Einführung von Tabellenmodellen - Trainierbare Layout-KI in Transkribus
27. Oktober 2023
News, Transkribus
Nach dem Start der neuen und verbesserten Web-App können wir nun mehr über die neue Generation der trainierbaren Layout-Technologie verraten. Mit der zuvor eingeführten trainable FeldmodelleDie Verarbeitung von Dokumenten mit komplexerem Layout, wie z. B. Zeitungen, Zeitschriften, Logbüchern, Gerichtsakten oder Formularen, wird dadurch wesentlich erleichtert.
Aber was ist mit der einzigartigen Struktur von Tabellen? Um die Herausforderung der Erkennung und Transkription von Tabellen zu bewältigen, führen wir die trainierbaren Tabellenmodelle ein. Nach den Feldmodellen sind die Tabellenmodelle der nächste Schritt zu einer verbesserten und effizienteren Layout-Erkennung Ihrer historischen Dokumente. Wir werden zunächst das trainierbare Tabellenmodell und seine Vorteile vorstellen und dann erklären, wie man damit anfängt.
Die Macht der Tabellenmodelle
Bei der Arbeit mit Dokumenten, die Tabellen enthalten oder daraus bestehen, ist es oft wichtig, die Struktur des Tabellenlayouts sowie den Inhalt zu erkennen und zu erfassen. Tabellen sind eine gängige Methode zur Organisation von Daten in Dokumenten wie Registern, Konten, Aufzeichnungen, Inventaren oder Katalogen. Bei der Recherche in diesen Dokumenten beschränken sich die zu extrahierenden Daten in der Regel nicht auf einige wenige Seiten, sondern erstrecken sich über ein größeres Volumen von Seiten. Das optimale Hilfsmittel für unsere Nutzer wäre daher eine automatisierte, aber zuverlässige Layout-Erkennung.
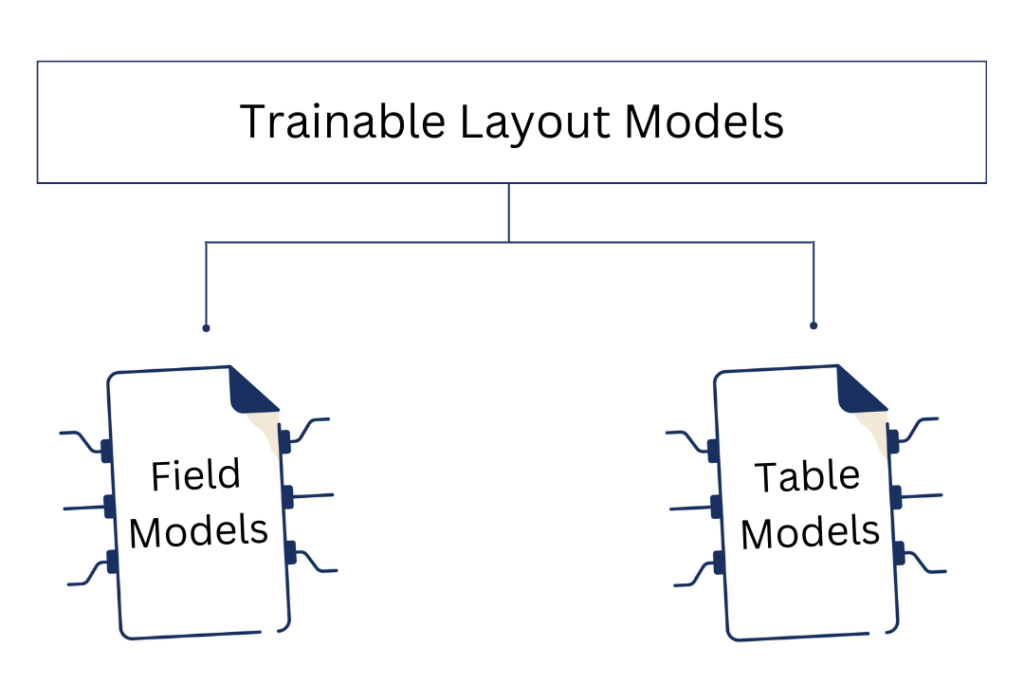
Das war das Ziel von Transkribus bei der Arbeit an den trainierbaren Layout-Modellen: den Field Models und den Table Models. Mit den trainierbaren Tabellenmodellen können unsere Nutzer nun ein individuelles Layout-Erkennungsmodell trainieren, das speziell auf die Erkennung des Layouts der Dokumente, an denen sie gerade arbeiten, zugeschnitten ist und auf die automatische Erkennung der gesamten Sammlung angewendet werden kann. Die neue Funktion eines trainierbaren Tabellenmodells wird zu einer zuverlässigeren Layout-Erkennung, einem effizienteren Transkriptionsprozess und einer einfacheren Analyse historischer Daten in einer strukturierten Umgebung führen.
