+ Gedruckte vs. handgeschriebene Textzeilen - automatisch getrennt
September 26, 2019
Events
Das Transkribus-Team arbeitet mit dem Pattern-Recognition-Team der Universität Erlangen-Nürnberg (ebenfalls Mitglied von READ-COOP SCE) zusammen und die Kollegen waren so nett, ein interessantes Experiment zu machen: ihren Klassifikator zur automatischen Unterscheidung von gedruckten und handgeschriebenen Textzeilen zu trainieren. Es gibt hauptsächlich zwei Anwendungsfälle: (1) zur Verbesserung der Erkennungsergebnisse, wenn bestimmte HTR-Modelle auf bestimmte Schrifttypen angewendet werden. Wir haben jedoch die Erfahrung gemacht, dass die HTR-Engines intern in der Regel recht gut mit einer großen Anzahl von Schriften umgehen können, so dass der tatsächliche Nutzen möglicherweise nicht so hoch ist, wie man erwartet. (2) um handschriftliche Zeilen in gedruckten Büchern zu finden. Wenn z.B. berühmte Personen in ihren privaten Büchern Notizen gemacht haben, wird das unten beschriebene Werkzeug diese mit erstaunlicher Genauigkeit finden!
Der folgende Text wurde von Matthias Seuret und Vincent Christlein von der Pattern Recognition Team und für diesen Beitrag leicht angepasst:
Die Schwierigkeit bei der Klassifizierung von Textzeilen als gedruckt oder handschriftlich liegt nicht so sehr in der Verwendung der Faltungsneuronalen Netze (CNN) oder dem Design ihrer Architektur, sondern in der Erfassung und Aufbereitung der Daten. In der Tat sind moderne künstliche neuronale Netze (ANN) heute in der Lage, mit hochkomplexen Daten umzugehen (wie z. B. ImageNet, das 90 verschiedene Hunderassen zur Unterscheidung enthält), und für eine große Vielfalt von Aufgaben reicht es aus, dem ANN genügend Beispiele zu präsentieren, damit es eine angemessene Genauigkeit erreicht.
Es ist zu beachten, dass ANNs (und andere Systeme der künstlichen Intelligenz) durch die Daten, mit denen sie trainiert werden, extrem verzerrt werden. Aus diesem Grund sollten die Trainingsdaten sorgfältig ausgewählt werden, um sicherzustellen, dass die Aufgabe am einfachsten durch die richtige Klassifizierung der Bilder gelöst werden kann. Wenn zum Beispiel alle (oder die meisten) handgeschriebenen Textzeilen auf einem gelblichen Papier sind, während gedrucktes Material auf weißem Papier ist, dann wird das ANN einfach lernen, gelb von weiß zu trennen, und wird antworten, dass jede Textzeile auf gelblichem Papier handgeschrieben ist. Natürlich kann ein ANN verschiedene andere unerwünschte Dateneigenschaften lernen, wie z. B. die Bildauflösung und -qualität, die Textur des Papiers oder die Farbe oder den Kontrast der Tinte. Daher ist es von größter Bedeutung, Trainingsdaten zu verwenden, die denen, mit denen das ANN zu tun haben wird, so ähnlich wie möglich sind.
Das System, das wir für diese Aufgabe entwickelt haben, basiert auf dem (gedruckten) Schriftgruppenklassifikator, der für das OCR-D-Projekt (http://www.ocr-d.de/). Es besteht aus einem DenseNet-121, das in einige Utility-Klassen verpackt ist, und wurde für die binäre Klassifikation von handgeschriebenem und gedrucktem Text angepasst. Das DenseNet-121 ist ein faltbares neuronales Netz mit 121 Schichten, von denen die meisten in 4 Blöcken dicht verbunden sind. Es hat jedoch eine relativ geringe Anzahl von Parametern für ein Netzwerk seiner Größe und benötigt daher weniger Daten zum Trainieren als Architekturen mit mehr Parametern.
Schema für maschinelles Lernen für gedruckte vs. handschriftliche Textzeilen
Textzeilen werden auf zwei Arten vorverarbeitet. Erstens werden sie alle auf eine Höhe von 150 Pixel verkleinert, und ihr Seitenverhältnis bleibt erhalten. Dies ist für das ANN hilfreich, da es nicht lernen muss, mit einer großen Vielfalt von Textgrößen umzugehen. Zweitens werden Methoden zur Datenanreicherung auf die Trainingsbilder angewendet. Das bedeutet, dass einige kleine Modifikationen, wie z. B. Scherungen oder Farbtonänderungen, auf die Trainingsbilder angewendet werden, wenn sie dem neuronalen Netzwerk während des Trainings gezeigt werden. Das Ziel ist es, dass das Netzwerk lernt, diese Veränderungen zu ignorieren und mit ungesehenen Daten zu arbeiten.
