Einer der größten Vorteile von Transkribus ist die Möglichkeit Trainieren eines benutzerdefinierten Modells zur Erkennung von handgeschriebenem Texts. Diese einzigartige Funktion ermöglicht es Ihnen, die automatische Transkription auf die spezifische Handschrift oder den gedruckten Text in Ihren Dokumenten abzustimmen, was zu genaueren Transkriptionen führt.
Das Trainieren genauer Modelle ist jedoch eine Fähigkeit, für die man etwas Zeit braucht. Wenn Sie neu in der Modellschulung sind, können Sie schnell frustriert sein über die hohe Zeichenfehlerrate (CER) Ihres Modells. Dies ist eine Zahl zwischen 0% und 100%, die angibt, wie genau das Modell ist. Ein Modell mit einer CER von 100% wird eine sehr ungenaue Transkription erzeugen, während ein Modell mit einer CER von 0% eine perfekte, fehlerfreie Transkription liefert.
Im Allgemeinen sollten Sie einen CER von 10% oder weniger anstreben. Dies führt zu Transkriptionen, die für Suchzwecke und weitere Analysen genau genug sind. Wenn der CER-Wert Ihres Modells jedoch höher ist, brauchen Sie nicht zu verzweifeln - es gibt viele einfache Möglichkeiten, den CER-Wert zu senken und ein Modell zu erstellen, das gut zu Ihren Dokumenten passt. Werfen wir einen Blick auf die fünf einfachsten Möglichkeiten zur Verbesserung des CER Ihres Modells.
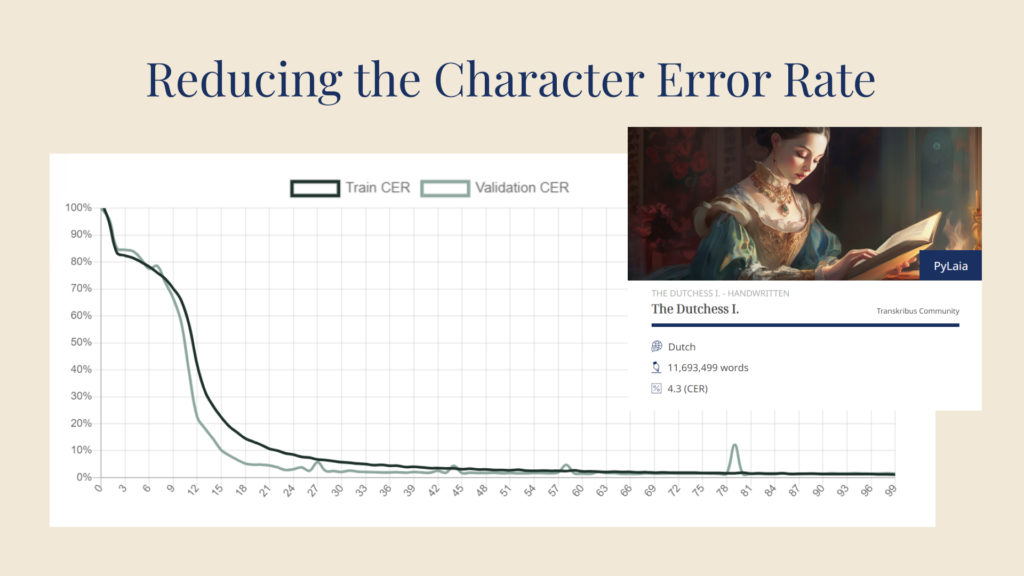
Die CER wird für jedes Modell zusammen mit der Sprache und der Schrift angezeigt. Bild über Transkribus.
Was ist die CER?
Bevor wir beginnen, lassen Sie uns einen kurzen Blick darauf werfen, was der CER ist. Der CER ist der Prozentsatz der Zeichen, die während des Tests vom Texterkennungsmodell falsch transkribiert wurden. Wenn ein Modell einen CER von 5% hat, bedeutet dies, dass im Vergleich zur manuellen Transkription 5 von 100 Zeichen vom Modell falsch transkribiert wurden - eine relativ niedrige Zahl.
Aber wie wird der CER berechnet? Wenn Sie ein Modell erstellen, müssen Sie zwei Sätze genauer, manuell transkribierter Seiten bereitstellen: den Trainingssatz, der zum Trainieren des Modells verwendet wird, und den Validierungssatz, der in der Regel eine Auswahl von Seiten aus dem Trainingssatz enthält und zum Testen des Modells verwendet wird. Diese Trainingsdaten werden auch als Ground Truth bezeichnet.
