How to make a complete collection accessible with Transkribus. A best-practice example from the Tyrolean State Archives
Article by: READ-COOP
From the digitization with the ScanTent, to the use of artificial intelligence for the recognition of the handwritten forms through to the publication of the documents using read&search – with the project “Military Personnel Master Data Sheets” of the Tyrolean State Archives, READ-COOP SCE pulled out all the stops with its Transkribus platform. Now, more than 98,000 files are available to the public. They reflect the fates of around 90,000 young soldiers from the historical region of Tyrol who did their military service in the Austro-Hungarian army in the late 19th century. This unique collection is of great importance for scholars and many family historians and has already been in great demand.
Christoph Haidacher, Director of the Tyrolean State Archives, comments: “For the Tyrolean State Archives, the cooperation with Dr. Günter Mühlberger and READ-COOP SCE offered a unique opportunity to make a collection that is in great demand throughout the European region of Tyrol accessible online, beyond the confines of our reading room, and thus to all interested parties. The availability of selected archive holdings on the worldwide web in conjunction with artificial handwriting recognition means pioneering a path that the Tyrolean State Archives are happy to pursue with its partners.
The project was carried out in several stages: In January and February 2020, the data sheets from South Tyrol and Trentino were scanned, and in February and March 2021, the sheets from North Tyrol were scanned – together, a little more than 98,000 individual scans. Each scan represents the first page of a personnel file.
Registration sheet of the Imperial and Royal Army.
The file usually consists of several sheets, which were bound with staples or adhesive tape. Due to an otherwise much-increased workload, only the file’s first page was digitized in each case. Scans of the remaining pages can be ordered for a small fee within the framework of an on-demand procedure.
Several ScanTents were used for the digitization, usually five to seven students were working at the same time.
Digitisation using ScanTent and smartphone
Using the DocScan app, the pages were scanned and cropped, and immediately uploaded into the Transkribus platform. The naming of the files was done according to the labeling of the original boxes. The entire collection could thus be completely digitized in less than 20 working days.
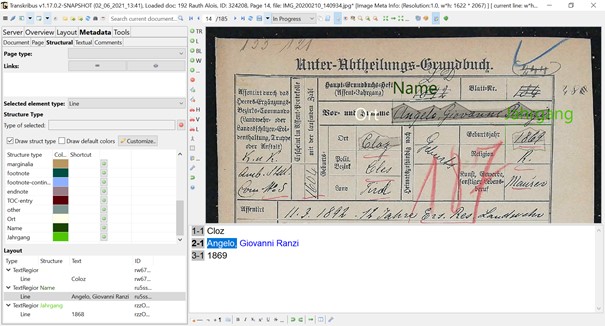
In a further step, a special model was trained to recognize the layout. Here, the P2PaLa tool was used. Since the military personnel master data sheets, “Grundbuchsblätter” in German, are complex forms that have changed over the years and are sometimes very inconsistent, handwriting recognition was deliberately limited to the name, birthplace, and year of birth. These three fields, present in all form types, were trained on several hundred examples. The fields are identified by the software quite reliably, as the following example shows (“Name” = name, “Ort” = (birth-)place, “Jahrgang” = year of birth).
Text and structure recognition with Transkribus
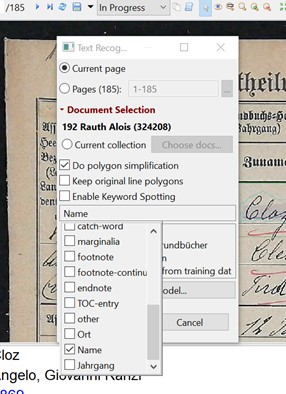
In parallel to creating the layout model, a special handwriting model was trained to recognize the actual family and first names, i.e., the writing within the previously identified “name” fields. For this purpose, the first 10 pages of each document in the South Tyrolean collection were transcribed manually and some documents in their entirety, as training data. Furthermore, name data from other projects, such as the one on the Franciscan Cadastre, were also added, and the general model “Transkribus German Kurrent M2” was used as a base model. Only the name field was recognized with this special model – a feature that is probably still far too little known.
Recognition for a structural field
Transkribus allows different models to be applied to individual structural fields. The two remaining fields, i.e., place of birth and year of birth, were recognized with the standard “German Kurrent M2” model. The recognition quality of about 89% is satisfactory given the rather challenging form fields, the many different font types and writers, and the relatively small set of training data. The automated processing, which was carried out directly in the platform, took several weeks, including waiting times due to the many individual jobs.
The last part then consisted of making the data available using the “read&search” web interface. This process could be completed relatively quickly, as the documents were already in Transkribus and what was left was setting up the according website with the required background images, description texts, fonts, colors etc.
A crowd-sourcing component is to be added to the project in the coming months. Through the “citizen@science” tool, which is currently being developed, interested users will be allowed to volunteer to help correct the recognized text as well as complete the remaining form data, thus significantly enriching this valuable historical resource further.
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.