A collaborative approach: READ-COOP and the Europeana Foundation join forces to enhance the Transcribathon platform
March 15, 2023
Uncategorized
By Fiona Park
Not everyone who works with history is a professional historian. From hobby genealogists to volunteers in local museums, laypeople have always played an important role in keeping history alive. And in the digital age, there is a new way for volunteers to get involved.
The EnrichEuropeana+ project is a citizen science initiative. It brings ordinary people together to work towards a common scientific or academic goal. In the case of Enrich Europeana, this involves creating fully annotated digital versions of the Europeana Collections. To achieve this, volunteers from all over Europe transcribe and enrich handwritten sources using the Transcribathon platform: a custom-made website that allows volunteers to transcribe from home using their normal computer.
In 2021, EnrichEuropeana+ decided to update the Transcribathon platform with new technology and a new look. As the experts in transcription software, READ-COOP were asked to be part of the project, and we gladly accepted. Here is what happened.
Enriching European cultural heritage
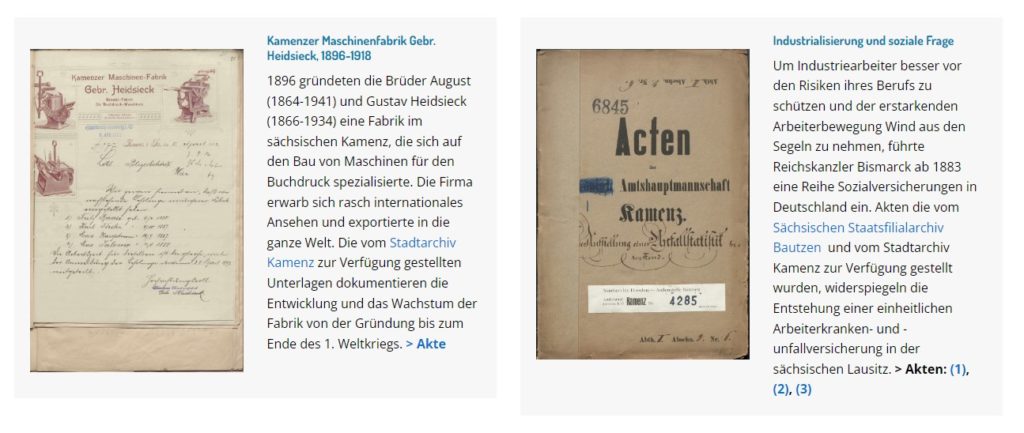
The Europeana project was launched back in 2008. The goal was to preserve pieces of cultural heritage, such as letters, portraits and official documents, from across the continent and make them accessible to the public. This resulted in the Europeana Collections: digital collections of items grouped by topic or time period. For example, if you look at the “Building” collection, you can find a photo of the Manhattan Life Insurance building in New York (housed at the Swedish National Museum of Science and Technology) as well as a newspaper article about the construction of a new student house in Bulgaria (housed at the Pencho Slaveykov Public Library in Varna). By making artefacts like these digitally available, it means everyone can enjoy and learn from them, without having to take a trip to Stockholm or Varna to do so.
But the biggest advantage of digital collections is that they are fully searchable. If a user is looking for newspaper articles about constructions in Bulgaria, they can simply type in those search terms and find what they are looking for much more quickly than they would if searching through a physical collection. The searching process is made possible through metadata — extra information about the artefact that is programmed into its digital version. Metadata isn’t just the title, date and description that you would find in a regular museum but also many other entities such as names and places that are mentioned in the artefact, or tags summarising its content. When the user types in a search term, the collection searches through the metadata of all the items, finds the ones matching the search term and shows the item to the user.
A large citizen science initiative
However, transcribing digital artefacts and enriching them with metadata requires a human being to look at or read through the material, assign tags and other metadata and input these into a computer system. Ideally, the transcription and metadata should also be checked by a second human being, to ensure that everything is inputted correctly. Of course, this takes quite a bit of time, and most museums, libraries, and archives simply don’t have the resources to input transcriptions and metadata themselves.
So Europeana came up with a novel solution to this problem: citizen science. The transcriptions and metadata would be added to the digital artefacts by a team of volunteers, leaving museum staff free to do more specialist work. The volunteers would be trained on how to input the data using their own computer at home, making it possible for anyone around the world to contribute to digitising the Europeana Collections.
A key part of the project is the Europeana Transcribathon platform, where volunteers can view materials, transcribe texts, and enrich them with metadata using just their regular computer at home. Europeana also organise transcription events known as “runs”. Each run has a particular theme, for example, Saxony’s industrial culture or theatrical manuscripts in Portuguese, and a specified time period, usually several days or weeks. During the run, volunteers can transcribe the documents on that theme and often also compete against each other to see who can process the most documents in the time period. While the “winners” often don’t win anything more than the honour of being at the top of the leaderboard, the sense of competition increases volunteers’ motivation and makes the whole event more fun for everyone.