Während des Trainings analysiert das Modell alle Seiten des Trainingssatzes und versucht, die Handschrift zu lernen. Anschließend testet es, was es gelernt hat, indem es versucht, die Seiten des Validierungssatzes automatisch zu transkribieren. Die automatische Transkription der Seiten durch das Modell wird mit der genauen manuellen Transkription verglichen, und die Anzahl der Fehler wird berechnet. Diese wird dann in einen Prozentsatz umgewandelt und Sie erhalten Ihre CER.
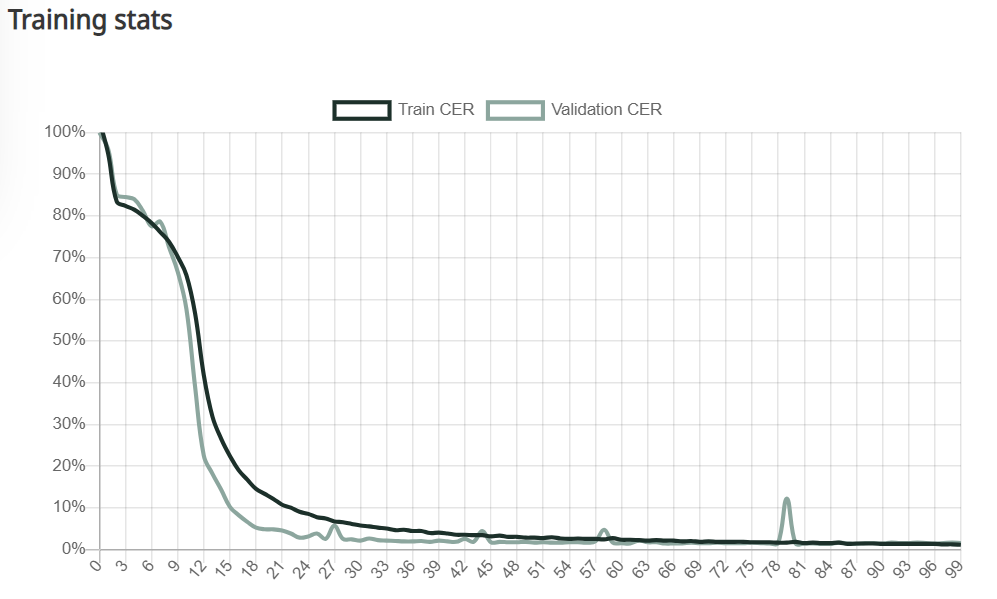
Je mehr Epochen (auf der x-Achse) durchgeführt werden, desto niedriger wird der CER (auf der y-Achse). Bild über Transkribus.
Wenn Ihr Modell diesen Prozess zum ersten Mal durchläuft - was als Epoche bezeichnet wird - können Sie davon ausgehen, dass Ihr CER recht hoch ist. Das Modell wird dann jedoch viele weitere Epochen durchlaufen, wobei es jedes Mal mehr und mehr lernt und immer weniger Fehler macht, wenn es sich selbst auf der Validierungsmenge testet. Mit der Zeit wird das Modell alles gelernt haben, was es kann, und jede Epoche wird den gleichen CER ergeben. Diese Zahl wird als der CER Ihres Modells betrachtet.
Noch eine Sache...
Bedenken Sie, dass der CER jede winzige Abweichung von den Trainingsdaten als Fehler berechnet, einschließlich Leerzeichen, Satzzeichen und Klein- statt Großbuchstaben. Es könnte sein, dass Ihr Modell einen hohen CER-Wert hat, die meisten Fehler aber nicht die eigentlichen Buchstaben betreffen und die Transkriptionen eigentlich recht genau sind. Daher lohnt es sich immer, das Modell nach dem Training an einigen Seiten zu testen, denn auch ein Modell mit einem höheren CER könnte Ihnen einen für Ihre Zwecke geeigneten durchsuchbaren Text liefern.
Fünf Möglichkeiten zur Verbesserung der CER für Ihr Modell
Wenn Ihr Modell viele Trainingsepochen absolviert hat und Sie immer noch einen recht hohen CER und ungenaue Transkriptionen erhalten, finden Sie hier fünf Dinge, die Sie tun können, um die Genauigkeit Ihres Modells zu verbessern.
