Wie man eine komplette Sammlung mit Transkribus zugänglich macht. Ein Best-Practice-Beispiel aus dem Tiroler Landesarchiv
Artikel von: READ-COOP
Von der Digitalisierung mit dem ScanTentüber den Einsatz von künstlicher Intelligenz zur Erkennung der handschriftlichen Formulare bis hin zur Veröffentlichung der Dokumente mittels read&search - Mit dem Projekt "Militärische Personalstammblätter" des Tiroler Landesarchivs hat READ-COOP SCE alle Register gezogen mit Transkribus Plattform. Nun sind mehr als 98.000 Akten für die Öffentlichkeit zugänglich. Sie spiegeln die Schicksale von rund 90.000 jungen Soldaten aus der historischen Region Tirol wider, die Ende des 19. Jahrhunderts ihren Militärdienst in der österreichisch-ungarischen Armee leisteten. Diese einzigartige Sammlung ist für Wissenschaftler und viele Familienhistoriker von großer Bedeutung und wurde bereits stark nachgefragt.
Christoph Haidacher, Direktor des Tiroler Landesarchivs, kommentiert: "Für das Tiroler Landesarchiv bot sich durch die Kooperation mit Dr. Günter Mühlberger und READ-COOP SCE die einmalige Chance, eine in der Europaregion Tirol stark nachgefragte Sammlung über die Grenzen unseres Lesesaals hinaus online und damit für alle Interessierten zugänglich zu machen. Die Verfügbarkeit ausgewählter Archivbestände im weltweiten Netz in Verbindung mit künstlicher Handschriftenerkennung bedeutet einen zukunftsweisenden Weg, den das Tiroler Landesarchiv mit seinen Partnern gerne beschreitet.
Das Projekt wurde in mehreren Etappen durchgeführt: Im Januar und Februar 2020 wurden die Datenblätter aus Südtirol und Trentino gescannt, im Februar und März 2021 die Blätter aus Nordtirol - zusammen etwas mehr als 98.000 Einzelscans. Jeder Scan stellt die erste Seite einer Personalakte dar.
Meldebogen der k. u. k. Armee.
Die Akte besteht meist aus mehreren Blättern, die mit Heftklammern oder Klebeband gebunden wurden. Aufgrund eines sonst stark erhöhten Arbeitsaufkommens wurde jeweils nur die erste Seite der Akte digitalisiert. Scans der restlichen Seiten können gegen eine geringe Gebühr im Rahmen eines On-Demand-Verfahrens bestellt werden.
Für die Digitalisierung wurden mehrere ScanTents verwendet, in der Regel arbeiteten fünf bis sieben Studenten gleichzeitig.
Digitalisierung mit ScanTent und Smartphone
Mittels DocScan App wurden die Seiten gescannt, beschnitten und sofort in die Transkribus-Plattform hochgeladen. Die Benennung der Dateien erfolgte entsprechend der Beschriftung der Originalkartons. Die gesamte Sammlung konnte so in weniger als 20 Arbeitstagen komplett digitalisiert werden.
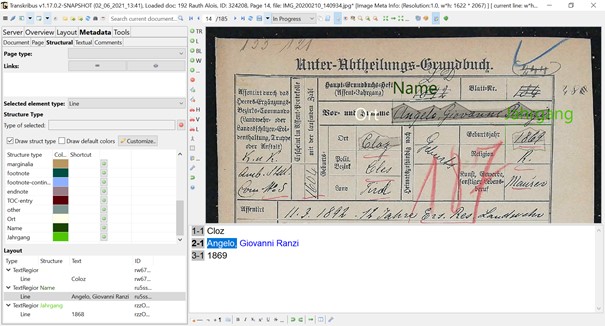
In einem weiteren Schritt wurde ein spezielles Modell zur Erkennung des Layouts trainiert. Hier kam das Tool P2PaLa zum Einsatz. Da es sich bei den militärischen Grundbuchsblättern um komplexe Formulare handelt, die sich im Laufe der Jahre verändert haben und teilweise sehr uneinheitlich sind, wurde die Handschrifterkennung bewusst auf Name, Geburtsort und Geburtsjahr beschränkt. Diese drei Felder, die in allen Formulartypen vorhanden sind, wurden an mehreren hundert Beispielen trainiert. Die Felder werden von der Software recht zuverlässig erkannt, wie das folgende Beispiel zeigt ("Name" = Name, "Ort" = (Geburts-)Ort, "Jahrgang" = Geburtsjahr).
