Create an account with Transkribus and log in to the platform to start working with it
1. Registration
Before accessing Transkribus, you need to register a free Transkribus account.
Sign up for free and verify your email address by clicking the link you will receive via email shortly after. Upon registration you will receive 100 free monthly credits to do some testing and start your project.
If you already have a Transkribus account, you can just go to the next step.
2. Login
Log in to Transkribus using the email address and the password chosen during the registration process. After logging in, you are automatically directed to the Transkribus Desk workspace.
3. User Interface Overview
The web app provides a consistent user experience by grouping tools into organised workspaces that improve navigation through the platform. In brief, the interface can be divided into the following sections:
.png?width=421&height=50&name=Desk%20(1).png)
- Desk: the first of these new work spaces is called Transkribus Desk.
From Home, you have direct access to collections and recent documents, where you can upload your documents and try quick text recognition.
In Collections, you can access your existing collections of historical documents and add new ones. As always, within Collections, you can select entire documents or individual pages for automatic recognition.
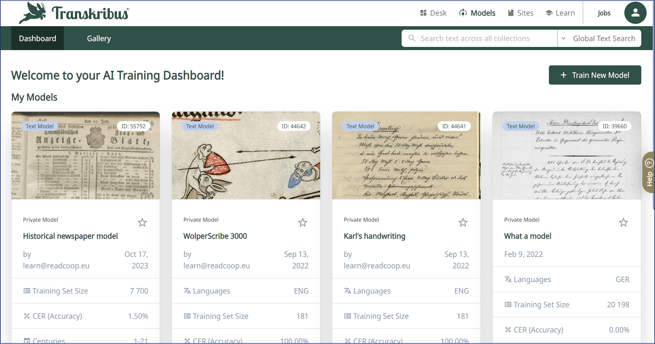
The Tags section gives you an overview of structural or textual tags and allows you to easily search a collection for them. - Models: here you can access your private models via the AI Training Dashboard and also start the training of a new model. In the Gallery you will find an overview of all models that are available for you to use;
- Sites: here you can create your own website to share your collections (depending on your subscription plan. To get started, move to the Sites workspace to set up your own Transkribus Sites website by clicking on "Create New Site" in the top right corner.
- Jobs: opens an overview of all jobs executed with the corresponding account. Each automated task started in Transkribus is carried out as a separate job and can be checked in the Jobs overview. You can also open the Full Jobs Table to get an even more detailed account. If the status of a job shows "Created" or "Running" it means that you successfully started the task and usually, it will be "Finished" soon and you can check out the results by opening the page(s) again.
- User profile: the button on the top right indicates the user profile, where you can manage the user credits, edit the profile information, change the language settings and log out from your account. Regrettably, at the moment, it is not possible to delete your Transkribus account directly from the interface. If you would like to delete your account, kindly reach out to us via info@readcoop.eu or use the Contact us form here in the Help Center.
To update your user profile information, such as your username (i.e. email address) or password, simply click on the user profile button and select "Edit Account".
Not to worry, all your Transkribus data, including collections and trained models, will remain accessible.
Good to know
The Transkribus document editor features a unified text and layout editor view, allowing users to work with the document in a single view, streamlining the document editing process and improving efficiency.
When opening a page, you will see the image and text side by side; use this editor to to transcribe the text or modify layout structure. The sidebars give you the ability to change the view of the editor.
The Settings button in the bottom right corner allows you to:
-
- modify the text font;
- show/hide region and line numbers;
-
- automatically center the selected line in the image;
-
- change the viewing settings of the layout: in particular, you can customise the size, colour and transparency of the lines and scale the circle size.
- change the viewing settings of the layout: in particular, you can customise the size, colour and transparency of the lines and scale the circle size.
Next step: Creating a Collection