1. Stellen Sie sicher, dass Ihre Schulungsdaten korrekt sind.
Ihre Trainingsdaten sind die manuell transkribierten Seiten, die Sie für Ihren Trainings- und Validierungssatz bereitstellen. Sie sollten 100% genau und völlig fehlerfrei sein.
Das ist wichtig, denn das Modell ist nur so genau wie die Trainingsdaten, die es erhalten hat. Wenn die Trainingsdaten Fehler enthalten, dann werden diese Fehler in allen Daten, die das Modell zu transkribieren versucht, reproduziert. Wenn Sie sehr hohe CERs erhalten, lohnt es sich, Ihre Trainingsdaten durchzugehen und zu überprüfen, ob sie so genau wie möglich sind.
Je genauer Ihre Trainingsdaten sind, desto genauer wird Ihr Modell sein. Bild aus NAF Court Records, über Transkribus
2. Stellen Sie sicher, dass Ihre Trainingsdaten konsistent sind.
Ebenso sollten Ihre Trainingsdaten konsistent sein. Dies ist besonders wichtig, wenn Ihre Dokumente Abkürzungen, ungewöhnliche Zeichensetzung oder andere "nicht standardisierte" Sprachelemente enthalten. Wenn diese Art von Elementen in den Trainingsdaten nicht einheitlich transkribiert werden, besteht die Gefahr, dass das Modell verwirrt wird, was zu einem höheren CER führt.
Besuchen Sie unser Hilfe-Center für weitere Informationen zur Konsistenz mit Ihren Trainingsdaten.
Durch die konsequente Einhaltung von Transkriptionskonventionen lernt Ihr Modell, auf dieselbe Weise zu transkribieren. Bild aus dem Tagebuch von Marjory Fleming, via Transkribus
3. Vergessen Sie die Grundlinien nicht.
Es ist zwar leicht, sich nur auf den Textteil der Transkription zu konzentrieren, aber vergessen Sie nicht das Layout. Vor jeder Texterkennung führt Transkribus eine Layout-Analyse durch. Auf diese Weise kann die Plattform die Position des Textes auf der Seite bestimmen, so dass sie weiß, was während der Texterkennung zu transkribieren ist.
Daher ist es wichtig, dass die Grundlinien (die farbigen Linien unter jeder Textzeile) in Ihren Trainingsdaten genau dargestellt sind. Auf diese Weise wird das Modell nur versuchen, Zeichen an den Stellen zu finden, an denen sie auch tatsächlich vorhanden sind, was zu genaueren Transkriptionen führt. Wie Sie die Grundlinien anpassen können, erfahren Sie in unserem Hilfe-Center.
Genaue Basislinien stellen sicher, dass das Modell korrekt lernt, wo sich der Text auf der Seite befindet. Bild aus "Bulliot, Bibracte und ich" Projekt, über Transkribus
4. Fügen Sie weitere Daten hinzu.
Wenn Sie Ihre Trainingsdaten durchgesehen haben und sicher sind, dass der Text und die Grundlinien völlig korrekt und konsistent sind, dann wäre der nächste Schritt, weitere Trainingsdaten hinzuzufügen.
Im Allgemeinen empfehlen wir, mindestens 25 Seiten an Trainingsdaten für ein Modell zu haben. Aber natürlich gilt: Je mehr Trainingsdaten Sie haben, desto mehr Informationen hat Ihr Modell zum Lernen und desto genauer wird es.
Dies gilt insbesondere dann, wenn Ihre Dokumente sehr heterogen sind, z. B. wenn sie viele verschiedene Arten von Handschriften aufweisen. In diesen Fällen können mehr Trainingsdaten erforderlich sein, um den CER des Modells zu senken.
