Ad oggi, il cervello umano è probabilmente la struttura computazionale più complessa dell'universo conosciuto. Con fino a 1011 neuroni, contiene più cellule elettricamente eccitabili del cervello di una balena blu. E con fino a 1015 connessioni sinaptiche, surclassa ancora i più grandi modelli di apprendimento automatico in termini di parametri apprendibili. Ma i computer stanno recuperando ad un ritmo crescente. Nel 1997, la gente rimase scioccata nel vedere il campione mondiale di scacchi, Garry Kasparov, sconfitto dal supercomputer Deep Blue di IBM. Ma mentre molti credevano che battere gli umani a scacchi richiedesse una qualche forma di "vera" intelligenza, le persone capirono velocemente cosa fosse Deep Blue realmente: Un modo efficiente per cercare strutture di dati ad albero. Si è scoperto che tutto ciò che serviva per sconfiggere gli umani, era la capacità di guardare tutte le possibili mosse di entrambi i giocatori e poi scegliere la migliore. Mentre questo albero cresce esponenzialmente ad ogni mossa, non appena un computer può calcolare 12 o 14 mosse in anticipo in un lasso di tempo ragionevole, gli umani non possono più tenere il passo.
Partite storiche: Umani contro IA
Un gioco che è stato ampiamente considerato al di là delle capacità di qualsiasi computer ordinario è stato il gioco da tavolo Go. Mentre le regole possono sembrare molto più semplici di quelle degli scacchi, Go ha in realtà una complessità dell'albero di gioco che è più di duecento ordini di grandezza più grande. Di conseguenza, anche computer molto più potenti di Deep Blue non avevano alcuna possibilità di risolvere questo compito. Eppure, 19 anni dopo la fatidica partita di Kasparov, la gente è stata ancora una volta colta di sorpresa quando il computer AlphaGo di Google ha sconfitto il campione in carica di Go, Lee Sedol, nel 2016. Questo incredibile successo è arrivato sulla scia di una vera rivoluzione nel modo in cui vediamo e comprendiamo l'intelligenza artificiale. Un modo che assomiglia molto di più al funzionamento interno del cervello umano. Questa tecnologia ha permesso ai computer di raggiungere gli esseri umani in molte aree fino ad allora inimmaginabili - una di queste è il riconoscimento del testo basato sulle immagini. Il passo tecnologico tra il Riconoscimento ottico dei caratteri (OCR) e il Riconoscimento del testo scritto a mano (HTR) risulta essere altrettanto profondo di quello tra Deep Blue e AlphaGo.
OCR (Optical Character Recognition)
Mentre non fa praticamente alcuna differenza per l'occhio umano, il testo scritto a macchina come quello a destra è completamente illeggibile per un computer. La ragione è che non è fatto di caratteri, ma di pixel in un'immagine. D'altra parte, trasformare i caratteri in pixel è un compito banale. Tutto ciò di cui ha bisogno è una mappatura di ogni carattere a un insieme di pixel che lo rappresentano in un font specificato. Questo va bene per tutte le applicazioni in cui un umano vuole semplicemente leggere il testo, come visualizzarlo su uno schermo o stamparlo su un foglio di carta. Ma ci sono anche applicazioni in cui si vorrebbe convertire un'immagine in un vero e proprio testo digitalizzato. Questo non solo rende più facile l'archiviazione, ma permette anche di modificare rapidamente le sezioni o anche di cercare le parole. Il problema è che trasformare i pixel in caratteri non è più un processo esatto e diretto. Ci sono una miriade di tecniche di compressione delle immagini che possono produrre ogni sorta di effetti sfavorevoli a livello di pixel. Oltre a ciò, le persone vorrebbero anche digitalizzare documenti scannerizzati o persino fotografati, il che potrebbe introdurre spostamenti o sporcizia e sbavature. Alla fine, il meglio che possiamo fare è un'approssimazione.
Fortunatamente, queste approssimazioni non richiedono molta potenza di calcolo e nemmeno algoritmi sofisticati. L'abbinamento di modelli utilizzando matrici come quella a sinistra ha portato a un riconoscimento dei caratteri estremamente buono già negli anni '70. Mentre questo banale pattern matching richiede una certa libertà statistica nell'interpretazione dei caratteri, ci sono anche algoritmi più matematicamente rigorosi. Per esempio, si potrebbe provare a prendere tutte le linee e gli anelli chiusi e trasformarli in un grafico. Il problema può quindi essere riformulato come identificazione di sottografi isomorfi. Mentre i moderni algoritmi OCR non hanno ancora raggiunto una precisione perfetta, sono semplici, veloci e abbastanza accurati per la maggior parte dei caratteri da essere utili in una vasta gamma di dispositivi - dagli scanner laser palmari in tempo reale agli smartphone fino alle fotocopiatrici.