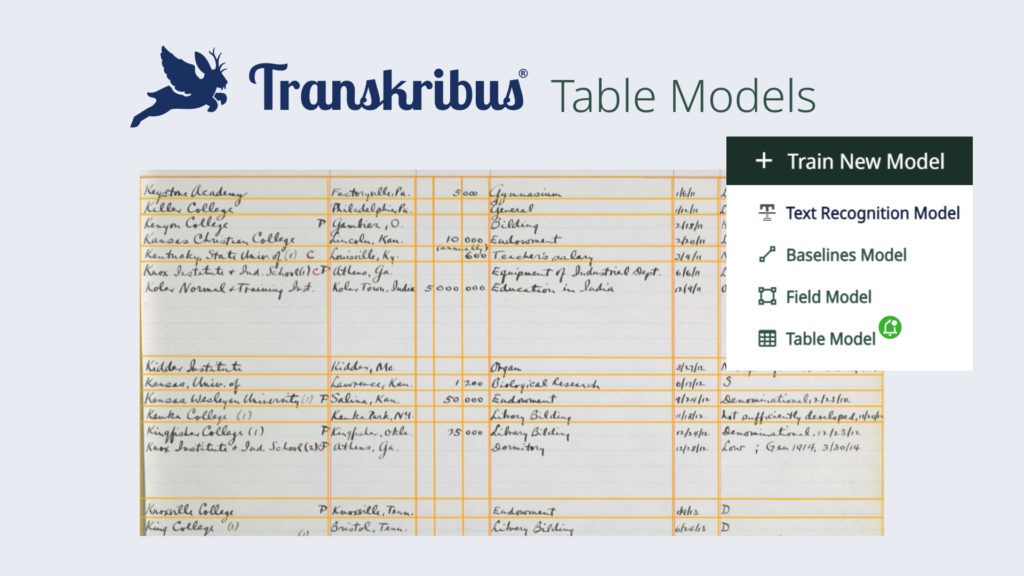
Neue trainierbare Layout-Optionen mit Transkribus.
Der Nutzen von Tabellenmodellen
Die Verwendung der Standard-Layouterkennung führt nicht immer zu zufriedenstellenden Ergebnissen. Mit den neuen trainierbaren Tabellenmodellen können Sie jedoch diese anpassbare Technologie nutzen, die trainiert werden kann, um selbst unregelmäßige Tabellen genau zu erkennen und Layoutelemente in großem Umfang zu erkennen. Diese Modelle sind besonders nützlich für Dokumente mit mehreren Textregionen und ermöglichen Ihnen eine genauere Darstellung der Dokumente.