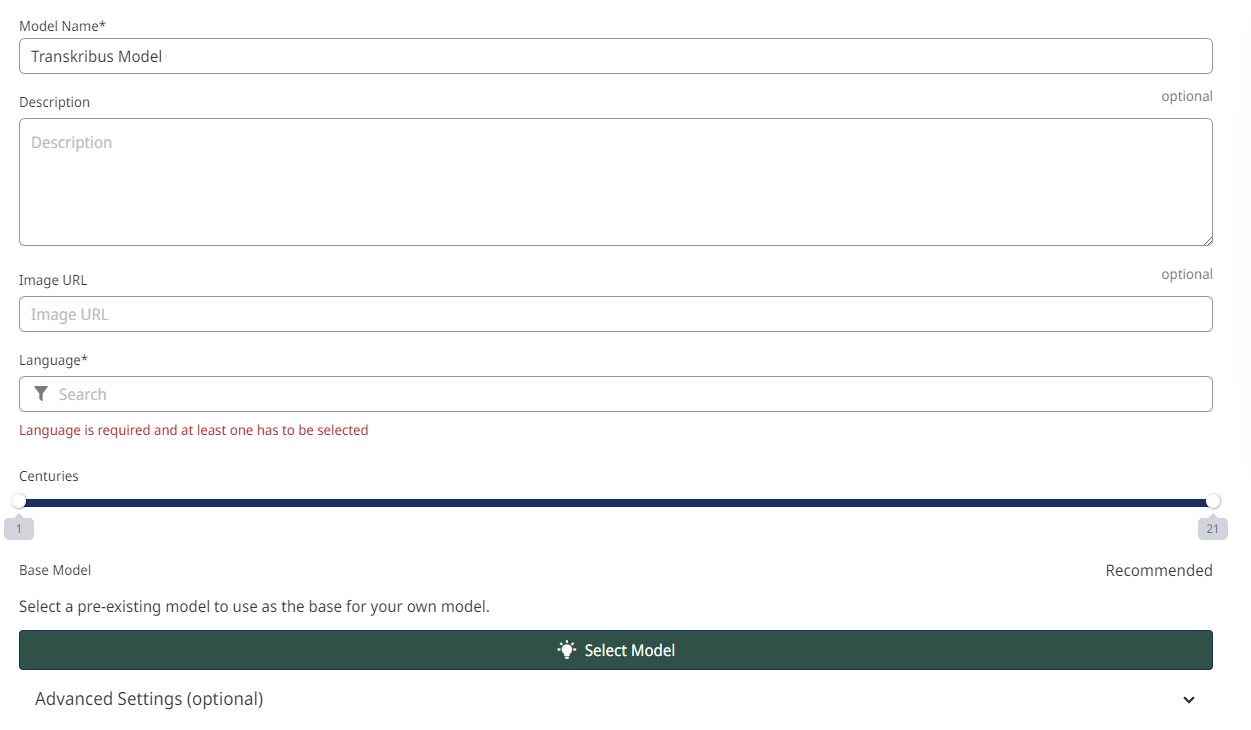
Die Auswahl eines Basismodells bedeutet, dass Ihr neues Modell nicht von Grund auf neu trainiert werden muss. Bild über Transkribus.
5. Verwenden Sie ein Basismodell.
Dieser letzte Tipp kann nicht nur die CER Ihres Modells verbessern, sondern auch Zeit sparen. Beim Einrichten Ihres neuen Modells haben Sie die Möglichkeit, ein "Basismodell" auszuwählen. Dabei handelt es sich um ein bereits vorhandenes Modell, das als Grundlage für Ihr neues benutzerdefiniertes Modell verwendet wird. Ihr Basismodell sollte auf eine ähnliche Sprache, Handschrift und einen ähnlichen Zeitraum wie Ihre Dokumente trainiert sein.
Die Verwendung eines Basismodells bedeutet, dass Ihr neues Modell nicht von Grund auf neu trainiert werden muss. Stattdessen kann es die im Basismodell gespeicherten Informationen nutzen und sie mit Ihren Trainingsdaten erweitern. Dies führt in der Regel zu einem genaueren Modell, für das weniger Trainingsdaten erforderlich sind, was Ihnen Zeit und Mühe erspart.
Benötigen Sie weitere Informationen zum Training von Texterkennungsmodellen mit Transkribus? Sehen Sie sich den Abschnitt Training von Modellen in unserem Hilfe-Center.
Einige Transkribus-Projekte enden mit einer vollständig digitalisierten Sammlung in Transkribus. Andere nehmen diese digitalisierte Quelle und verwenden sie ...
Wenn man an karolingische (oder karolingische) Minuskeln denkt, kommen einem wahrscheinlich Karl der Große und sein riesiges karolingisches Reich in den Sinn. Während die ...
Das Verstehen historischer Dokumente ist der Schlüssel zum Verständnis der Geschichte. Das Verstehen historischer Dokumente auf Polnisch kann jedoch eine Herausforderung sein. Nicht nur ...