Wir haben unser Netzwerk auf Textzeilen trainiert, die aus zwei verschiedenen Quellen stammen. Ungefähr 40'000 gedruckte Textzeilen wurden automatisch aus dem Datensatz extrahiert, der in "Dataset of Pages from Early Printed Books with Multiple Font Groups" (https://doi.org/10.5281/zenodo.3366685), und 9'577 handschriftliche Proben, die von READ bereitgestellt wurden. Außerdem wurden 1'562 Textzeilen aus jeder Klasse zu Testzwecken verwendet - keine davon stammte von einer Seite, die für die Trainingsdaten verwendet wurde. Während unser Netzwerk bei den Testdaten eine Klassifikationsgenauigkeit von 97,5% erreichte, muss man bedenken, dass dies nur für diese spezifischen Daten gilt. Der Quellcode unserer Methode und des trainierten CNN sowie der Code, mit dem jeder das CNN auf einfache Weise auf seinen eigenen Daten nachtrainieren kann, ist unter der folgenden Adresse verfügbar: https://github.com/seuretm/printed-vs-handwritten
Hinweis: Wenn Sie Interesse haben, Trainingsdaten für diesen Zweck in Transkribus zu erstellen, können Sie die Funktion "Structural Tagging" nutzen und Zeilen in Ihren Dokumenten als "handschriftlich" oder "gedruckt" markieren. Der eigentliche Klassifikator muss außerhalb von Transkribus laufen, allerdings sind wir bei starker Unterstützung durch die Anwendergemeinde gerne bereit, das Tool auch in die Transkribus-Plattform einzubinden.
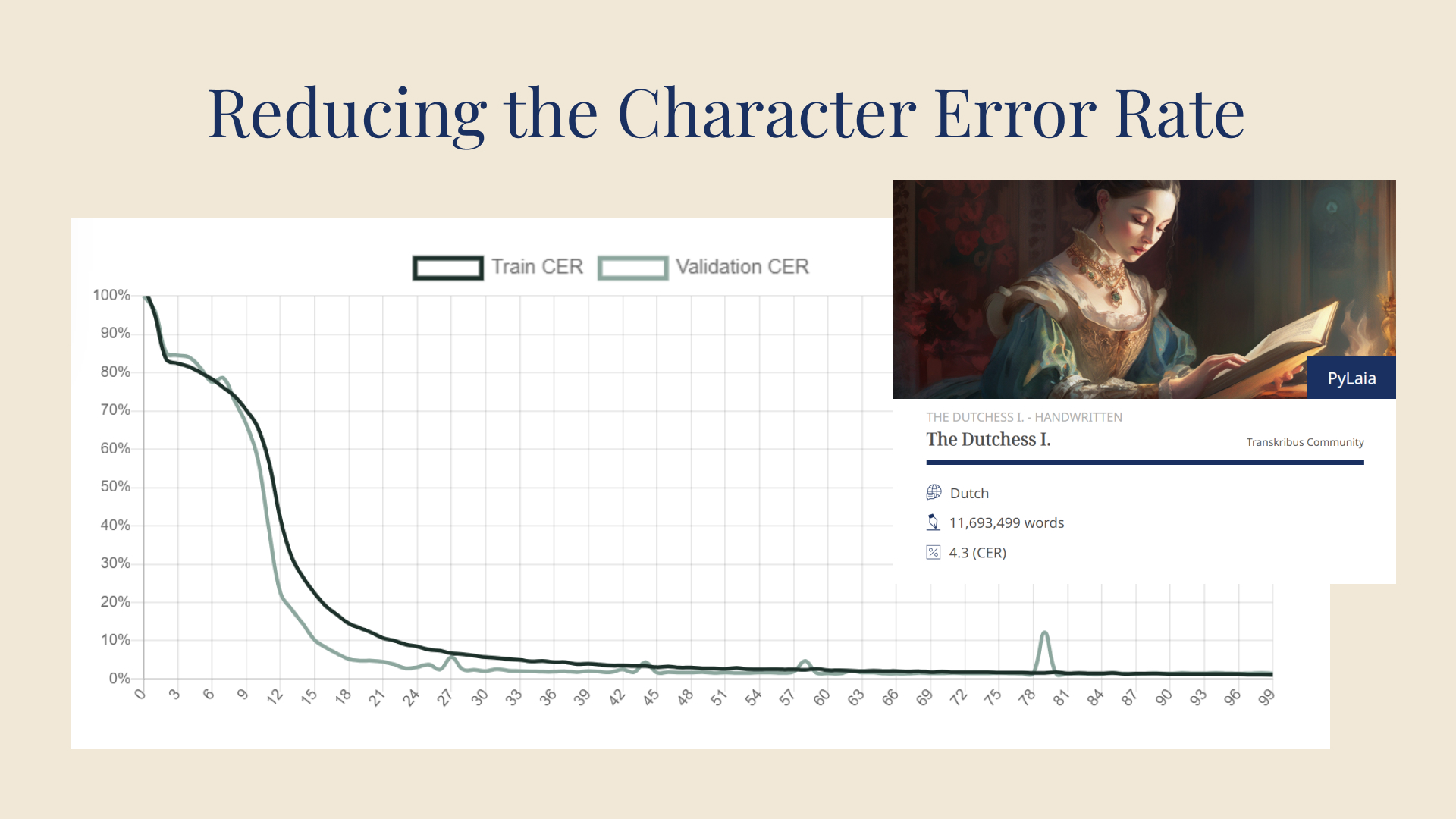
Einer der größten Vorteile von Transkribus ist die Möglichkeit, benutzerdefinierte Modelle zur Erkennung von handschriftlichem Text zu trainieren. Diese einzigartige Funktion ...
