteriormente dalle ispirazioni biologiche originali e introducendo invece l'unità lineare rettificata, o ReLU, come funzione di attivazione.
Fatto con desmos.com
Questa funzione è estremamente semplice - è solo x per x>0 e 0. Tuttavia, mantiene abbastanza non linearità per catturare sufficientemente il comportamento complesso all'interno delle reti neurali e ha il vantaggio aggiunto che il suo gradiente non svanisce - almeno non per grandi valori di x. È anche molto più facile da calcolare rispetto alle complicate funzioni sigmoidi non lineari, rendendo i modelli molto più performanti. Oggi ci sono molte varianti di ReLU, ma è diventata una pietra miliare dei modelli di Deep Learning ed è usata praticamente ovunque, anche nei modelli disponibili in Transkribus.
Un altro grande problema affrontato dalle reti più grandi è che con un numero crescente di parametri, l'overfitting diventa più prevalente. Per garantire che il modello non si limiti a replicare i dati di addestramento, ma impari anche a generalizzare da essi, i metodi di regolarizzazione si sono rivelati molto utili. Uno dei più affermati fa uso dei cosiddetti dropout layers. Durante l'addestramento, uno strato di dropout prende uno strato di neuroni nascosti e imposta l'output di neuroni scelti a caso a zero - indipendentemente dal loro input. Questo costringe la rete a diffondere qualsiasi informazione e impedisce la dipendenza da certe correlazioni che potrebbero essere prevalenti nei dati di addestramento. I livelli di dropout sono diventati un'altra pietra miliare del deep learning e vengono utilizzati anche per l'addestramento dei modelli in Transkribus.
Qualcosa che non abbiamo ancora menzionato, ma che è anche molto importante per i grandi modelli, è come impostare i parametri inizialmente. Dopo tutto, il processo di addestramento iterativo deve iniziare da qualche parte. Per piccole reti, di solito è sufficiente impostare i parametri in modo casuale secondo qualche distribuzione di probabilità. Questo significa però che gli strati consecutivi si aspettano queste distribuzioni e un piccolo cambiamento dei parametri in uno strato iniziale può portare a enormi cambiamenti lungo la strada per i modelli con molti strati nascosti. Al fine di addestrare queste reti profonde, diventa necessario standardizzare gli ingressi per ogni strato. Questo viene fatto utilizzando un processo chiamato normalizzazione batch. Guarda l'uscita di uno strato specifico per un gruppo di ingressi diversi e poi ridimensiona l'uscita in modo che l'intero set mantenga determinate proprietà statistiche - di solito una media di zero e una varianza di uno. Proposta per la prima volta nel 2015, questa tecnica è ora prevalente in quasi tutte le reti neurali profonde, comprese quelle utilizzate da Transkribus.
Ci sono stati molti, molti altri miglioramenti nel campo delle reti neurali artificiali nel corso degli anni. Alcuni di essi erano piccoli, mentre altri sono stati dei veri e propri game changer come le reti convoluzionali, le reti ricorrenti e, più recentemente, i trasformatori (restate sintonizzati per saperne di più in futuri post sul blog). Combinati, hanno infine reso possibile l'addestramento di reti gigantesche che possono eseguire compiti incredibili. Insieme all'aumento di chip di calcolo parallelo incredibilmente potenti che sono stati originariamente progettati per i videogiochi (ma si sono rivelati perfetti anche per l'addestramento delle reti neurali), ora abbiamo finalmente i mezzi per sfruttare la rivoluzione dei big-data.