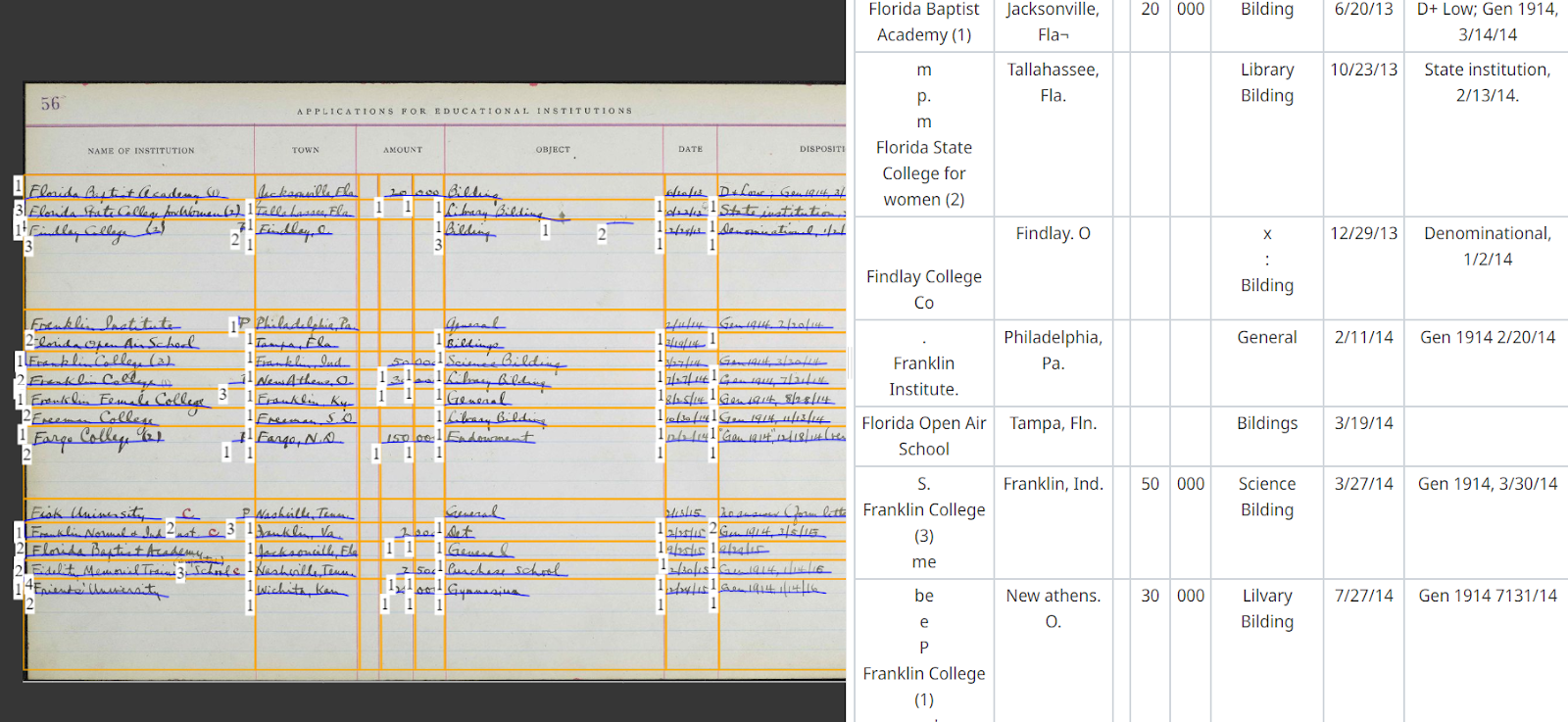
Bei Tabellen kann die derzeitige Standardfunktion zur automatischen Layoutanalyse und Texterkennung den Text aus verschiedenen Tabellenzellen transkribieren. Allerdings entspricht die Lesereihenfolge des transkribierten Textes in den Textregionen oder -zeilen oft nicht dem ursprünglichen Tabellenlayout und wird auch nicht im Tabellenformat dargestellt. Während dies für die einfache Suche nach bestimmten Namen oder Begriffen in Ordnung ist, ist die Übertragung der Daten in eine strukturierte Form oft sehr schwierig, wenn überhaupt möglich. Es würde viel Zeit in Anspruch nehmen, die Transkription umzustrukturieren und zu organisieren, um sie für den Aufbau einer Datenbank nutzbar zu machen.
Im Gegensatz zu den derzeit verfügbaren P2PaLA-Modellen benötigen die Tabellenmodelle weniger Trainingsdaten und sind gleichzeitig präziser. Die neuen Tabellenmodelle sind so konzipiert, dass sie mit einer begrenzten Menge an Trainingsmaterial effektiv trainiert werden können, wodurch der Prozess rationalisiert wird. Dieser Ansatz hat das Potenzial, den Zeitaufwand für das Erstellen oder Anpassen der Tabellen oder das Markieren verschiedener Layoutelemente auf jeder Seite zu verringern. Stattdessen können sich die Anwender auf die Erstellung der richtigen Layout-Formen konzentrieren, um das Modell zu trainieren, und Transkribus den Rest überlassen.
Es ist wichtig zu beachten, dass Tabellenmodelle keine allumfassende oder sofort einsetzbare Lösung sind. Um optimale Ergebnisse zu erzielen, müssen die Modelle ähnlich wie ein Texterkennungsmodell trainiert werden. In Kürze wird es möglich sein, ein benutzerdefiniertes Layoutmodell nicht nur für komplexe Feldlayouts, sondern auch für Tabellen in Transkribus zu trainieren.