Man kann viel über die französische Geschichte lernen, wenn man Bücher liest oder Dokumentarfilme sieht. Diese Arten von Quellen sind gut für ...
🍪 Einige Cookies für Sie 🍪
Wir verwenden Cookies, um Inhalte und Dienste zu personalisieren und zu verbessern, relevante Werbung zu liefern und die Sicherheit unserer Nutzer zu erhöhen. Sie können Ihre Cookie-Einstellungen jederzeit überprüfen. Weitere Informationen über die Verwendung von Cookies und Cookie-Einstellungen finden Sie in unserem Privacy policy Cookie settingsRejectAccept
Datenschutz & Cookies-Richtlinie
Datenschutz Übersicht
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die als notwendig eingestuften Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der grundlegenden Funktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Ablehnen einiger dieser Cookies kann jedoch Auswirkungen auf Ihr Surferlebnis haben.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Kategorie umfasst nur Cookies, die grundlegende Funktionalitäten und Sicherheitsmerkmale der Website gewährleisten. Diese Cookies speichern keine persönlichen Informationen.
Cookie
Beschreibung
Dauer
viewed_cookie_policy
Das Cookie wird vom GDPR Cookie Consent Plugin gesetzt und dient dazu, zu speichern, ob der Benutzer der Verwendung von Cookies zugestimmt hat oder nicht. Es speichert keine persönlichen Daten.
1 Stunde
PHPSESSID
Dieses Cookie ist in PHP-Anwendungen enthalten. Der Cookie wird verwendet, um die eindeutige Sitzungs-ID eines Benutzers zu speichern und zu identifizieren, um die Benutzersitzung auf der Website zu verwalten. Das Cookie ist ein Sitzungscookie und wird gelöscht, wenn alle Browserfenster geschlossen werden.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Beschreibung
Dauer
BESUCHER_INFO1_LIVE
Dieses Cookie wird von Youtube gesetzt. Wird verwendet, um die Informationen der eingebetteten Youtube-Videos auf einer Website zu verfolgen.
5 Monate
IDE
Wird von Google DoubleClick verwendet und speichert Informationen darüber, wie der Nutzer die Website und andere Werbung vor dem Besuch der Website nutzt. Dies wird verwendet, um Nutzern Anzeigen zu präsentieren, die für sie entsprechend dem Nutzerprofil relevant sind.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Beschreibung
Dauer
GPS
Dieses Cookie wird von Youtube gesetzt und registriert eine eindeutige ID für die Nachverfolgung von Benutzern basierend auf ihrem geografischen Standort
30 Minuten
tk_oder
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
5 Jahre
tk_r3d
Das Cookie wird von JetPack installiert. Wird für die internen Metriken für Benutzeraktivitäten verwendet, um die Benutzererfahrung zu verbessern
3 Tage
tk_lr
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
1 Jahr
_ga
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Besucher-, Sitzungs- und Camapign-Daten zu berechnen und die Nutzung der Website für den Analysebericht der Website zu verfolgen. Die Cookies speichern Informationen anonym und weisen eine zufällig generierte Nummer zu, um eindeutige Besucher zu identifizieren.
2 Jahre
_gid
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Informationen darüber zu speichern, wie Besucher eine Website nutzen, und hilft bei der Erstellung eines Analyseberichts darüber, wie sich die Website verhält. Die gesammelten Daten umfassen die Anzahl der Besucher, die Quelle, von der sie kommen, und die besuchten Seiten in anonymer Form.
1 Tag
matomo
Für die statistische Analyse verwenden wir auf dieser Website "Matomo". Dies ist ein Open-Source-Tool für die Webanalyse. Matomo überträgt keine Daten an Server außerhalb der Kontrolle von READ-COOP. Matomo ist deaktiviert, wenn Sie unsere Website besuchen. Nur wenn Sie aktiv zustimmen, wird Ihr Nutzungsverhalten anonymisiert erfasst.
1 Jahr
Hubspot
Hubspot, Inc. 25 First Street, Cambridge, MA 02141 USA
HubSpot ist ein Dienst zur Verwaltung von Benutzerdatenbanken, der von HubSpot, Inc. bereitgestellt wird. Wir verwenden HubSpot auf dieser Website für unsere Online-Kundensupport-Aktivitäten.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Beschreibung
Dauer
YSC
Dieses Cookie wird von Youtube gesetzt und dient dazu, die Aufrufe von eingebetteten Videos zu verfolgen.
1 Jahr
_gat
Dieses Cookie wird von Google Universal Analytics installiert, um die Abfragerate zu drosseln und so die Datensammlung auf stark frequentierten Seiten zu begrenzen.