HTR (Handwritten Text Recognition)
Mentre il problema dell'OCR per il testo automatico è stato effettivamente risolto, nella maggior parte delle applicazioni, per molto tempo la scrittura a mano umana mostra una gamma quasi infinita di caratteri e stili. Riconoscerli correttamente va ben oltre i classici algoritmi di pattern matching, ed è per questo che il riconoscimento del testo scritto a mano rimane all'avanguardia della scienza. Al giorno d'oggi, ogni pochi mesi un gruppo di ricerca o un'azienda mostra un nuovo algoritmo migliorato. Ma non è sempre stato così. All'inizio del XXI secolo, questo compito era ancora considerato praticamente impossibile. I migliori gruppi di ricerca del mondo non riuscivano a trovare qualcosa di lontanamente utile. Quindi cosa è cambiato? La risposta breve è: reti neurali artificiali (ANNs). La stessa tecnologia che ha permesso ai computer di sconfiggere il campione del mondo di Go ha ora permesso di affrontare la scrittura umana. Questo approccio differisce fondamentalmente dagli algoritmi classici nel senso che il modello di riconoscimento non è più programmato a mano, ma appreso automaticamente da un insieme di esempi. L'architettura alla base delle ANNs esiste da molto tempo, ma solo i miglioramenti nel calcolo parallelizzato, nelle strutture di rete e negli algoritmi di addestramento - e, in particolare, la disponibilità di dati di addestramento - hanno permesso loro di diventare effettivamente utili al di fuori degli esercizi accademici.
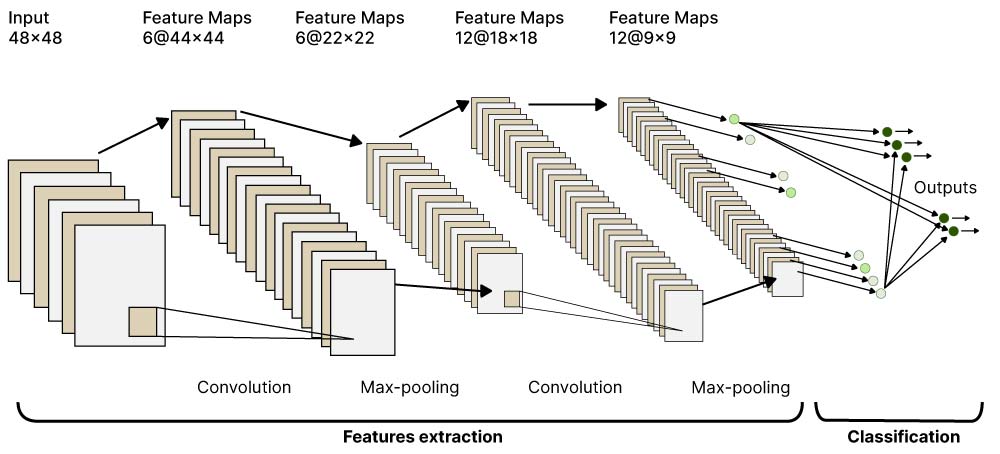
Uno dei tipi di rete più utilizzati oggi per il riconoscimento delle immagini è la cosiddetta rete neurale convoluzionale o convnet.
Struttura esemplare di una rete convoluzionale
I dettagli di queste reti variano significativamente, ma la struttura fondamentale è sempre la stessa. Il processo inizia prendendo i pixel di un'immagine come input e poi vengono estratte le caratteristiche applicando sequenzialmente alcuni filtri. Questi filtri sono essenzialmente maschere che vengono passate sull'immagine per vedere se qualcosa vi si adatta. Nel classico pattern matching, gli esseri umani dovrebbero predeterminare il modo in cui questi filtri appaiono, ma in una convnet iniziano in modo casuale e poi vengono raffinati durante il processo di addestramento. L'insieme finale di caratteristiche viene poi alimentato in una rete densamente connessa, che è dove il vero potere di predizione universale di questo algoritmo deriva. Esiste persino una prova matematica (cosa piuttosto rara nel campo delle ANN) che afferma che una tale rete può imparare ad approssimare qualsiasi funzione ragionevolmente ben comportata con precisione arbitraria, purché la rete sia sufficientemente grande. Sfortunatamente, però, la dimostrazione non dice nulla su quanto grande debba effettivamente essere, quindi questo di solito deve essere determinato per tentativi ed errori. Tornando alla convnet, questo strato è poi collegato ad una sequenza di uscite, che potrebbero essere davvero qualsiasi cosa. Per l'HTR, si vorrebbe idealmente avere caratteri o anche parole in questo strato finale. Durante l'addestramento, una serie di immagini di riferimento con contenuti noti viene alimentata nella rete e poi il suo output viene confrontato con i valori reali. Sulla base della differenza tra la previsione del modello e la verità, i parametri all'interno della rete vengono aggiornati iterativamente. Quando l'addestramento è completo, nuove immagini possono essere riconosciute guardando l'uscita che mostra l'attivazione più forte. Con la giusta struttura della rete e l'impostazione dell'addestramento, si può anche ottenere qualcosa come una distribuzione di probabilità nello strato di uscita.