Utilizziamo i cookie per personalizzare e migliorare i contenuti e i servizi, fornire pubblicità pertinente e migliorare la sicurezza dei nostri utenti. È possibile controllare le impostazioni dei cookie in qualsiasi momento. Per ulteriori informazioni sull'uso dei cookie e sulle impostazioni dei cookie, consultare il nostro Privacy policy Cookie settingsRejectAccept
Politica sulla privacy e sui cookie
Panoramica sulla privacy
Questo sito web utilizza i cookie per migliorare la tua esperienza durante la navigazione nel sito. Di questi cookie, quelli classificati come necessari vengono memorizzati nel tuo browser, perché sono essenziali per il funzionamento delle funzionalità di base del sito web. Utilizziamo anche cookie di terze parti che ci aiutano ad analizzare e capire come utilizzi questo sito web. Questi cookie vengono memorizzati nel tuo browser solo con il tuo consenso. Hai anche la possibilità di rinunciare a questi cookie. Ma l'opt-out di alcuni di questi cookie può avere un effetto sulla tua esperienza di navigazione.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questa categoria comprende solo i cookie che assicurano le funzionalità di base e le caratteristiche di sicurezza del sito web. Questi cookie non memorizzano alcuna informazione personale.
Cookie
Descrizione
Durata
politica dei cookie visualizzati
Il cookie è impostato dal plugin GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
1 ora
PHPSESSID
Questo cookie è nativo delle applicazioni PHP. Il cookie viene utilizzato per memorizzare e identificare l'ID di sessione unico di un utente allo scopo di gestire la sessione dell'utente sul sito web. Il cookie è un cookie di sessione e viene cancellato quando tutte le finestre del browser vengono chiuse.
I cookie pubblicitari sono utilizzati per fornire ai visitatori annunci pertinenti e campagne di marketing. Questi cookie tracciano i visitatori attraverso i siti web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Descrizione
Durata
VISITATORE_INFO1_LIVE
Questo cookie è impostato da Youtube. Utilizzato per tracciare le informazioni dei video di YouTube incorporati in un sito web.
5 mesi
IDE
Utilizzato da Google DoubleClick e memorizza le informazioni su come l'utente utilizza il sito web e qualsiasi altra pubblicità prima di visitare il sito. Questo viene utilizzato per presentare agli utenti gli annunci che sono rilevanti per loro in base al profilo dell'utente.
I cookie analitici sono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, la frequenza di rimbalzo, la fonte del traffico, ecc.
Cookie
Descrizione
Durata
GPS
Questo cookie è impostato da Youtube e registra un ID unico per tracciare gli utenti in base alla loro posizione geografica
30 minuti
tk_or
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
5 anni
tk_r3d
Il cookie è installato da JetPack. Utilizzato per le metriche interne delle attività dell'utente per migliorare l'esperienza dell'utente
3 giorni
tk_lr
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
1 anno
{\an8}Che cosa?
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per calcolare i dati del visitatore, della sessione, del camapign e per tenere traccia dell'utilizzo del sito per il rapporto di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato randoly per identificare i visitatori unici.
2 anni
_gid
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per memorizzare informazioni su come i visitatori utilizzano un sito web e aiuta a creare un rapporto analitico su come sta andando il sito web. I dati raccolti includono il numero di visitatori, la fonte da cui provengono e le pagine visitate in forma anonima.
1 giorno
matomo
Per l'analisi statistica, usiamo "Matomo" su questo sito web. Si tratta di uno strumento open source per l'analisi del web. Matomo non trasmette dati a server al di fuori del controllo di READ-COOP. Matomo viene disattivato quando si visita il nostro sito web. Solo se lei acconsente attivamente, il suo comportamento d'uso viene registrato in modo anonimo.
1 anno
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot è un servizio di gestione di database di utenti fornito da HubSpot, Inc. Su questo sito web utilizziamo HubSpot per le nostre attività di assistenza clienti online.
I cookie di performance sono utilizzati per capire e analizzare gli indici di performance chiave del sito web che aiuta a fornire una migliore esperienza utente per i visitatori.
Cookie
Descrizione
Durata
YSC
Questo cookie è impostato da Youtube e viene utilizzato per monitorare le visualizzazioni dei video incorporati.
1 anno
_gat
Questo cookie è installato da Google Universal Analytics per strozzare il tasso di richiesta per limitare la raccolta di dati su siti ad alto traffico.