Mit einem kleinen Datensatz können Sie die Tabellenmodelle bereits hier auf beta.transkribus.eu.
Transkribus Herausgeber: Carnegie Corporation Register of Applications from Educational Institutions, 1911-1920. Über Carnegie-Gesellschaft von New York
Trainingstabelle Modelle
Die Digitalisierung von Tabellen stellt eine Reihe von Herausforderungen dar, die mit unseren neu entwickelten trainierbaren Tabellenmodellen gelöst werden sollen. Tabellen sind seit Jahrhunderten ein Standardmerkmal in Dokumenten, von mittelalterlichen Büchern bis hin zu modernen Tabellenkalkulationen. Sie haben verschiedene Formate und können wichtige Daten enthalten.
Diese neuen Tabellenmodelle können eine Vielzahl von Tabellentypen verarbeiten, auch solche mit unregelmäßigen Zeilenhöhen oder -breiten. Um diese Modelle effektiv zu trainieren, ist es wichtig, eine ausreichende Sammlung von Referenzseiten zu erstellen, um sicherzustellen, dass die Modelle die Tabellen korrekt interpretieren können.
Im Dokument-Editor können die Benutzer flexibel einstellen, wie Tabellen erkannt werden. Sie können vertikale und horizontale Spalten definieren und festlegen, welche Informationen innerhalb einer einzelnen Zeile oder Spalte ausgewählt werden sollen. Wenn das Originaldokument zum Beispiel nur vertikale Trennlinien oder Leerzeichen zwischen Einträgen wie Nachnamen und Vornamen enthält, können Sie den Prozess der Tabellenerstellung entsprechend anpassen. Indem Sie Spalten hinzufügen oder weglassen, stellen Sie sicher, dass die Tabellenmodelle das spezifische Layout und die benötigten Informationen erkennen.
Außerdem können sich diese Modelle im Laufe der Zeit an Veränderungen anpassen. Wenn sich die Struktur der Tabellen innerhalb einer Sammlung entwickelt, kann ein zweiter Satz von "Ground Truth"-Daten hinzugefügt werden, um die Tabellenmodelle weiter zu trainieren und so die kontinuierliche Genauigkeit und Nützlichkeit der digitalisierten Daten zu gewährleisten.
Wie geht es weiter?
Da die aktuelle Version der Layout-Erkennung bei komplexeren Layouts einige Herausforderungen aufweist, haben wir dies als Chance gesehen, nicht nur die aktuelle Layout-Analyse zu verbessern, sondern unseren Anwendern eine gezieltere Lösung anzubieten. Mit trainierbaren Layoutmodellen erweitert Transkribus den Einsatz der Layoutanalyse auf unterschiedliche Dokumentenformate und Layouttypen. Die kommenden trainierbaren Tabellenmodelle bieten Flexibilität bei der Anpassung der Layout-Erkennung und können sich an Layout-Änderungen anpassen, um eine genaue Interpretation und umfassende Datenextraktion auch aus Tabellen mit unregelmäßigen Formaten zu gewährleisten.
Das Transkribus Table Models Feature ist bereit, auf einer kleinen Anzahl von Seiten hier auf beta.transkribus.eu. In den nächsten Wochen werden die trainierbaren Tabellenmodelle in unsere Benutzeroberfläche für den allgemeinen Gebrauch aufgenommen. Dieses Update wird es jedem Benutzer ermöglichen, sein eigenes Layoutmodell für Tabellen zu trainieren, was den Prozess der Dokumentendigitalisierung effizienter macht und noch mehr Potenzial innerhalb unserer Plattform freisetzt.
Einige Transkribus-Projekte enden mit einer vollständig digitalisierten Sammlung in Transkribus. Andere nehmen diese digitalisierte Quelle und verwenden sie ...
Wenn man an karolingische (oder karolingische) Minuskeln denkt, kommen einem wahrscheinlich Karl der Große und sein riesiges karolingisches Reich in den Sinn. Während die ...
Das Verstehen historischer Dokumente ist der Schlüssel zum Verständnis der Geschichte. Das Verstehen historischer Dokumente auf Polnisch kann jedoch eine Herausforderung sein. Nicht nur ...