Text- und Strukturerkennung mit Transkribus
Parallel zur Erstellung des Layoutmodells wurde ein spezielles Handschriftenmodell trainiert, um die tatsächlichen Familien- und Vornamen, d.h. die Schrift innerhalb der zuvor identifizierten "Namens"-Felder, zu erkennen. Dazu wurden die ersten 10 Seiten jedes Dokuments der Südtiroler Sammlung manuell transkribiert und einige Dokumente komplett als Trainingsdaten verwendet. Darüber hinaus wurden auch Namensdaten aus anderen Projekten, wie z.B. dem des Franziskaner-Katasters, hinzugefügt und das allgemeine Modell "Transkribus German Kurrent M2" als Basismodell verwendet. Mit diesem speziellen Modell wurde nur das Namensfeld erkannt - eine Eigenschaft, die wahrscheinlich noch viel zu wenig bekannt ist.
Erkennung für ein Strukturfeld
Transkribus erlaubt die Anwendung unterschiedlicher Modelle auf einzelne Strukturfelder. Die beiden verbleibenden Felder, d.h. Geburtsort und Geburtsjahr, wurden mit dem Standardmodell "German Kurrent M2" erkannt. Die Erkennungsqualität von ca. 89% ist in Anbetracht der recht anspruchsvollen Formularfelder, der vielen verschiedenen Schriftarten und -typen und der relativ kleinen Menge an Trainingsdaten zufriedenstellend. Die automatisierte Verarbeitung, die direkt in der Plattform durchgeführt wurde, dauerte mehrere Wochen, inklusive Wartezeiten aufgrund der vielen Einzelaufträge.
Der letzte Teil bestand dann darin, die Daten über die Weboberfläche "read&search" zur Verfügung zu stellen. Dieser Prozess konnte relativ schnell abgeschlossen werden, da die Dokumente bereits in Transkribus vorhanden waren und nur noch die entsprechende Website mit den benötigten Hintergrundbildern, Beschreibungstexten, Schriftarten, Farben etc. eingerichtet werden musste.
In den kommenden Monaten soll das Projekt um eine Crowd-Sourcing-Komponente erweitert werden. Über das in der Entwicklung befindliche Tool "citizen@science" sollen interessierte Nutzer freiwillig bei der Korrektur des erkannten Textes sowie bei der Vervollständigung der restlichen Formulardaten helfen und damit diese wertvolle historische Ressource weiter deutlich bereichern.
Wir verwenden Cookies, um Inhalte und Dienste zu personalisieren und zu verbessern, relevante Werbung zu liefern und die Sicherheit unserer Nutzer zu erhöhen. Sie können Ihre Cookie-Einstellungen jederzeit überprüfen. Weitere Informationen über die Verwendung von Cookies und Cookie-Einstellungen finden Sie in unserem Privacy policy Cookie settingsRejectAccept
Datenschutz & Cookies-Richtlinie
Datenschutz Übersicht
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die als notwendig eingestuften Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der grundlegenden Funktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Ablehnen einiger dieser Cookies kann jedoch Auswirkungen auf Ihr Surferlebnis haben.
Notwendige Cookies sind für das ordnungsgemäße Funktionieren der Website unbedingt erforderlich. Diese Kategorie umfasst nur Cookies, die grundlegende Funktionalitäten und Sicherheitsmerkmale der Website gewährleisten. Diese Cookies speichern keine persönlichen Informationen.
Cookie
Beschreibung
Dauer
viewed_cookie_policy
Das Cookie wird vom GDPR Cookie Consent Plugin gesetzt und dient dazu, zu speichern, ob der Benutzer der Verwendung von Cookies zugestimmt hat oder nicht. Es speichert keine persönlichen Daten.