Naturalmente, questo non è esattamente così banale come potrebbe sembrare. Per modelli ampiamente applicabili si ha solitamente bisogno di enormi quantità di dati di addestramento e di risorse di calcolo, e anche in questo caso ci sono molte insidie. Gli sviluppatori di software e i produttori di hardware hanno lavorato in tandem negli ultimi anni, fornendo potenti chip che sono fatti apposta per i calcoli tipici dell'IA, e framework software molto versatili da usare. In READ-COOP, stiamo costantemente espandendo le nostre capacità hardware per fare uso degli ultimi sviluppi tecnologici e teniamo sempre d'occhio i nuovi algoritmi emergenti per migliorare la nostra piattaforma.
Utilizziamo i cookie per personalizzare e migliorare i contenuti e i servizi, fornire pubblicità pertinente e migliorare la sicurezza dei nostri utenti. È possibile controllare le impostazioni dei cookie in qualsiasi momento. Per ulteriori informazioni sull'uso dei cookie e sulle impostazioni dei cookie, consultare il nostro Privacy policy Cookie settingsRejectAccept
Politica sulla privacy e sui cookie
Panoramica sulla privacy
Questo sito web utilizza i cookie per migliorare la tua esperienza durante la navigazione nel sito. Di questi cookie, quelli classificati come necessari vengono memorizzati nel tuo browser, perché sono essenziali per il funzionamento delle funzionalità di base del sito web. Utilizziamo anche cookie di terze parti che ci aiutano ad analizzare e capire come utilizzi questo sito web. Questi cookie vengono memorizzati nel tuo browser solo con il tuo consenso. Hai anche la possibilità di rinunciare a questi cookie. Ma l'opt-out di alcuni di questi cookie può avere un effetto sulla tua esperienza di navigazione.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questa categoria comprende solo i cookie che assicurano le funzionalità di base e le caratteristiche di sicurezza del sito web. Questi cookie non memorizzano alcuna informazione personale.
Cookie
Descrizione
Durata
politica dei cookie visualizzati
Il cookie è impostato dal plugin GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
1 ora
PHPSESSID
Questo cookie è nativo delle applicazioni PHP. Il cookie viene utilizzato per memorizzare e identificare l'ID di sessione unico di un utente allo scopo di gestire la sessione dell'utente sul sito web. Il cookie è un cookie di sessione e viene cancellato quando tutte le finestre del browser vengono chiuse.
I cookie pubblicitari sono utilizzati per fornire ai visitatori annunci pertinenti e campagne di marketing. Questi cookie tracciano i visitatori attraverso i siti web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Descrizione
Durata
VISITATORE_INFO1_LIVE
Questo cookie è impostato da Youtube. Utilizzato per tracciare le informazioni dei video di YouTube incorporati in un sito web.
5 mesi
IDE
Utilizzato da Google DoubleClick e memorizza le informazioni su come l'utente utilizza il sito web e qualsiasi altra pubblicità prima di visitare il sito. Questo viene utilizzato per presentare agli utenti gli annunci che sono rilevanti per loro in base al profilo dell'utente.
I cookie analitici sono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, la frequenza di rimbalzo, la fonte del traffico, ecc.
Cookie
Descrizione
Durata
GPS
Questo cookie è impostato da Youtube e registra un ID unico per tracciare gli utenti in base alla loro posizione geografica
30 minuti
tk_or
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
5 anni
tk_r3d
Il cookie è installato da JetPack. Utilizzato per le metriche interne delle attività dell'utente per migliorare l'esperienza dell'utente
3 giorni
tk_lr
Questo cookie è impostato dal plugin JetPack sui siti che utilizzano WooCommerce. Questo è un cookie di riferimento utilizzato per analizzare il comportamento dei referrer per Jetpack
1 anno
{\an8}Che cosa?
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per calcolare i dati del visitatore, della sessione, del camapign e per tenere traccia dell'utilizzo del sito per il rapporto di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato randoly per identificare i visitatori unici.
2 anni
_gid
Questo cookie è installato da Google Analytics. Il cookie viene utilizzato per memorizzare informazioni su come i visitatori utilizzano un sito web e aiuta a creare un rapporto analitico su come sta andando il sito web. I dati raccolti includono il numero di visitatori, la fonte da cui provengono e le pagine visitate in forma anonima.
1 giorno
matomo
Per l'analisi statistica, usiamo "Matomo" su questo sito web. Si tratta di uno strumento open source per l'analisi del web. Matomo non trasmette dati a server al di fuori del controllo di READ-COOP. Matomo viene disattivato quando si visita il nostro sito web. Solo se lei acconsente attivamente, il suo comportamento d'uso viene registrato in modo anonimo.
1 anno
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot è un servizio di gestione di database di utenti fornito da HubSpot, Inc. Su questo sito web utilizziamo HubSpot per le nostre attività di assistenza clienti online.
I cookie di performance sono utilizzati per capire e analizzare gli indici di performance chiave del sito web che aiuta a fornire una migliore esperienza utente per i visitatori.
Cookie
Descrizione
Durata
YSC
Questo cookie è impostato da Youtube e viene utilizzato per monitorare le visualizzazioni dei video incorporati.
1 anno
_gat
Questo cookie è installato da Google Universal Analytics per strozzare il tasso di richiesta per limitare la raccolta di dati su siti ad alto traffico.