Incorporating Transkribus into Transcribathon
The original Transcribathon platform, which was created in 2016, was a pure transcription editor. Volunteers could manually transcribe text using their computer, but no automatic transcriptions were possible. In 2021, Europeana decided to update the platform with handwriting recognition software. This would mean that volunteers no longer had to do time-consuming manual transcriptions, they could simply proofread an automatic transcription. As proofreading generally takes much less time, volunteers would be able to process more documents in the same amount of time, helping the online collections to expand more rapidly.
The easiest way to create a new digital platform is to base it on something that already exists, and that is exactly what Europeana did. READ-COOP already had a functioning platform for the transcription and enrichment of historical documents (Transkribus) and a way for other platforms to communicate directly with Transkribus (the metagrapho API). This would form the basis of the new Transcribathon platform.
For the uninitiated, an API is a piece of software that acts as a messenger between two different platforms. A user requests information on one platform, and the platform sends this request to the API of another platform. Once this second platform has a response to the request, the API brings it back to the first platform and the person gets the information they need. A good example of this is a flight booking site. A user wants to find out what flights are available between two different cities, so they input a departure airport and destination on a flight booking site. An API then sends this message to a second platform, in this case, the computer system of the airline. This computer system finds the possible flights and the API sends this information back to the flight booking site. The user can then see all the available flights.
The new Transcribathon platform works in a similar way. When a volunteer wants to get an automatic transcription of a text, they request this on the Transcribathon platform. Transcribathon then sends this request to the metagrapho API, which uses handwriting recognition technology to process the image and generate an automatic transcription. Finally, once the processing is complete, the Transcribathon platform can access the transcription and show it to the volunteer, again via the metagrapho API.
Using an existing API in this way meant the Europeana team didn’t have to build their own text recognition system from scratch. They simply had to build a platform that the metagrapho API could interact with, enabling them to access the technology in the main Transkribus platform. This meant that Transkribus’ text recognition technology could be integrated into the platform quite quickly, without too much costly development.
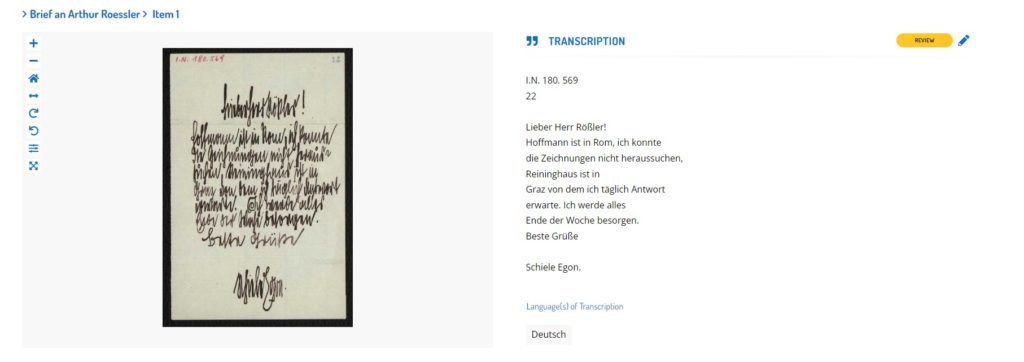
Updating the technology behind Transcribathon meant that the transcription editor — the part a volunteer uses to input or proofread transcriptions — was no longer able to cope with the richer data format that it was receiving back from the metagrapho API. Therefore, it was necessary to build a new transcription editor for Transcribathon. This would, among other things, allow volunteers to click on a line of the transcription, and see the corresponding line in the image of the text.
Again, it was decided to not create a new editor right from scratch. Instead, READ-COOP took the existing editor in the Transkribus software, modified it to fit the requirements of Transcribathon, and turned it into a widget. The widget was then simply inserted into the Transcribathon platform, making it possible for users to access and edit the transcriptions generated by the metagrapho API. Like with the API, using the existing Transkribus editor and simply modifying it also saved precious development time and costs.
In short, by using the existing Transkribus technology, the EnrichEuropeana+ project was able to update the Transcribathon platform much more quickly and efficiently than would have been possible if they had developed everything from scratch. With the metagrapho API and custom transcription editor widget, Transcribathon could take the best of READ-COOP’s technology and modify it to suit the requirements of this unique citizen science project.
And the project has already been a success. The new version of the platform has recently been used for several runs, including the transcription of historical documents in Croatian as well as a multilingual run of 19th-century documents, in which volunteers processed over 1400 documents in just 6 weeks. We look forward to seeing what future collaborations between EnrichEuropeana+ and Transkribus will bring!
Spring has sprung and so has the April 2024 release of Transkribus. Here is a quick overview of all the ...
🍪 Some cookies for you 🍪
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.