1 Stunde
PHPSESSID
Dieses Cookie ist in PHP-Anwendungen enthalten. Der Cookie wird verwendet, um die eindeutige Sitzungs-ID eines Benutzers zu speichern und zu identifizieren, um die Benutzersitzung auf der Website zu verwalten. Das Cookie ist ein Sitzungscookie und wird gelöscht, wenn alle Browserfenster geschlossen werden.
Werbe-Cookies werden verwendet, um Besuchern relevante Werbung und Marketing-Kampagnen anzubieten. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um maßgeschneiderte Werbung bereitzustellen.
Cookie
Beschreibung
Dauer
BESUCHER_INFO1_LIVE
Dieses Cookie wird von Youtube gesetzt. Wird verwendet, um die Informationen der eingebetteten Youtube-Videos auf einer Website zu verfolgen.
5 Monate
IDE
Wird von Google DoubleClick verwendet und speichert Informationen darüber, wie der Nutzer die Website und andere Werbung vor dem Besuch der Website nutzt. Dies wird verwendet, um Nutzern Anzeigen zu präsentieren, die für sie entsprechend dem Nutzerprofil relevant sind.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen dabei, Informationen über Metriken wie die Anzahl der Besucher, Absprungrate, Verkehrsquelle usw. zu liefern.
Cookie
Beschreibung
Dauer
GPS
Dieses Cookie wird von Youtube gesetzt und registriert eine eindeutige ID für die Nachverfolgung von Benutzern basierend auf ihrem geografischen Standort
30 Minuten
tk_oder
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
5 Jahre
tk_r3d
Das Cookie wird von JetPack installiert. Wird für die internen Metriken für Benutzeraktivitäten verwendet, um die Benutzererfahrung zu verbessern
3 Tage
tk_lr
Dieses Cookie wird vom JetPack-Plugin auf Websites gesetzt, die WooCommerce verwenden. Dies ist ein Referral-Cookie, das zur Analyse des Referrer-Verhaltens für Jetpack verwendet wird
1 Jahr
_ga
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Besucher-, Sitzungs- und Camapign-Daten zu berechnen und die Nutzung der Website für den Analysebericht der Website zu verfolgen. Die Cookies speichern Informationen anonym und weisen eine zufällig generierte Nummer zu, um eindeutige Besucher zu identifizieren.
2 Jahre
_gid
Dieses Cookie wird von Google Analytics installiert. Das Cookie wird verwendet, um Informationen darüber zu speichern, wie Besucher eine Website nutzen, und hilft bei der Erstellung eines Analyseberichts darüber, wie sich die Website verhält. Die gesammelten Daten umfassen die Anzahl der Besucher, die Quelle, von der sie kommen, und die besuchten Seiten in anonymer Form.
1 Tag
matomo
Für die statistische Analyse verwenden wir auf dieser Website "Matomo". Dies ist ein Open-Source-Tool für die Webanalyse. Matomo überträgt keine Daten an Server außerhalb der Kontrolle von READ-COOP. Matomo ist deaktiviert, wenn Sie unsere Website besuchen. Nur wenn Sie aktiv zustimmen, wird Ihr Nutzungsverhalten anonymisiert erfasst.
1 Jahr
Hubspot
Hubspot, Inc. 25 First Street, Cambridge, MA 02141 USA
HubSpot ist ein Dienst zur Verwaltung von Benutzerdatenbanken, der von HubSpot, Inc. bereitgestellt wird. Wir verwenden HubSpot auf dieser Website für unsere Online-Kundensupport-Aktivitäten.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Cookie
Beschreibung
Dauer
YSC
Dieses Cookie wird von Youtube gesetzt und dient dazu, die Aufrufe von eingebetteten Videos zu verfolgen.
1 Jahr
_gat
Dieses Cookie wird von Google Universal Analytics installiert, um die Abfragerate zu drosseln und so die Datensammlung auf stark frequentierten Seiten zu begrenzen.