🍪 Einige Cookies für Sie 🍪
Wir verwenden Cookies, um Inhalte und Dienste zu personalisieren und zu verbessern, relevante Werbung zu liefern und die Sicherheit unserer Nutzer zu erhöhen. Sie können Ihre Cookie-Einstellungen jederzeit überprüfen. Weitere Informationen über die Verwendung von Cookies und Cookie-Einstellungen finden Sie in unserem Privacy policy Cookie settingsRejectAccept
Datenschutz & Cookies-Richtlinie
Datenschutz Übersicht
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die als notwendig eingestuften Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der grundlegenden Funktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Ablehnen einiger dieser Cookies kann jedoch Auswirkungen auf Ihr Surferlebnis haben.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Kategorie umfasst nur Cookies, die grundlegende Funktionalitäten und Sicherheitsmerkmale der Website gewährleisten. Diese Cookies speichern keine persönlichen Informationen.
Cookie
Beschreibung
Dauer
viewed_cookie_policy
Das Cookie wird vom GDPR Cookie Consent Plugin gesetzt und dient dazu, zu speichern, ob der Benutzer der Verwendung von Cookies zugestimmt hat oder nicht. Es speichert keine persönlichen Daten.
1 Stunde
PHPSESSID
Dieses Cookie ist in PHP-Anwendungen enthalten. Der Cookie wird verwendet, um die eindeutige Sitzungs-ID eines Benutzers zu speichern und zu identifizieren, um die Benutzersitzung auf der Website zu verwalten. Das Cookie ist ein Sitzungscookie und wird gelöscht, wenn alle Browserfenster geschlossen werden.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Beschreibung
Dauer
BESUCHER_INFO1_LIVE
Dieses Cookie wird von Youtube gesetzt. Wird verwendet, um die Informationen der eingebetteten Youtube-Videos auf einer Website zu verfolgen.
5 Monate
IDE
Wird von Google DoubleClick verwendet und speichert Informationen darüber, wie der Nutzer die Website und andere Werbung vor dem Besuch der Website nutzt. Dies wird verwendet, um Nutzern Anzeigen zu präsentieren, die für sie entsprechend dem Nutzerprofil relevant sind.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Beschreibung
Dauer
GPS
Dieses Cookie wird von Youtube gesetzt und registriert eine eindeutige ID für die Nachverfolgung von Benutzern basierend auf ihrem geografischen Standort
30 Minuten
tk_oder
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
5 Jahre
tk_r3d
Das Cookie wird von JetPack installiert. Wird für die internen Metriken für Benutzeraktivitäten verwendet, um die Benutzererfahrung zu verbessern
3 Tage
tk_lr
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
1 Jahr
_ga
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Besucher-, Sitzungs- und Camapign-Daten zu berechnen und die Nutzung der Website für den Analysebericht der Website zu verfolgen. Die Cookies speichern Informationen anonym und weisen eine zufällig generierte Nummer zu, um eindeutige Besucher zu identifizieren.
2 Jahre
_gid
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Informationen darüber zu speichern, wie Besucher eine Website nutzen, und hilft bei der Erstellung eines Analyseberichts darüber, wie sich die Website verhält. Die gesammelten Daten umfassen die Anzahl der Besucher, die Quelle, von der sie kommen, und die besuchten Seiten in anonymer Form.
1 Tag
matomo
Für die statistische Analyse verwenden wir auf dieser Website "Matomo". Dies ist ein Open-Source-Tool für die Webanalyse. Matomo überträgt keine Daten an Server außerhalb der Kontrolle von READ-COOP. Matomo ist deaktiviert, wenn Sie unsere Website besuchen. Nur wenn Sie aktiv zustimmen, wird Ihr Nutzungsverhalten anonymisiert erfasst.
1 Jahr
Hubspot
Hubspot, Inc. 25 First Street, Cambridge, MA 02141 USA
HubSpot ist ein Dienst zur Verwaltung von Benutzerdatenbanken, der von HubSpot, Inc. bereitgestellt wird. Wir verwenden HubSpot auf dieser Website für unsere Online-Kundensupport-Aktivitäten.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Beschreibung
Dauer
YSC
Dieses Cookie wird von Youtube gesetzt und dient dazu, die Aufrufe von eingebetteten Videos zu verfolgen.
1 Jahr
_gat
Dieses Cookie wird von Google Universal Analytics installiert, um die Abfragerate zu drosseln und so die Datensammlung auf stark frequentierten Seiten zu begrenzen.