🍪 Einige Cookies für Sie 🍪
Wir verwenden Cookies, um Inhalte und Dienste zu personalisieren und zu verbessern, relevante Werbung zu liefern und die Sicherheit unserer Nutzer zu erhöhen. Sie können Ihre Cookie-Einstellungen jederzeit überprüfen. Weitere Informationen über die Verwendung von Cookies und Cookie-Einstellungen finden Sie in unserem Privacy policy Cookie settingsRejectAccept
Datenschutz & Cookies-Richtlinie
Datenschutz Übersicht
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die als notwendig eingestuften Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der grundlegenden Funktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Ablehnen einiger dieser Cookies kann jedoch Auswirkungen auf Ihr Surferlebnis haben.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Kategorie umfasst nur Cookies, die grundlegende Funktionalitäten und Sicherheitsmerkmale der Website gewährleisten. Diese Cookies speichern keine persönlichen Informationen.
Cookie
Beschreibung
Dauer
viewed_cookie_policy
Das Cookie wird vom GDPR Cookie Consent Plugin gesetzt und dient dazu, zu speichern, ob der Benutzer der Verwendung von Cookies zugestimmt hat oder nicht. Es speichert keine persönlichen Daten.
1 Stunde
PHPSESSID
Dieses Cookie ist in PHP-Anwendungen enthalten. Der Cookie wird verwendet, um die eindeutige Sitzungs-ID eines Benutzers zu speichern und zu identifizieren, um die Benutzersitzung auf der Website zu verwalten. Das Cookie ist ein Sitzungscookie und wird gelöscht, wenn alle Browserfenster geschlossen werden.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Beschreibung
Dauer
BESUCHER_INFO1_LIVE
Dieses Cookie wird von Youtube gesetzt. Wird verwendet, um die Informationen der eingebetteten Youtube-Videos auf einer Website zu verfolgen.
5 Monate
IDE
Wird von Google DoubleClick verwendet und speichert Informationen darüber, wie der Nutzer die Website und andere Werbung vor dem Besuch der Website nutzt. Dies wird verwendet, um Nutzern Anzeigen zu präsentieren, die für sie entsprechend dem Nutzerprofil relevant sind.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Beschreibung
Dauer
GPS
Dieses Cookie wird von Youtube gesetzt und registriert eine eindeutige ID für die Nachverfolgung von Benutzern basierend auf ihrem geografischen Standort
30 Minuten
tk_oder
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
5 Jahre
tk_r3d
Das Cookie wird von JetPack installiert. Wird für die internen Metriken für Benutzeraktivitäten verwendet, um die Benutzererfahrung zu verbessern
3 Tage
tk_lr
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
1 Jahr
_ga
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Besucher-, Sitzungs- und Camapign-Daten zu berechnen und die Nutzung der Website für den Analysebericht der Website zu verfolgen. Die Cookies speichern Informationen anonym und weisen eine zufällig generierte Nummer zu, um eindeutige Besucher zu identifizieren.
2 Jahre
_gid
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Informationen darüber zu speichern, wie Besucher eine Website nutzen, und hilft bei der Erstellung eines Analyseberichts darüber, wie sich die Website verhält. Die gesammelten Daten umfassen die Anzahl der Besucher, die Quelle, von der sie kommen, und die besuchten Seiten in anonymer Form.
1 Tag
matomo
Für die statistische Analyse verwenden wir auf dieser Website "Matomo". Dies ist ein Open-Source-Tool für die Webanalyse. Matomo überträgt keine Daten an Server außerhalb der Kontrolle von READ-COOP. Matomo ist deaktiviert, wenn Sie unsere Website besuchen. Nur wenn Sie aktiv zustimmen, wird Ihr Nutzungsverhalten anonymisiert erfasst.
1 Jahr
Hubspot
Hubspot, Inc. 25 First Street, Cambridge, MA 02141 USA
HubSpot ist ein Dienst zur Verwaltung von Benutzerdatenbanken, der von HubSpot, Inc. bereitgestellt wird. Wir verwenden HubSpot auf dieser Website für unsere Online-Kundensupport-Aktivitäten.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Beschreibung
Dauer
YSC
Dieses Cookie wird von Youtube gesetzt und dient dazu, die Aufrufe von eingebetteten Videos zu verfolgen.
1 Jahr
_gat
Dieses Cookie wird von Google Universal Analytics installiert, um die Abfragerate zu drosseln und so die Datensammlung auf stark frequentierten Seiten zu begrenzen.