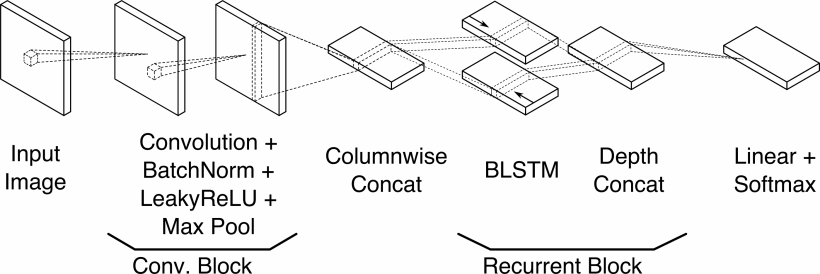
In this article, we will take a closer look at one of the approaches to automated handwritten text-recognition: PyLaia. It is a successor to Laia, built in 2018 by Joan Puigcerver and Carlos Mocholí. In the most simplified description, it takes an image of text as input and generates the corresponding characters as output. At the core of this algorithm lies a deep neural network, but its components are slightly more sophisticated than those of a simple perceptron (see our intro to neural networks here). The entire model architecture is summarised in the image below, but to understand it we first need to take a closer look at some of the biggest advancements in deep learning in the past decade.
The first stage consists of so-called Conv. Blocks, or convolutional blocks. We already talked about these in another article, but let us take a closer look at what is actually happening. In a convolutional layer, the input image is convolved with a kernel, whichis essentially just a matrix of numbers. Since the raw image data can be thought of as a matrix of numeric pixel-values as well, the whole operation of convolution boils down to a huge number of matrix multiplications, where the kernel slides over the entire image – column by column and row by row – to produce a new set of pixel values. In the old days of image processing, people would manually design these kernels to achieve specific tasks, for example edge detection. The kernel below does exactly that: it detects vertical edges by sweeping over all 3×3 pixel sub-images contained in the original image. Traditionally, this could be the first step in a complicated, manually coded algorithm that tries to find objects in an image. However, this used to be so difficult that even the most sophisticated algorithms could not reliably differentiate images of cats and dogs.
Then, approximately 10 years ago, everything changed. The ImageNet project, which runs one of the largest image recognition contests, was suddenly seeing enormous progress among its top contenders. In this contest, algorithms must detect several thousand classes of objects in a dataset that encompasses millions of hand-labelled images. One of the most famous winners, AlexNet, is a deep neural network that gives probability estimates for every single class. It famously managed to correctly classify 63% of all images (i.e. giving the correct class the highest probability) and for nearly 85% of all images, the true class was at least among the top 5 of AlexNet’s predictions. Such numbers were deemed completely impossible just a few years before. So how was this possible? It turned out that you can actually designate kernels as tunable parameters inside a neural network, essentially allowing the model to just learn the right matrices when given sufficient training data.
Self-learned convolutional kernels in the first layer of AlexNet (Krizhevsky et al.)
By using GPU accelerated computing, these kinds of neural networks could suddenly learn in a few hours what humans couldn’t figure out in many decades. Over the next couple of years, the convnet architectures got more and more refined. One big part was the introduction of so-called residual nets, where layer outputs were sometimes bypassing layers only to be fed in again at a later point. This greatly improved training efficiency as networks became deeper and deeper in order to comprehend higher levels of abstraction. Eventually, these developments gave rise to models that could beat average humans in a wide range of image recognition tasks. Today, accurate image classification using convolutional nets is becoming almost trivial. Thanks to modern software libraries and GPU vendors jumping on the bandwagon, image classification can almost be seen as a solved problem. Additionally, thanks to concepts like fine-tuning and transfer learning, it is even possible to solve problems with comparatively tiny amounts of training data. So what are we still trying to achieve when it comes to text recognition? If we only had to deal with pictures of individual letters or numbers, our story would end here. Correctly labelling them is indeed trivial. But handwritten text is more complicated. First of all, there are almost infinitely many handwriting styles and models usually don’t transfer well between texts from different authors. On top of that, even to the trained human eye certain characters might only make sense in the context of a word or perhaps a whole sentence. Thus, to get more accurate HTR predictions, we must go beyond mere image classification and also look at natural language processing. In part 2 of this series, we will take a closer look at the other great advancements in deep learning: recurrent neural networks.
We use cookies to personalize and improve content and services, deliver relevant advertising, and enhance the security of our users. You can check your cookie settings at any time. You can find more information on the use of cookies and cookie settings in our Privacy policy Cookie settingsRejectAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
Duration
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
1 hour
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Description
Duration
VISITOR_INFO1_LIVE
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
5 months
IDE
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Description
Duration
GPS
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
30 minutes
tk_or
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
5 years
tk_r3d
The cookie is installed by JetPack. Used for the internal metrics fo user activities to improve user experience
3 days
tk_lr
This cookie is set by JetPack plugin on sites using WooCommerce. This is a referral cookie used for analyzing referrer behavior for Jetpack
1 year
_ga
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
2 years
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
1 day
matomo
For statistical analysis, we use “Matomo” on this website. This is an open source tool for web analysis. Matomo does not transmit data to servers outside the control of the READ-COOP. Matomo is deactivated when you visit our website. Only if you actively consent will your usage behaviour be recorded anonymously.
1 year
Hubspot
Hubspot, Inc., 25 First Street, Cambridge, MA 02141 USA
HubSpot is a user database management service provided by HubSpot, Inc. We use HubSpot on this website for our online customer support activities.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Description
Duration
YSC
This cookies is set by Youtube and is used to track the views of embedded videos.
1 year
_gat
This cookies is installed by Google Universal Analytics to throttle the request rate to limit the colllection of data on high traffic sites.






{kind=link}